
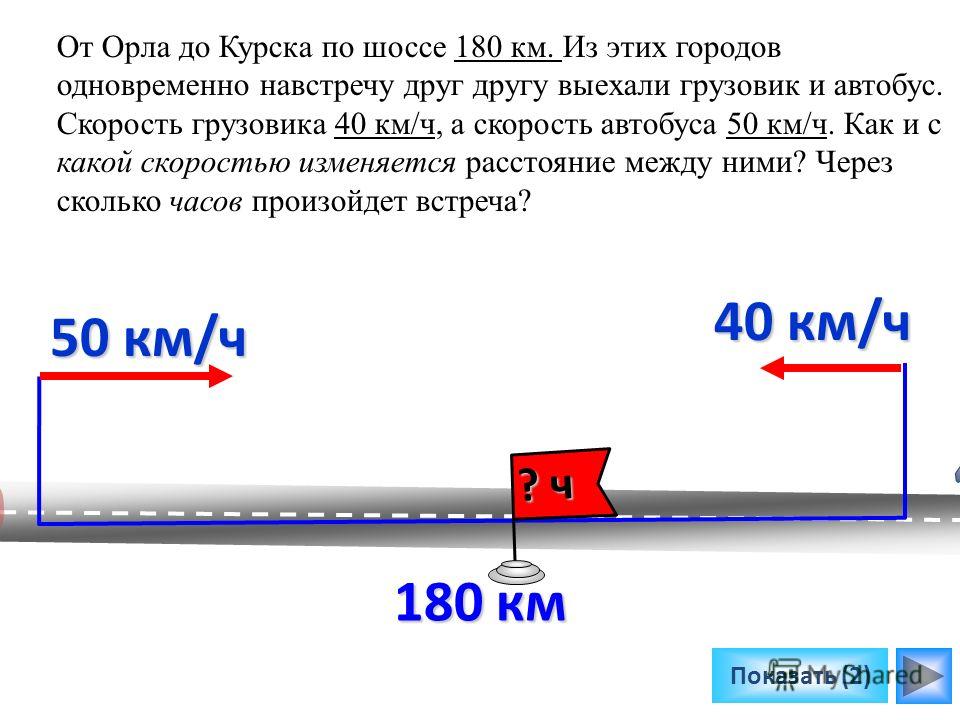
Реши задачу с помощью уравнения из двух городов навстречу друг другу одновременно вышли два поезда. скорость первого-60км/ч,скорость второго-90 км/ч,через сколько часов они встретятся,если расстояние между городами 900 км? — Школьные Знания.net
Все предметы
Математика
Литература
Алгебра
Русский язык
Геометрия
Английский язык
Физика
Биология
Другие предметы
История
Обществознание
Окружающий мир
География
Українська мова
Информатика
Українська література
Қазақ тiлi
Экономика
Музыка
Беларуская мова
Французский язык
Немецкий язык
Психология
Оʻzbek tili
Кыргыз тили
Астрономия
Физкультура и спорт
Из двух городов навстречу друг другу одновременно вышли два поезда. Скорость первого-60км/ч,скорость второго-90 км/ч,через сколько часов они встретятся,если расстояние между городами 900 км?
Скорость первого-60км/ч,скорость второго-90 км/ч,через сколько часов они встретятся,если расстояние между городами 900 км?
Ответ дан
Mastersdda
Ответ:
60x+90x=900
150x=900
x=6
Пошаговое объяснение:
Ответ дан
parus77
Ответ:
они встретятся через 6 часов
Пошаговое объяснение:
пусть они встретятся через Х часов.
скорость сближения поездов — 60+90 (кмч)
тогда по условию сост.уравнение (60+90)*Х=900
150Х=900
х=900:150
х=6 часов
Из двух городов навстречу друг другу вышли два пассажирских поезда. Один поезд ехал со скоростью 64 км/ч, а другой-28 км/ч. Встретились они через 3 часа. Чему равно расстояние между городами?
Последние вопросы
Алгебра
1 минута назад
Алгебра 8 класс ФункцияИстория
6 минут назад
Как долго венгры будут помнить 1956 год?Алгебра
16 минут назад
Помогите, пожалуйста, решить систему уравнений, найти точки пересеченияРусский язык
16 минут назад
Придумает и напишите в тетраду сказку Жила была частица 6 8 предложенийДругие предметы
31 минут назад
Помогите ВПР, Какое число надо вписать в окошко, чтобы равенство стало верным? 819:*число*=63???41 минут назад
N14 решите пожалуйста даю 20 баллов!!! Буду благодарен.
Қазақ тiлi
1 час назад
5 кг метанды жағуға оттектің қандай көлемі (қ.ж.) жұмсалады? Жауабы: 14л Какой объем кислорода (о.с.) требуется чтобы сжечь 5 кг метана? Ответ: 14л Пожалуйста срочно нужно решение и уравнение!История
1 час назад
Дам 100 балів!!! Допоможіть будь ласка!!Алгебра
1 час назад
Найти наибольший и наименьший корень уравненияМатематика
1 час назад
дам100 б решите все плисОбществознание
1 час назад
Помогите срочно с задачейЛитература
1 час назад
Нарисуй в тетради таблицу с двумя колонками. 3п/2*t. Определить величину силы F, действующей на материальную точку, для момента времени t = 0,5 с и полную энергию W точки.Алгебра
2 часа назад
9. x² + (2m — 1)x — m + 1 = 0 если сумма корней (-5) то, x₁²x₂ + x₁x₂² = ? даю 50. баллов помогитеее

 3п/2*t. Определить величину силы F, действующей на материальную точку, для момента времени t = 0,5 с и полную энергию W точки.
3п/2*t. Определить величину силы F, действующей на материальную точку, для момента времени t = 0,5 с и полную энергию W точки.Все предметы
Выберите язык и регион
English
United States
Polski
Polska
Português
Brasil
English
India
Türkçe
Türkiye
English
Philippines
Español
España
Indonesia
Русский
Россия
How much to ban the user?
1 hour 1 day 100 years
Между двумя городами Essential Edition – Stonemaier Games
Между двумя городами: основное издание
- Дизайнеры Бен Россет и Мэтью О’Мэлли
- Художники Лаура Бевон и Агнешка Домбровецка
Сводное издание современной классической градостроительной игры, основанной на партнерстве и построении плиток.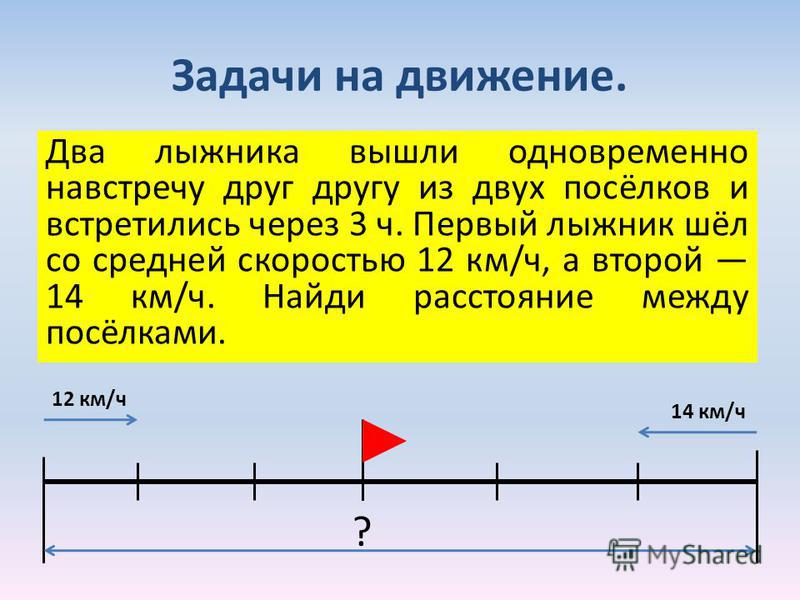
1-7 игроков
30 минут
Чемпион Stonemaier
Станьте чемпионом Stonemaier, чтобы сэкономить 20% на каждом заказе в интернет-магазине.
Между двумя городами — это 30-минутная игра по составлению тайлов для 1–7 игроков, в которой каждый тайл является частью города. Вы работаете с игроком слева от вас, чтобы построить один центр города, одновременно работая с игроком справа, чтобы построить второй центр города. На каждом ходу вы выбираете две плитки из своей руки, открываете их, а затем работаете со своими партнерами, чтобы поместить одну из выбранных плиток в каждый из двух ваших городов.
В конце игры каждый город получает очки за грандиозность своей архитектуры. Ваш окончательный результат равен наименьшему из результатов двух городов, которые вы помогли разработать, и игрок, набравший наибольшее количество очков, побеждает в игре. Чтобы победить, вы должны поровну разделить свое внимание и преданность между двумя городами.
Essential Edition объединяет компоненты оригинальной игры и дополнения Capitals в единое целое. Несмотря на то, что в ней есть большая коробка, чем в оригинальной игре, другое изображение на некоторых плитках и панель для подсчета очков вместо доски, в ней нет новых элементов игрового процесса (т. .
Компоненты
- 1 коробка (296x296x70 мм)
- 2 книги правил (сетевая игра и одиночная игра)
- 129 строительных плиток
- 24 дуплексных плитки
- 7 жетонов городов*
- 7 ландшафтных ковриков
- 1 блокнот
- 7 карт районов (44×67 мм) и 3 плитки
- 20+ одиночных компонентов Automa
* В правилах и на коробке показана шахта Цольферайн, но на самом деле жетон, который оказался в игре, — это Колизей.
СМИ и другая информация
- Группа Facebook
- Между двумя городами отзывы
- BoardGameGeek
- Любимый враг
- Гильдия настольных игр (и Instagram)
- Присоединяйтесь к играм
- Altru No Existe (как играть на испанском)
- Обзор платы
- Beard and Dice (и распаковка)
- Настольный игрок из Монтаньи
- Джокулеску от howtoplay (румынский)
- I Giochi del Topo (итальянский)
- Настольная игра Brothers (голландский)
- Bordspelbros (голландский)
- Настольные игры All Aboard (прохождение)
- Cafe Mais Geek (португальский)
- BoardGameCo
- Блог Brettspiel (немецкий)
Сведения о выпуске: Between Two Cities Essential Edition можно приобрести в центрах исполнения Stonemaier Games в США, Канаде, Европе и Австралии. Дата розничного выпуска — 21 октября 2022 г.
Дата розничного выпуска — 21 октября 2022 г.
Информация о продукте: Цена указана в интернет-магазине. Помимо двух основных художников, Осси Хиеккала проиллюстрировал коробку, а Бет Собел проиллюстрировала пейзаж и настольную графику.
На следующем рисунке показана разница между исходной (верхняя строка) и новой плиткой (нижняя строка):
Copyright 2015 Stonemaier LLC. «Между двумя городами» является торговой маркой компании Stonemaier LLC. Все права защищены. Этот контент не авторизован для публикации в Steam.
Часто задаваемые вопросы: Общие вопросы
Почему я должен сделать предварительный заказ в Stonemaier Games, а не ждать розничной продажи несколько месяцев?
Мы предлагаем доставку намного раньше даты розничного выпуска (отправление из центра выполнения в США, Канаде, Европе или Австралии) и гарантию того, что вы действительно своевременно получите первую копию, поскольку мы продаем только те товары, которые действительно есть в наличии. Мы предложим специальную цену предварительного заказа. Мы также поддерживаем любой выбор сделать заказ у выбранного им розничного продавца в день розничного релиза.
Мы предложим специальную цену предварительного заказа. Мы также поддерживаем любой выбор сделать заказ у выбранного им розничного продавца в день розничного релиза.
Есть ли механические отличия от предыдущей версии?
Джордан Уоттс предлагает хорошее резюме на BoardGameGeek:
- Районы (ранее часть столиц) теперь являются вариантом и не требуются при использовании гражданских плиток и ландшафтных ковриков.
- Магазины изменены с 2/5/10/16 на 1/2/3/4 на 2/5/10/15/20 на 1/2/3/4/5. В правилах Capitals прямо сказано, что «Пять магазинов в очереди дают 18 очков (ряд из четырех магазинов дает 16 очков, а один дополнительный магазин дает 2 очка)».
- Приказ о разрешении конфликтов типов зданий на справочной карте изменен с магазинов, фабрик, таверн, офисов, парков, домов, общественных зданий на фабрики, магазины, парки, таверны, офисы, дома, общественные здания.
- Добавлен новый расширенный вариант для двух игроков , в котором виртуальный третий игрок, «Джейми», выбирает две случайные плитки, а игрок, который получит плитки Джейми следующим (то есть игрок слева в раунде 1 и справа в раунде 3) выбирает, какой город получит какой из них, затем каждый игрок может выбрать расположение всех плиток в городе, который они делят с Джейми. Раунд 2 добавляет предварительный этап, на котором каждый игрок получает две двойные плитки и выбирает одну, чтобы добавить к городу, который они делят с Джейми, прежде чем закончить как обычно.
- Карточки рассадки были удалены.
 Раунд 2 добавляет предварительный этап, на котором каждый игрок получает две двойные плитки и выбирает одну, чтобы добавить к городу, который они делят с Джейми, прежде чем закончить как обычно.
Раунд 2 добавляет предварительный этап, на котором каждый игрок получает две двойные плитки и выбирает одну, чтобы добавить к городу, который они делят с Джейми, прежде чем закончить как обычно.Ошибка на странице 6 правил Автомы?
Да – пример неверный. Вот макет исправленного примера. Единственным элементом, оставшимся за пределами этого макета, являются стрелки, показанные в примере на стр. 6, которые точно такие же.
- Твитнуть
Электронный информационный бюллетень
Поклонники Facebook
 facebook.com/StonemaierGames»> Игры Стоунмайера
facebook.com/StonemaierGames»> Игры СтоунмайераСообщений в блоге
- Первоапрельская неделя дурака: кошачьи открытки, кошачьи рубашки, кошачьи благотворительные организации, кошачьи стратегии и кошачьи коллеги 30 марта 2023 г.
- Текущее состояние игры и победы (2023) 27 марта 2023 г.
- Брене Браун, Уязвимость и 5 критиков 23 марта 2023 г.
- Единое кольцо и чрезвычайная редкость в играх 20 марта 2023 г.
Поиск
Искать:Сказка о двух городах! (Рассказывание историй с использованием данных) | by sudha ahuja
Анализ для сравнения городов с использованием данных Foursquare и машинного обучения
Ключевые слова: наука о данных, машинное обучение, Python, просмотр веб-страниц, Foursquare
Изображение предоставлено: https://www.sussexscenes.co .uk/view-shard-london/https://br.pinterest.com/pin/92816442292506979/ В этом посте рассказывается о методологии и анализе, использованных для финального проекта в рамках курса IBM Data Science Professional . Подробный отчет, код и результаты можно найти на Github, ссылки на которые приведены в конце поста.
Подробный отчет, код и результаты можно найти на Github, ссылки на которые приведены в конце поста.
Выбор города, когда дело доходит до Лондона и Парижа, всегда является трудным решением, поскольку оба эти города являются поистине глобальными, мультикультурными и космополитическими городами, расположенными в сердце двух европейских стран. Помимо того, что они являются двумя наиболее важными дипломатическими центрами Европы, они также являются крупными центрами финансов, торговли, науки, моды, искусства, культуры и гастрономии. И Лондон (столица Соединенного Королевства), и Париж (столица Франции) имеют богатую историю и являются двумя наиболее посещаемыми и востребованными городами Европы. Лондон является крупнейшим городом в Великобритании и стоит на реке Темзе в юго-восточной Англии. Париж, с другой стороны, расположен в северо-центральной части страны. Подобно Лондону, город также стоит вдоль реки, широко известной как река Сена.
Наша цель — сравнить два города, чтобы увидеть, насколько они похожи или непохожи. Такие методы позволяют пользователям идентифицировать похожие районы среди городов на основе удобств или услуг, предлагаемых на местном уровне, и, таким образом, могут помочь в понимании местной деятельности, каковы центры различных видов деятельности, как горожане воспринимают город и как они используют его. его ресурсы.
Такие методы позволяют пользователям идентифицировать похожие районы среди городов на основе удобств или услуг, предлагаемых на местном уровне, и, таким образом, могут помочь в понимании местной деятельности, каковы центры различных видов деятельности, как горожане воспринимают город и как они используют его. его ресурсы.
Какой клиентуре будет полезен такой анализ?
- Потенциальный соискатель с универсальными навыками может пожелать найти работу в выбранных городах, которые наиболее подходят для его квалификации и опыта с точки зрения заработной платы, социальных пособий или даже с точки зрения культуры, подходящей для эмигрантов. .
- Кроме того, человек, покупающий или арендующий дом в новом городе, может захотеть найти рекомендации о местах в городе, похожих на другие известные им города.
- Точно так же крупная корпорация, стремящаяся расширить свое присутствие в других городах, может извлечь выгоду из такого анализа.
- Многие расчеты городского планирования могут также выиграть от моделирования связи города с другими городами.

Для решения поставленной задачи извлечение данных было выполнено следующим образом:
Веб-скрапинг: Данные города были извлечены из соответствующих страниц Википедии [1][2] с использованием библиотек Requests и BeautifulSoup.
## URL для извлечения информации о районе города
urlL = "https://en.wikipedia.org/wiki/List_of_London_boroughs"
urlP = "https://en.wikipedia.org/wiki/Arrondissements_of_Paris"
pageLondon = urllib.request.urlopen(urlL)
pageParis = urllib.request.urlopen(urlP)wikitablesL = read_html(urlL, attrs={" class":"wikitable"})
print ("Извлечено {num} wikitables из Лондонской Википедии".format(num=len(wikitablesL)))
wikitablesP = read_html(urlP, attrs={"class":"wikitable "})
print ("Извлечено {число} викитаблиц из парижской Википедии".
dfL0 = wikitablesL[0]
dfL1 = wikitablesL[1] ## Запрос и ответ
s = запросы.Session()
responseL = s.get(urlL,timeout=10)
 format(num=len(wikitablesP)))dfP = wikitablesP[0]
format(num=len(wikitablesP)))dfP = wikitablesP[0] Дальнейшая очистка данных была выполнена на извлеченные данные для хранения соответствующей информации о его окрестностях, их соответствующих координатах, площади и населении, а также соответствующих номерах районов.
def scrapeLondonTable (таблица):
c1=[]
c2=[]
c3=[]
c4=[]
c5=[]
c6=[]
c7=[]
c8=[]
c9=[]
c10=[]
c11=[]для строки в таблице .findAll("tr"):
ячеекL = row.findAll('td')
if len(cellsL)==10: # Извлекать только тело таблицы без заголовка
c1.append(cellsL[0].find('a').text)
c2 .append(cellsL[1].find(text= True ))
c3.append(cellsL[2].find(text= True ))
c4.
c5.append(cellsL[4].find(text= True ))
c6.append(cellsL[5].find(text= True ))
c7.append(cellsL[6].find(text= True ))
c8.append(cellsL[ 7].find(text= True ))
c9.append(cellsL[8].find('span',{'class': 'geo'}))
c10.append(cellsL[9].find (text= True ))
# создать словарь
d = dict([(x,0) для x в headerL])
# добавить словарь с соответствующим списком данных
d[' Район'] = c1 92
#dfL["Площадь"] = 2,59 * (pd.to_numeric(dfL["Площадь"]))
Широта = []
Долгота = []
для i в диапазоне (len( dfL_table)):
locationSplit = dfL_table['Coordinates'].iloc[i].getText().split("; ")
Latitude.append(locationSplit[0])
Longitude.append(locationSplit[1] )
dfL_table['Широта'] = Широта
dfL_table['Долгота'] = Долгота
dfL_table.
dfL = dfL_table.rename(columns={'Площадь (кв. мили)': 'Площадь', 'Население (оценка 2013 г.)[1]': 'Население',' Номер на карте':'Район Number'})
dfL['Номер округа'] = dfL['Номер округа'].astype(int)
для i в диапазоне (len(dfL)):
dfL['Область'].iloc [i] = float(re.findall(r'[\d\.\d]+', dfL['Область'].iloc[i])[0])
dfL['Население'].iloc[i ] = int(dfL['Population'].iloc[i].replace(',',''))
return dfL
 append(cellsL[3].find(text= True ))
append(cellsL[3].find(text= True ))  drop(['Внутренний','Статус','Местная власть','Политический контроль','Штаб-квартира','Со- ординаты'], ось = 1, на месте = True )
drop(['Внутренний','Статус','Местная власть','Политический контроль','Штаб-квартира','Со- ординаты'], ось = 1, на месте = True ) После необходимой очистки данных мы получаем следующие кадры данных для нашего исследования:
Список районов Лондона. Список районов Парижа (районы 1–4 объединены в 1). Данные о местоположении Foursquare: Foursquare — это социальная служба определения местоположения, которая позволяет пользователям исследовать окружающий мир. API Foursquare предоставляет возможности на основе местоположения с разнообразной информацией о местах проведения, пользователях, фотографиях и регистрациях. Мы воспользовались данными Foursquare для извлечения информации о местах проведения мероприятий для всех исследуемых районов. Вызов API возвращает файл JSON, и нам нужно превратить его в фрейм данных. Затем данные о местоположении использовались для поиска лучших и уникальных мест в каждом районе. Я решил выбрать по 100 самых популярных мест в каждом районе в радиусе 1 км.
API Foursquare предоставляет возможности на основе местоположения с разнообразной информацией о местах проведения, пользователях, фотографиях и регистрациях. Мы воспользовались данными Foursquare для извлечения информации о местах проведения мероприятий для всех исследуемых районов. Вызов API возвращает файл JSON, и нам нужно превратить его в фрейм данных. Затем данные о местоположении использовались для поиска лучших и уникальных мест в каждом районе. Я решил выбрать по 100 самых популярных мест в каждом районе в радиусе 1 км.
Данные города
Данные Википедии предоставили нам информацию о координатах, площади и населении каждого района в соответствующих городах. Эту информацию можно использовать для визуализации карты города с указанием каждого района в соответствии с его плотностью населения. Для визуализации данных на картах-листовках использовались библиотеки «Геокодер» и «фолиум-карта», где районы были отмечены в соответствии с их плотностью населения. Чем выше плотность, тем больше радиус маркера.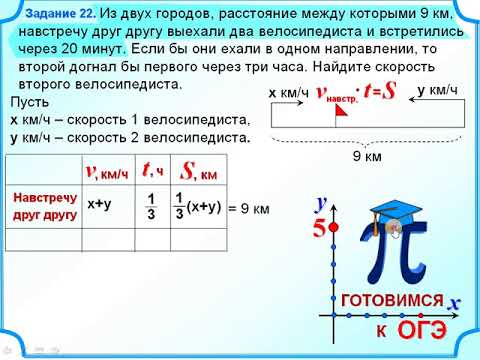
Данные о местах
Данные о местоположении Foursquare предоставили информацию о списке мест в радиусе 1 км от каждого района. Это разумное расстояние, чтобы понять особенности района.
## Извлечение данных об объектах Foursquare
LIMIT = 100 # ограничение количества объектов, возвращаемых API-интерфейсом Foursquare
radius = 1000 # определить радиусdef getNearbyVenues(имена, широты, долготы, радиус=500):
places_list=[]
for name, lattitude28 in 900s , долготы):
print(name)# создайте URL запроса API
url = 'https://api.foursquare.com/v2/venues/explore?&client_id= {} &client_secret= {} &v= {} &ll= {} , {} & RADIUS = {} & Limit = {} '.
Client_ID,
Client_Secret,
,
LAT,
LNG,
Radius,
Litt
results = request.get(url).json()["response"]['groups'][0]['items']# вернуть только релевантную информацию для каждого близлежащего заведения (
имя,
широта,
долгота,
v['место проведения']['имя'],
v['место проведения']['местоположение']['лат'],
v['место проведения']['местоположение']['lng'],
v['место проведения']['категории'][0]['имя']) для v в результатах])near_venues = pd.DataFrame([элемент для места_списка в местах_списка для элемента в места_списка])
near_venues.columns = ['Район',
'Район 2'3, '902 Долгота3' «Место проведения»,
«Широта места проведения»,
«Долгота места проведения»,
«Категория места проведения»]возврат (nearby_venues) print("Получение площадок в следующих районах Лондона:") ]
)
 format (
format ( В общей сложности было около 219 уникальных категорий площадок в Лондоне и 180 в Париже.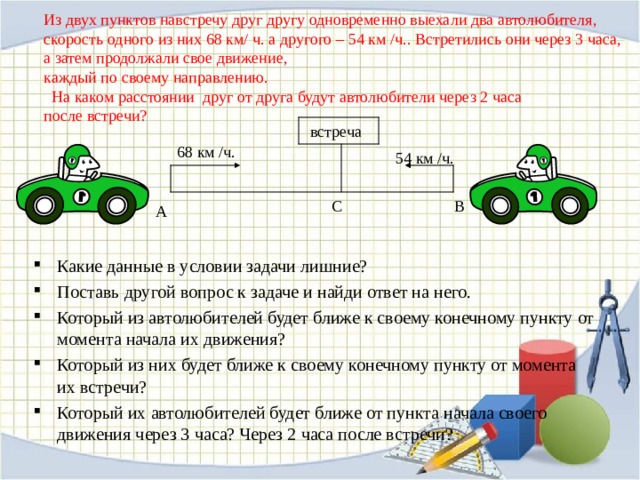 Я использовал эту информацию, чтобы визуализировать наиболее распространенные места в некоторых центральных районах Лондона и Парижа на гистограмме.
Я использовал эту информацию, чтобы визуализировать наиболее распространенные места в некоторых центральных районах Лондона и Парижа на гистограмме.
## Выбор основных районов внутреннего Лондона и Парижа соответственноНаиболее распространенные места для городских районов Лондона (вверху) и Парижа (внизу).
DistrictsL = ['Лондонский Сити','Вестминстер','Кенсингтон и Челси','Хаммерсмит и Фулхэм', 'Вандсворт']
DistrictsP = ['Лувр, Биржа, Темпл, Отель-де-Виль', ' Пантеон», «Люксембург», «Дворец Бурбон», «Елисейский дворец»]def nearvenues_count(venues_df, район):
Venues_count = Venues_df
Venues_count = Venues_count.rename(columns={'Категория объекта': 'Категория' })
места_количества = места_счета.groupby(['Район']).Category.value_counts().to_frame("Количество")
fig, ax = plt.subplots (1,1, figsize = (20, 7))
fig.subplots_adjust (слева = 0,115, справа = 0,88)
места проведения_графика = места проведения_счет ['Количество']. loc [район] [: 10].head(10)
pos = np.arange(len(venues_plot))
ax.
freqchart = ax.barh(pos, Venues_plot,align='center',height=0.5 ,tick_label=venues_plot.index)return freqchart
 set_title(район,размер=20)
set_title(район,размер=20) В то время как наиболее распространенными местами проведения мероприятий в центре Лондона были кафе/кофейни, пабы, фреш-бары или отели, наиболее распространенными местами проведения мероприятий в городских районах в центральных или крупных районах Парижа были в основном французские или итальянские рестораны, а также отели.
Чтобы более подробно изучить данные о месте проведения и в дальнейшем использовать их для анализа, данные места проведения Foursquare были организованы во фрейм данных pandas следующим образом: категорий мест
## Категоризация мест проведения в pandasРаздел данных о местах проведения Foursquare, упорядоченных во фрейме данных pandas для Лондона (слева) и Парижа (справа).
# одно горячее кодирование
London_onehot = pd.# добавить столбец соседства назад to dataframe
London_onehot['Borough'] = London_venues['Borough']# переместить столбец окрестности в первый столбец
fixed_columns = [London_onehot.columns[-1]] + list(London_onehot.columns[:- 1])
London_onehot = London_onehot[fixed_columns]
London_onehot.head ()
London_grouped = London_onehot.groupby('Район'). sort_values(ascending= False )
return row_categories_sorted.index.values[0:num_top_venues]num_top_venues = 10
индикаторы = ['st', 'nd', 'rd']# создать столбцы по номеру лучших площадок
columns = ['Район']
for ind in np.arange(num_top_venues):
try :
columns.append(' {}{} Наиболее распространенное место'.format(ind 1, индикаторы[ind]))
кроме :
columns.# создать новый фрейм данных для Лондона
Londonboroughs_venues_sorted = pd.DataFrame(columns=columns)
Londonboroughs_venues_sorted['Район'] = London_grouped['Район'] для ind в np.arange(London_grouped.shape[0]):
Londonboroughs_venues_sorted.iloc[ind, 1:] = return_most_common_venues(London_grouped.iloc[ind, :], num_top_venues)Londonboroughs_venues_venues(London_grouped.iloc[ind, :], num_top_venues)
Londonboroughs_venues_sorted.iloc )
 get_dummies(London_venues[['Категория места']], prefix="", prefix_sep="")
get_dummies(London_venues[['Категория места']], prefix="", prefix_sep="")  append(' {} th Most Common Venue'.format(ind+1))
append(' {} th Most Common Venue'.format(ind+1)) Информация, содержащая наиболее распространенные данные о местах проведения по районам, затем использовалась для классификации районов на кластеры с использованием « k-средних 9».0052 ’.
Я выполнил кластерный анализ с использованием алгоритма « k-means », чтобы разделить похожие районы на кластеры на основе сходства, обеспечиваемого категориями мест проведения. Чтобы получить некоторое представление, я решил провести некоторое исследование количества кластеров (k), которые будут использоваться следующим образом:
Чтобы получить некоторое представление, я решил провести некоторое исследование количества кластеров (k), которые будут использоваться следующим образом:
Метод локтя: я попытался определить эффективное количество кластеров (k), используя метод локтя для анализа кластеров Лондона. и увидел небольшой излом вокруг k = 6 (хотя и не четкий и резкий). Метод локтя использует внутрикластерную сумму квадратичных ошибок (WSS) для различных значений k, и можно выбрать значение k, при котором WSS начинает уменьшаться и может рассматриваться как локоть на графике WSS-против-k. Однако для парижских данных явного излома не наблюдалось, поэтому я попытался изучить показатель Силуэта для кластеризации для каждого значения k. Значение силуэта измеряет, насколько точка похожа на свой собственный кластер (сплоченность) по сравнению с другими кластерами (разделение). Значение около k = 2 дало глобальный максимум оценки силуэта. Хотя из этих исследований видно, что у нас нет четко сгруппированных данных, я решил разделить районы Лондона на 6 наборов кластеров, а районы Парижа — на 2 набора кластеров для целей нашего анализа. Возможно, было бы полезно изучить более подробный анализ, чтобы оптимизировать k в будущем для таких исследований.
Возможно, было бы полезно изучить более подробный анализ, чтобы оптимизировать k в будущем для таких исследований.
Чтобы решить поставленную бизнес-задачу, мы рассмотрели 33 района внутреннего и внешнего Лондона и 16 районов внутреннего Парижа. Хотя каждый из этих районов может быть уникальным, некоторые из них могут быть более похожими с точки зрения предлагаемых удобств. Для поиска подобных окрестностей был проведен кластерный анализ. Следует отметить, что данные, извлеченные из London Wiki, давали информацию о районах во внутреннем и внешнем Лондоне и, таким образом, учитывали пригородную зону. В то время как данные, предоставленные Paris Wiki, давали информацию только о районах внутри Парижа и не включали много информации о больших пригородах, окружающих Париж, где проживает приличная часть населения. Таким образом, для анализа, проведенного в данном исследовании, потребуется больше информации для сравнения городов на равноправной основе.
Некоторые из выводов, которые были сделаны из объяснительного анализа:
- Большинство районов внутреннего Парижа более густонаселены, чем аналогичные районы внутреннего Лондона. В то время как в Лондоне есть 9 (из 33) районов с плотностью населения более 10 000 человек, только 3 района (из 16) в Париже имеют плотность менее 10 000 человек и 4 района выше 30 000 человек.
- Плотные районы более сконцентрированы во внутренних районах Лондона на карте, чем во внешних регионах, а для Парижа самые густонаселенные районы расположены к северу от реки Сены.
- Первоначальное изучение данных о местах проведения мероприятий Foursquare показало, что кофейни, кафе, пабы и фреш-бары являются наиболее распространенными заведениями в пяти основных районах Лондона. Точно так же французские рестораны, итальянские рестораны и отели были наиболее распространенными местами встречи в пяти основных районах внутреннего Парижа.
 В то время как в Лондоне есть 9 (из 33) районов с плотностью населения более 10 000 человек, только 3 района (из 16) в Париже имеют плотность менее 10 000 человек и 4 района выше 30 000 человек.
В то время как в Лондоне есть 9 (из 33) районов с плотностью населения более 10 000 человек, только 3 района (из 16) в Париже имеют плотность менее 10 000 человек и 4 района выше 30 000 человек. Кроме того, анализ данных о местах проведения с помощью машинного обучения показал, что большинство районов Лондона можно сгруппировать в один кластер. Наиболее распространенными местами встречи в таких районах всегда были кофейни, кафе, пабы, отели или рестораны, за которыми следовали какие-то магазины одежды, круглосуточные магазины или аптеки. Всего Париж был разделен на два отдельных кластера. Хотя наиболее распространенным местом встречи в обоих кластерах всегда был французский ресторан, за ним следовало большое количество итальянских ресторанов, отелей и кафе в первом кластере, а также варианты ресторанов, баров, бистро, магазинов одежды или супермаркетов другой кухни в других кластерах. второй кластер.
Всего Париж был разделен на два отдельных кластера. Хотя наиболее распространенным местом встречи в обоих кластерах всегда был французский ресторан, за ним следовало большое количество итальянских ресторанов, отелей и кафе в первом кластере, а также варианты ресторанов, баров, бистро, магазинов одежды или супермаркетов другой кухни в других кластерах. второй кластер.
Наиболее распространенными типами заведений в любом из городов являются в основном рестораны, кафе, гостиницы, пабы/бары, магазины одежды или парки. Это в некотором роде подчеркивает, насколько города Лондона и Парижа похожи с точки зрения предлагаемых услуг.
Можно дополнительно использовать данные о местах проведения для сравнения городов. Это более комплексный способ, при котором также можно исследовать различные уровни пространственной агрегации, а именно сетки, районы и город в целом. Уровень пространственной агрегации может быть важным фактором при характеристике города с точки зрения его мест проведения.
Некоторые из вопросов, на которые можно ответить с различными уровнями пространственной агрегации, могут быть следующими:
- Как распределяются категории объектов внутри района, т. е. является ли район более жилым или коммерческим.
- В каком городе больше всего объектов инфраструктуры (бары, рестораны, парки, университеты, библиотеки, торговые центры и т. д.)
Подводя итог, можно сказать, что анализ городов с использованием данных Foursquare на основе мест проведения позволяет составить общее представление о тип мест проведения в каждом районе и представлены некоторые ключевые особенности городов, но уровень данных недостаточен для проведения всестороннего анализа для сравнения городов. Для потенциального заинтересованного лица (ищущего работу или человека, решившего переехать в любой из городов) или более крупной клиентуры, такой как бизнес-корпорация или городские планировщики, потребуется провести более подробный анализ, добавив такие характеристики, как арендная плата, заработная плата, транспорт. , стоимость жизни, темпы роста, экономика и т. д.
, стоимость жизни, темпы роста, экономика и т. д.
Проект Capstone предоставил средство для более глубокого понимания того, как работают проекты в области науки о данных в реальной жизни, и какие шаги необходимо предпринять для создания методологии науки о данных. Здесь подробно обсуждались все шаги от понимания бизнес-проблемы, понимания данных до подготовки данных и построения модели. Также были упомянуты многие недостатки текущего анализа и дальнейшие пути его улучшения. Это была первоначальная попытка понять и решить возникшую бизнес-проблему. Тем не менее, по-прежнему существует огромный потенциал для расширения этого проекта в реальных сценариях.
[1] Лондонская Википедия
[2] Парижская Википедия
Обо мне:
Я физик и уже несколько лет анализирую данные физики частиц. За последние несколько лет я переезжал по работе между Карлсруэ, Женевой, Сан-Паулу и Чикаго и в настоящее время проживаю в Париже. Хотя такой анализ данных был бы ступенькой для разработки методологии сравнения любого из городов, сравнение Лондона и Парижа было обусловлено личным выбором любви к этим городам.
Leave A Comment