
Задание 24 ЕГЭ по информатике 2019: практика и теория
Статьи
Среднее общее образование
Информатика
Предлагаем вашему вниманию разбор задания №24 ЕГЭ 2019 года по информатике и ИКТ. Этот материал содержит пояснения и подробный алгоритм решения, а также рекомендации по использованию справочников и пособий, которые могут понадобиться при подготовке к ЕГЭ.29 января 2019
Что нового?
В предстоящем ЕГЭ не появилось никаких изменений по сравнению с прошлым годом.
Возможно, вам также будут интересны демоверсии ЕГЭ по математике и физике.
О нововведениях в экзаменационных вариантах по другим предметам читайте в наших новостях.
ЕГЭ-2020.
Пособие содержит задания, максимально приближенные к реальным, используемым на ЕГЭ, но распределенные по темам в порядке их изучения в 10-11-х классах старшей школы. Работая с книгой, можно последовательно отработать каждую тему, устранить пробелы в знаниях, а также систематизировать изучаемый материал. Такая структура книги поможет эффективнее подготовиться к ЕГЭ.
КупитьИсточник: сайт ФИПИ
Демоверсия КИМ ЕГЭ-2019 по информатике не претерпела никаких изменений по своей структуре по сравнению с 2018 годом. Это значимо упрощает работу педагога и, конечно, уже выстроенный (хочется на это рассчитывать) план подготовки к экзамену обучающегося.
Мы рассмотрим решение предлагаемого проекта (на момент написания статьи – пока еще ПРОЕКТА) КИМ ЕГЭ по информатике.
Часть 2
Для записи ответов на задания этой части (24–27) используйте БЛАНК ОТВЕТОВ № 2.
Запишите сначала номер задания (24, 25 и т. д.), а затем полное решение. Ответы записывайте чётко и разборчиво.
 Запишите сначала номер задания (24, 25 и т. д.), а затем полное решение. Ответы записывайте чётко и разборчиво.
Запишите сначала номер задания (24, 25 и т. д.), а затем полное решение. Ответы записывайте чётко и разборчиво.
Далее не видим необходимости придумывать что-то отличное от официального содержания КИМ демоверсии. Данный документ уже несет в себе «содержание верного ответа и указания по оцениванию», а также «указания для оценивания» и некоторые «примечания для эксперта».
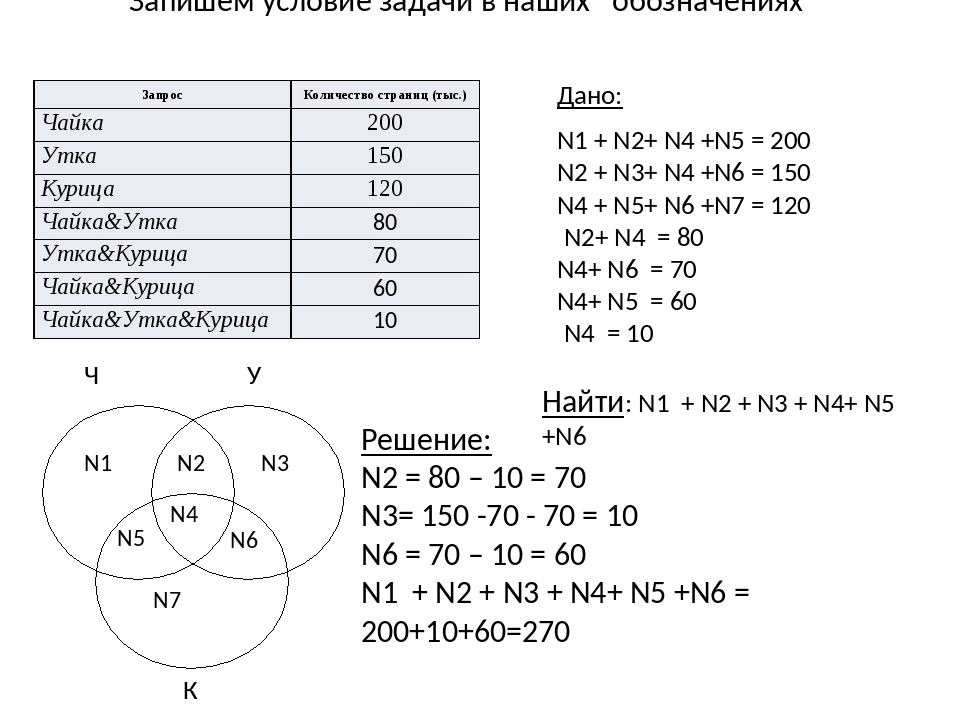
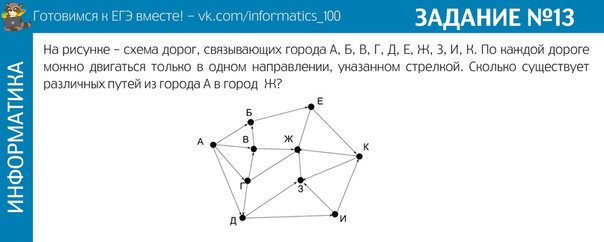
Задание 24
На обработку поступает натуральное число, не превышающее 109. Нужно написать программу, которая выводит на экран минимальную чётную цифру этого числа. Если в числе нет чётных цифр, требуется на экран вывести «NO». Программист написал программу неправильно. Ниже эта программа для Вашего удобства приведена на пяти языках программирования.
Последовательно выполните следующее.
1. Напишите, что выведет эта программа при вводе числа 231.
2.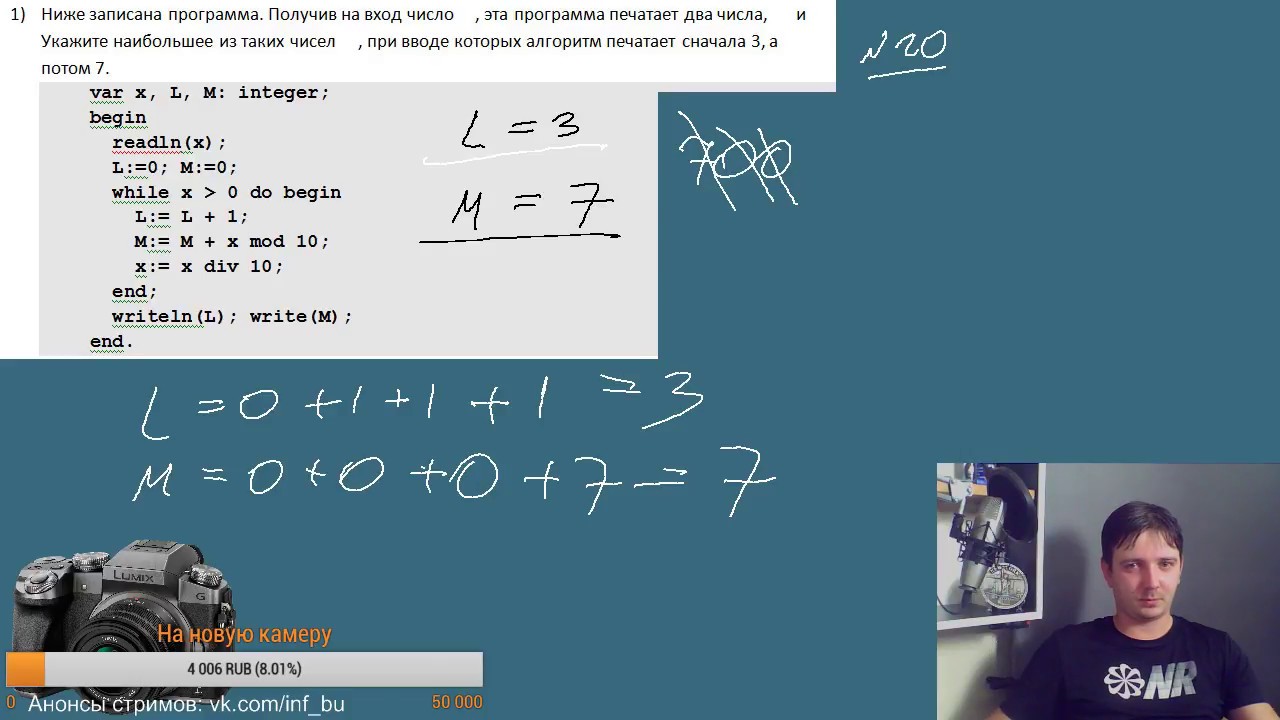 Приведите пример такого трёхзначного числа, при вводе которого приведённая программа, несмотря на ошибки, выдаёт верный ответ.
Приведите пример такого трёхзначного числа, при вводе которого приведённая программа, несмотря на ошибки, выдаёт верный ответ.
3. Найдите допущенные программистом ошибки и исправьте их. Исправление ошибки должно затрагивать только строку, в которой находится ошибка. Для каждой ошибки:
- выпишите строку, в которой сделана ошибка;
- укажите, как исправить ошибку, т.е. приведите правильный вариант строки.
Известно, что в тексте программы можно исправить ровно две строки так, чтобы она стала работать правильно.
Достаточно указать ошибки и способ их исправления для одного языка программирования.
Обратите внимание на то, что требуется найти ошибки в имеющейся программе, а не написать свою, возможно, использующую другой алгоритм решения.
Решение:
|
Содержание верного ответа и указания по оцениванию |
|
Решение использует запись программы на Паскале. 1. Программа выведет число 1. 2. Программа выдаёт правильный ответ, например, для числа 132. Замечание для проверяющего. Программа работает неправильно из-за неверной начальной инициализации и неверной проверки отсутствия чётных цифр. Соответственно, программа будет выдавать верный ответ, если вводимое число не содержит 0, содержит хотя бы одну чётную цифру и наименьшая чётная цифра числа не больше младшей (крайней правой) цифры числа (или просто стоит последней). 3. В программе есть две ошибки. Первая ошибка: неверная инициализация ответа (переменная minDigit). Строка с ошибкой: minDigit := N mod 10; Верное исправление: minDigit := 10;
Вместо 10 может быть использовано любое целое число, большее 8. Вторая ошибка: неверная проверка отсутствия чётных цифр. Строка с ошибкой: if minDigit = 0 then Верное исправление: if minDigit = 10 then Вместо 10 может быть другое число, большее 8, которое было положено в minDigit при исправлении первой ошибки, или проверка, что minDigit > 8 |


|
Указания по оцениванию |
Баллы |
Обратите внимание! В задаче требовалось выполнить четыре действия: 1) указать, что выведет программа при конкретном входном числе; 2) указать пример входного числа, при котором программа выдаёт верный ответ; 3) исправить первую ошибку;
4) исправить вторую ошибку. Для проверки правильности выполнения п. 2) нужно формально выполнить исходную (ошибочную) программу с входными данными, которые указал экзаменуемый, и убедиться в том, что результат, выданный программой, будет таким же, как и для правильной программы. Для действий 3) и 4) ошибка считается исправленной, если выполнены оба следующих условия: а) правильно указана строка с ошибкой; б) указан такой новый вариант строки, что при исправлении другой ошибки получается правильная программа |
|
|
Выполнены все четыре необходимых действия, и ни одна верная строка не указана в качестве ошибочной |
3 |
|
Не выполнены условия, позволяющие поставить 3 балла. а) выполнены три из четырёх необходимых действий. Ни одна верная строка не указана в качестве ошибочной; б) выполнены все четыре необходимых действия. Указано в качестве ошибочной не более одной верной строки |
2 |
|
Не выполнены условия, позволяющие поставить 2 или 3 балла. Выполнены два из четырёх необходимых действия |
1 |
|
Не выполнены условия, позволяющие поставить 1, 2 или 3 балла |
0 |
|
|
3 |

 Имеет место одна из следующих ситуаций:
Имеет место одна из следующих ситуаций:
Решение 23 задания из ЕГЭ по информатике
В 2021 году экзамен по информатике кардинально изменился.
Теория
Задача 23 связана с алгоритмами. Алгоритм — полное и точное описание действий, приводящее к конечному результату. В информатике исходными и выходными данными является информация. Алгоритмы реализуются в компьютерных программах, они должны занимать определенный объем памяти и время. Алгоритм должен быть:
- дискретным (прерывным). Состоит из последовательности простых шагов;
- детерминированным (определенным). В описании операций нет многозначности, исполнитель понимает их и может реализовать;
- массовым. Позволяет решить не одну задачу, а группу аналогичных. В качестве возможных данных используются переменные;
- результативным. Рассматривает все ситуации, дает конечный результат;
- конечным. Имеется определенное количество шагов;
- эффективным. Время выполнения алгоритма позволяет использовать его для реальных задач.
 Состоит из последовательности простых шагов;
Состоит из последовательности простых шагов;Алгоритм делят на базовые элементы (структуры). Структуры бывают трех типов: следование (последовательные действия), ветвление (программа проверяет условие и выбирает один из вариантов действия в зависимости от результата), цикл (несколько действий повторяются многократно). В задании 23 по информатике используются следующие способы записи алгоритмов:
- обычный язык. Текст с разделением на шаги;
- блок-схема. Программа представляется графически, используются специальные блоки:
 Программа представляется графически, используются специальные блоки:
Программа представляется графически, используются специальные блоки: |
Блок |
Обозначение |
|
Начало, конец |
|
|
Ввод, вывод данных |
|
|
Операция |
|
|
Условие |
|
|
Цикл с параметром |
|
|
Обращение к дополнительным алгоритмам |
- Блок
- Обозначение
- Начало, конец
- Ввод, вывод данных
- Операция
- Условие
- Цикл с параметром
- Обращение к дополнительным алгоритмам
- языки программирования. Имеют строгие правила записи, включающие в себя символы и зашифрованные слова;
- псевдокод. Объединение обычного языка и языка программирования. Нет строгих правил, но есть неизменяемые слова, задающие алгоритм. Например, «нач» — начало, «кон» — конец, «рез» — результат.
 Объединение обычного языка и языка программирования. Нет строгих правил, но есть неизменяемые слова, задающие алгоритм. Например, «нач» — начало, «кон» — конец, «рез» — результат.
Объединение обычного языка и языка программирования. Нет строгих правил, но есть неизменяемые слова, задающие алгоритм. Например, «нач» — начало, «кон» — конец, «рез» — результат. Примеры из ЕГЭ
Чтобы хорошо подготовиться к экзамену, нужно решить практические задачи по 23 заданию. Номер основан на динамическом программировании — решении сложных задач путем приведения к более простым. То есть, для выполнения конечного алгоритма нужно разобраться с подзадачами.
Для решения могут применяться графический и табличный способ.
Пример 1. У исполнителя Удвоитель две команды:
1. прибавить 3
2. умножить на 2
Программа для Удвоителя — последовательность команд.
Сколько есть программ, преобразующих число 1 в 25?
Решение. Решим графическим способом. Начнем выполнять с конца. Итоговый результат получается двумя способами — прибавлением к числу Х тройки или умножением числа Y на 2. 25 — нечетное число, вариант с умножением отпадает. Следовательно, перед 25 в алгоритме стояло 25-3=22.
Следовательно, перед 25 в алгоритме стояло 25-3=22.
Число 22 получается и умножением, и сложением. Алгоритм разделяется на 2: в одном число 22:2=11, а в другом 22-3=19. Каждое из этих чисел анализируем по той же схеме. Нужно «разворачивать» алгоритм до тех пор, пока каждая из ветвей не закончится единицей. Рисунок выглядит так:
Ответ: 9.
Пример 2. Исполнитель Вычислитель преобразует число, записанное на экране. У исполнителя есть две команды:
1. прибавить 1
2. умножить на 2
Сколько существует программ, преобразующих исходное число 2 в число 9?
Решение. Воспользуемся таблицей. В этом случае решаем в прямом порядке. В первой строке таблицы записываем все целые числа от исходного до итогового. Во второй пишем число, к которому нужно прибавить 1 для получения цифры из первой строки. В третьей строке аналогично, но с умножением. Четвертая строка — количество разных команд, которые могут привести к получению числа.
|
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
|
|
+1 |
— |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
|
•2 |
— |
— |
2 |
— |
3 |
— |
4 |
— |
|
Кол-во программ |
1 |
1 |
2 |
2 |
3 |
3 |
5 |
5 |
На примере восьмерки:
Ответ: 5.
Итак, мы изучили теорию 23 номера и провели его разбор. Конечно, это непростое задание, и далеко не все могут понять его самостоятельно. Если оно показалось вам сложным, можно записаться на курсы подготовки к ЕГЭ, где о выполнении задач будут рассказывать опытные преподаватели. А мы желаем вам удачи в сдаче ЕГЭ и поступлении в вуз!
DVBogdanov.ru / Подготовка к ЕГЭ по информатике 2018
Поздравляем пользователей сайта с прошедшим Днём Знаний и новым 2018/2019 учебным годом!
Совсем скоро на ege-inf.ru будет опубликован с ответами вариант №1803.
И совсем скоро также на ege-inf.ru будут опубликованы скрипты для тренировки по темам «комбинаторика» и «бизнес-информатика» (пользователи МЭШ смогут воспользоваться аналогичными приложениями).
Приближается новый учебный год и вместе с ним грядут приятные изменения!
Прошлогодние тренировочные варианты №1701 и №1702 получили высокие оценки учеников и учителей, поэтому в 2017/2018 уч. году разработка новых бесплатных вариантов будет продолжена.
Теперь задания будут появляться с периодичностью 4-6 недель, далее 1-2 недели будет работать веб-форма для проверки ответов и, наконец, будут публиковаться официальные ответы на новом сайте
http://ege-inf.ru и в новой группе вКонтакте http://vk.com/informatics_exam.
году разработка новых бесплатных вариантов будет продолжена.
Теперь задания будут появляться с периодичностью 4-6 недель, далее 1-2 недели будет работать веб-форма для проверки ответов и, наконец, будут публиковаться официальные ответы на новом сайте
http://ege-inf.ru и в новой группе вКонтакте http://vk.com/informatics_exam.
Также отличная новость для поклонников С++! Официальный сайт ФИПИ порадовал сообщением, что все программы на С в новом году заменяются на С++. Наши «нестандартные» варианты также будут идти в ногу со временем: в качестве эксперимента планируются задания с программами для современных версий Visual Basic, PascalABC.NET и C++.
Кроме этого, сложность вариантов будет возрастать в течение года. Первый вариант с порядковым номером 0 будет доступен в ближайшие дни. Помимо «стандартных», постепенно будут добавляться задания, соответствующие темам профильного уровня. Это позволит не только лучше закрепить материал, проходимый на уроках, но и подготовиться к олимпиадам.
Кстати, об олимпиадах. Совсем скоро начнётся регистрация участников на некоторые из них. Обзору московских олимпиад будет посвящена ближайшая новость, не пропустите!
Олимпиады и поступление 2018
Не секрет, что участие в олимпиадах – занятие не только увлекательное, но и полезное для поступления в ВУЗ. Например, призёры заключительного тура «ВсеРоса» получают возможность зачисления вне конкурса! А более «реальные» победы в олимпиадах из обширного перечня Министерства образования позволяют (с определёнными оговорками) получить 100 баллов по профильному ЕГЭ. Пригодиться могут и успехи на олимпиадах попроще – в качестве портфолио для баллов за «индивидуальные достижения» (максимум 10 баллов).
Большинство олимпиад по информатике – это олимпиады по программированию и лишь некоторые из них по содержанию близки к заданиям ЕГЭ.
Как правило, первый тур в олимпиадах заочный, а регистрация открывается в начале осени.
Поэтому определяться с выбором нужно как можно скорее.
Читать далее…
Статья К. Ю. Полякова «Множества и логика в задачах ЕГЭ» доступна
по ссылке: http://kpolyakov.spb.ru/download/inf-2015-10.pdf.
#Задачи на алгоритмы #Задачи на кодирование информации #Задачи на комбинаторику #Задачи на логику #Задачи на программирование #Задачи на системы счисления #Задачи на теорию множеств #Подготовка к ЕГЭ по информатике
ЕГЭ по информатике: как сдать на 100 баллов
Менеджер онлайн-маркетплейса для поиска репетиторов Preply Виктория Жукова рассказала, что нужно делать, чтобы получить высокий балл на главном экзамене по информатике.
Сегодня ЕГЭ по информатике является обязательным для поступления в более чем 60 российских ВУЗов. Предмет сдают выпускники, которые собираются учиться на таких специальностях, как ракетные комплексы и космонавтика, информационная безопасность, нанотехнологии, системный анализ и управление.
Спрос на эти специальности растет. Успехи таких личностей, как Илон Маск, Марк Цукерберг и другие гении современности, показывает, что мир нуждается в технических специалистах.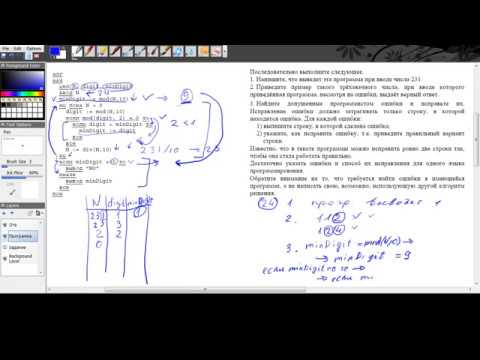 Вместе с бурным развитием технологий приходит и понимание, что владение компьютером на высоком уровне открывает ряд перспектив. Искусственный интеллект, кибербезопасность, программирование — сферы, в которых можно сделать головокружительную карьеру. Но успешная карьера начинается с поступления в университет и сдачи экзаменов. Расскажу, из чего состоит ЕГЭ по информатике, на что обратить внимание, а еще поделюсь секретами, как получить высший балл.
Вместе с бурным развитием технологий приходит и понимание, что владение компьютером на высоком уровне открывает ряд перспектив. Искусственный интеллект, кибербезопасность, программирование — сферы, в которых можно сделать головокружительную карьеру. Но успешная карьера начинается с поступления в университет и сдачи экзаменов. Расскажу, из чего состоит ЕГЭ по информатике, на что обратить внимание, а еще поделюсь секретами, как получить высший балл.
Система оценивания
За каждое выполненное задание выпускнику начисляется так называемый «первичный балл». Чем сложнее задание, тем больше баллов за него можно получить. За правильно выполненное задание дается от одного до четырех баллов.
В конце проверки экзаменационной работы все первичные баллы суммируются и переводятся в тестовый балл. Он и указывается в сертификате ЕГЭ. Минимальный проходной балл для поступления — 40, но стремиться, разумеется, следует к совсем другому результату. На технологических специальностях, для которых требуется сдавать экзамен по информатике, большой конкурс. Кстати, по тестовому баллу можно определить оценку по пятибалльной шкале, которую получил бы школьник: 0-34 балла — «2», 40-55 — «3», 57-72 — «4» и 73-100 — «5».
Кстати, по тестовому баллу можно определить оценку по пятибалльной шкале, которую получил бы школьник: 0-34 балла — «2», 40-55 — «3», 57-72 — «4» и 73-100 — «5».
Структура экзамена
Из всех существующих тестирований на ЕГЭ информатика — один из самых продолжительных: он длится четыре часа (столько же времени занимают ЕГЭ по литературе и математике). В 2018 году тестирование по информатике состоит из двух частей, всего в нем 27 заданий.
Первая часть — задания 1-23 (часть В) — требует лаконичного ответа. По традиции это либо число, либо последовательность букв или цифр. Вторая часть — задания 24-27 (часть С) — тесты, на которых нужно дать развернутый ответ. Часть С включает в себя четыре задачи: написание программы, запись алгоритма, поиск ошибки в программном коде и составление выигрышной стратегии. На втором бланке ответов записывается полное решение этих четырех заданий.
Состав экзамена таков: 20% — теория, 30% — информационные технологии, 50% — программирование и алгоритмизация. Обычно сложность вызывает часть С, и не в последнюю очередь виной тому становится стресс. Поэтому лучше выдохнуть, и спокойно решать задание. И главное — после перепроверить.
Обычно сложность вызывает часть С, и не в последнюю очередь виной тому становится стресс. Поэтому лучше выдохнуть, и спокойно решать задание. И главное — после перепроверить.
Подготовка к экзамену
Необходимые знания, разумеется, уже есть, но этого недостаточно. Важно быть ознакомленным со структурой экзамена, тренироваться решать задачи на время и научиться выполнять задания в формате ЕГЭ. В первую очередь рекомендую скачать демонстрационные варианты по информатике и начать с ними работать за полгода до экзамена. Готовиться нужно без спешки, заполняя пробелы, если они есть, тщательно разбираться в вопросах. Демонстрационные задания — полная аналогия того, что вас ждет на ЕГЭ.
Тренировку лучше разбавлять другими ресурсами:
- Фоксфорд — YouTube-канал с разбором тестов. Подробные и доступные видеоуроки по выполнению заданий. Можно смотреть и одновременно готовиться в любое удобное время.
- Сайт Полякова — материалы для подготовки. Задания разбиты по темам.
- Информатик БУ — YouTube-канал, аналогичный Фоксфорду. Эффективный ресурс с сотнями положительным отзывов выпускников. Просто и понятно.
- Решу ЕГЭ — некоторые задания несколько тяжелее экзаменационных, но, как говорится, тяжело в учении, легко в бою. Вторая часть практически совпадает по сложности с реальными заданиями ЕГЭ.

Полезные лайфхаки
Заданиям под номерами 16, 18 и 23 в школьной программе уделяется слишком мало внимания, а иногда они вообще не рассматриваются. Номера 16 и 18 — это задания повышенного уровня, они для тех, кто претендует на 100 баллов. Задание 16 имеет отношение к разделу «Системы счисления», для него характерны вычислительные ошибки. Задача 18 — преобразование логических выражений. Здесь главное не ошибиться в технике выполнения.
Есть три секрета наивысшего балла. Первый секрет — это труд: нужно много работать, и лучше начать заблаговременно. Второй — обязательное выполнение работы над ошибками, это рекомендация опытных преподавателей.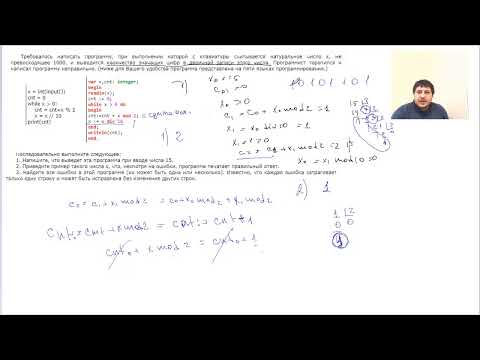 И третий секрет: перед тем, как начать выполнять задание, нужно внимательно прочесть вопрос полностью и несколько раз. Ошибки, допущенные по невнимательности, это очень обидно, особенно если выпускник готов. Поэтому нужно запастись терпением, усидчивостью — и заветные 100 баллов будут ваши.
И третий секрет: перед тем, как начать выполнять задание, нужно внимательно прочесть вопрос полностью и несколько раз. Ошибки, допущенные по невнимательности, это очень обидно, особенно если выпускник готов. Поэтому нужно запастись терпением, усидчивостью — и заветные 100 баллов будут ваши.
Курсы ЕГЭ по информатике подготовка онлайн и в классе
Maximum Education Москва Контакты:Адрес: Подсосенский переулок, д. 23, стр. 2, этаж 3, пом. 1, метро Курская Москва,
Телефон:8 800 775 53 81, Факс:8 800 775 53 81, Электронная почта: Maximum Education Санкт-Петербург Контакты:Адрес: улица Рубинштейна 13, Бизнес Центр «Агат», 4-й этаж Санкт-Петербург,
Телефон:8 (812) 385-52-55 , Факс:8 (812) 385-52-55 , Электронная почта: Maximum Education Бердск Контакты:Адрес: ул. Первомайская д.19 оф.2 Бердск,
Телефон:8 913 985 15 13, Факс:8 913 985 15 13, Электронная почта: Maximum Education Владивосток Контакты: Адрес:
пр. Красного знамени, д.34 Владивосток ,
Красного знамени, д.34 Владивосток ,
Адрес: пр.Коста, 15, оф.1-8 Владикавказ,
Телефон:8 (926) 265-17-16, Факс:8 (926) 265-17-16, Электронная почта: Maximum Education Владимир Контакты:Адрес: Октябрьский пр-кт, д. 7 (ДЦ «Типография», вход номер 4, 4 этаж, башня), офис 417. Владимир,
Телефон:8 (4922) 600-007, Факс:8 (4922) 600-007, Электронная почта: Maximum Education Волгоград Контакты:Адрес: ул. Ткачева, 7 Волгоград,
Телефон:8 (8442) 60-10-97, Факс:8 (8442) 60-10-97, Электронная почта: Maximum Education Воронеж Контакты:Адрес: ул. Карла Маркса 70А Воронеж,
Телефон:8 473 300 30 98, Факс:8 473 300 30 98, Электронная почта: Maximum Education Грозный Контакты: Адрес:
ул. Г. Н. Трошева, д. 7 Грозный,
Г. Н. Трошева, д. 7 Грозный,
Адрес: Ул. Чернышевского, д. 16, эт. 2, метро Площадь 1905 года Екатеринбург,
Телефон:8 (343) 288-58-19, Факс:8 (343) 288-58-19, Электронная почта: Maximum Education Иркутск Контакты:Адрес: Степана Разина 27, оф. 205 Иркутск,
Телефон:8 (3952) 500-131, Факс:8 (3952) 500-131, Электронная почта: Maximum Education Калуга Контакты:Адрес: Бизнес-Центр «Московский», ул.Суворова, 121 Калуга,
Телефон:+7 (484) 220-71-76, Факс:+7 (484) 220-71-76, Электронная почта: [email protected] Education Краснодар Контакты:Адрес: ул. Кожевенная, д. 56 Краснодар,
Телефон:8 (861) 205-34-45, Факс:8 (861) 205-34-45, Электронная почта: Maximum Education Красноярск Контакты: Адрес:
ул. Парижской Коммуны, д. 33, оф. 302 Красноярск,
Парижской Коммуны, д. 33, оф. 302 Красноярск,
Адрес: ул. Леваневского 3, 3й этаж. Махачкала,
Телефон:+7 (928) 599-63-33, Факс:+7 (928) 599-63-33, Электронная почта: Maximum Education Мурманск Контакты:Адрес: ул. Полярные Зори, дом 1, этаж 4 Мурманск,
Телефон:78-77-14, Факс:78-77-14, Электронная почта: Maximum Education Мытищи Контакты:Адрес: Олимпийский пр-кт, вл.13, стр.1. БЦ «Фрегат». Мытищи,
Телефон:8 (499) 322-47-27, Факс:8 (499) 322-47-27, Электронная почта: Maximum Education Назрань Контакты:Адрес: ул. Московская, 33 Назрань,
Телефон:+7 (928) 918-05-65, Факс:+7 (928) 918-05-65, Электронная почта: Maximum Education Нижний Новгород Контакты: Адрес:
м. Горьковская, ул. Костина, д. 3, эт. 4 Нижний Новгород,
Горьковская, ул. Костина, д. 3, эт. 4 Нижний Новгород,
Адрес: м. Площадь Ленина. Ул. Максима Горького 75 Новосибирск,
Телефон:8 (383) 383-26-21, Факс:8 (383) 383-26-21, Электронная почта: Maximum Education Одинцово Контакты:Адрес: Можайское шоссе, д. 71 Одинцово,
Телефон:8 (499) 322-44-36, Факс:8 (499) 322-44-36, Электронная почта: Maximum Education Оренбург Контакты:Адрес: ул. 8 Марта 49 (ТЦ Панорама), офис 204 Оренбург,
Телефон:8 (3532) 37-01-65, Факс:8 (3532) 37-01-65, Электронная почта: Maximum Education Пермь Контакты:Адрес: ул. Советская, 72, 4ый этаж Пермь,
Телефон:8 (342) 207-10-15, Факс:8 (342) 207-10-15, Электронная почта: Maximum Education Подольск Контакты: Адрес:
Г. Подольск, ул. К.Готвальда, 6В, 2эт, 19 павильон Подольск,
Подольск, ул. К.Готвальда, 6В, 2эт, 19 павильон Подольск,
Адрес: ул. Пушкинская, д. 144 Ростов-на-Дону,
Телефон:8 (863) 320-02-15, Факс:8 (863) 320-02-15, Электронная почта: Maximum Education Салехард Контакты:Адрес: undefined Салехард,
Телефон:8 (482) 273-44-18, Факс:8 (482) 273-44-18, Электронная почта: Maximum Education Сочи Контакты:Адрес: ул. Советская, д. 42, 2 этаж, офис 205 Сочи,
Телефон:8 (861) 205-34-45, Факс:8 (861) 205-34-45, Электронная почта: Maximum Education Сургут Контакты:Адрес: ул. Маяковского, дом 9/1 Сургут,
Телефон:8 (3462) 550-812, Факс:8 (3462) 550-812, Электронная почта: Maximum Education Тверь Контакты: Адрес:
ул. Советская 36 Тверь,
Советская 36 Тверь,
Адрес: ул. Фрунзе, 8, офис 1010 (10 этаж) Тольятти,
Телефон:8 (927) 768-95-89, Факс:8 (927) 768-95-89, Электронная почта: Maximum Education Томск Контакты:Адрес: ул. Проспект Фрунзе, 103, оф. 605 Томск,
Телефон:8 (3822) 908 910, Факс:8 (3822) 908 910, Электронная почта: Maximum Education Тула Контакты:Адрес: ул. Софьи Перовской 4, 2 этаж оф. 22,23 Тула,
Телефон:8 (4872) 52-60-81, Факс:8 (4872) 52-60-81, Электронная почта: Maximum Education Ульяновск Контакты:Адрес: ул. Гончарова, 5 Ульяновск,
Телефон:8 (8422) 50-57-50, Факс:8 (8422) 50-57-50, Электронная почта: Maximum Education Ярославль Контакты:Адрес: Октябрьский переулок, дом 3 Ярославль,
Телефон:8 (4852) 208-996, Факс:8 (4852) 208-996, Электронная почта:Программа охватывает все темы ЕГЭ от простых к сложным, включая их повторение в течение года, поэтому каждый ученик получит свой максимально возможный балл.
Смотри вебинары, тренируйся, читай теорию, отслеживай прогресс — в онлайн модуле! Тебе не придется искать информацию в интернете или копить распечатки.
Держи связь с преподавателем в социальных сетях, а не только на уроках. Обсуждай прогресс и задавай вопросы на личных беседах — преподаватель всегда ответит и поможет.
80+баллов по информатике ученики MAXIMUM получают в 2 раза чаще, чем в среднем по России
Запишитесь на консультацию
Это бесплатно и ни к чему вас не обязывает. Мы вам сразу перезвоним, и вы сможете уточнить все детали у нашего консультанта
Что вы получите на курсе
подготовки к ЕГЭ?
Только темы, необходимые для ЕГЭ, в простом и понятном формате — ничего лишнего!
На уроках мы будем работать только с актуальными заданиями в формате ЕГЭ
Мы научим тебя отвечать на любой вопрос так, чтобы получить за него максимум баллов
Поделимся с тобой секретными алгоритмами и методами решения заданий ЕГЭ
Мы проведем для тебя симуляции ЕГЭ и специальные мастер-классы, чтобы ты чувствовал себя уверенно
Гарантируем поступление нашим ученикам
Что вы могли не знать о
ЕГЭ по информатике- Программируем на Python, поскольку это самый оптимальный язык программирования с минимальными синтаксическими особенностями.
- Курс начинается с подготовительных уроков по математике для информатики, все математические задачи сразу формулируются и разбираются с позиции необходимого для будущих алгоритмов программирования или будущих элементов решения заданий математической логики.
- Всю первую половину курса мы будем работать с заданиями тестовой части, а во вторую разберем все задания части с письменным ответом.

Учитесь с нами в удобном формате
Нужна помощь в выборе курса?
Оставьте номер телефона, и мы перезвоним в течение 24 часов,
чтобы ответить на все вопросы
Результаты наших учеников в 2019 году
Посмотри, что происходило в чатах групп в день публикации результатов ЕГЭ
Образовательная
лицензия В MAXIMUM занятия с преподавателем проходят в любом удобном для
ученика формате:
В классе или онлайн, мини-группе или один на
один. На курсе ученик узнает теорию и формат экзамена, осваивает
лайфхаки и оптимальные методы
На курсе ученик узнает теорию и формат экзамена, осваивает
лайфхаки и оптимальные методы
Курсы
MAXIMUM по другим предметамЗанимайтесь онлайн или в классе
Оставьте заявку на консультацию
МЦКО
ЕГЭ по информатике и информационно-коммуникационным технологиям (ИКТ) – экзамен по выбору, который необходим для поступления в вузы на направления, предполагающие глубокое изучение современных информационных технологий и теоретической информатики. Результаты экзамена несколько улучшились в 2019 году, однако участники допускают типичные ошибки в некоторых заданиях. О них рассказывает обзор методических рекомендаций по итогам анализа результатов ЕГЭ-2019 от специалистов ФИПИ.
В 2019 году количество участников ЕГЭ по информатике и ИКТ существенно увеличилось по сравнению с прошлым годом, что соответствует тенденции интенсивного развития цифровых технологий в российской экономике и обществе. В ЕГЭ по информатике в 2019 году использовалась та же экзаменационная модель контрольных измерительных материалов, что и в прошлом году.
В ЕГЭ по информатике в 2019 году использовалась та же экзаменационная модель контрольных измерительных материалов, что и в прошлом году.
Каждый вариант экзаменационной работы состоит из двух частей и включает в себя 27 заданий, охватывающих следующие разделы курса информатики: информация и ее кодирование, моделирование и компьютерный эксперимент, системы счисления, логика и алгоритмы, элементы теории алгоритмов, программирование, архитектура компьютеров и компьютерных сетей, обработка числовой информации, технологии поиска и хранения информации.
Как и в прошлом году, участники ЕГЭ 2019 года успешно справились с заданиями, проверяющими умения представлять и считывать данные в разных типах информационных моделей (схемы, карты, таблицы, графики и формулы), прочесть фрагмент программы на языке программирования и исправить допущенные ошибки. Также они продемонстрировали хорошее знание позиционных систем счисления и двоичного представления информации в памяти компьютера, технологии обработки информации в электронных таблицах, основных конструкций языка программирования, понятий «переменной» и «оператора присваивания».
У участников ЕГЭ 2019 года возникли затруднения в заданиях, для успешного выполнения которых требовались умение определять объем памяти, необходимый для хранения графической информации, строить и преобразовывать логические выражения. Наиболее распространенной содержательной ошибкой в задании 24 является выявление и исправление только одной допущенной программистом ошибки из двух возможных – той, которая лежит на поверхности. В задании 25 распространенной ошибкой является отсутствие изменения значений элементов массива.
В задании 26 типичной причиной ошибок в ответе является отсутствие у экзаменуемого представления о выигрышной стратегии игры как наборе правил, в соответствии с которыми выигрывающий игрок должен отвечать на любой допустимый ход противника. Отсюда берутся неверные ответы, представляющие зачастую один или несколько вариантов развития игры без требуемого анализа и обоснования.
В ответах на задание 27 часто встречались логические ошибки, связанные с недостаточно полным рассмотрением всех возможных вариантов расположения пар чисел в последовательности.
При выполнении заданий с развернутым ответом значительная часть ошибок экзаменуемых обусловлена недостаточным развитием у них таких навыков, как детальный анализ условия задания, проверка своего ответа с целью поиска и исправления ошибок. Развитие таких навыков на протяжении всего периода обучения в школе будет способствовать существенно более высоким результатам ЕГЭ как по информатике, так и по другим учебным предметам.
При подготовке обучающихся к ЕГЭ 2020 года следует обратить особое внимание на освоение теоретических основ информатики, в том числе раздела «Основы логики», с учетом тесных межпредметных связей информатики с математикой, а также на развитие метапредметной способности к логическому мышлению.
Источник: http://obrnadzor.gov.ru
С 2021 года ЕГЭ по информатике можно будет сдавать на компьютерах
https://ria.ru/20190628/1556007112.html
С 2021 года ЕГЭ по информатике можно будет сдавать на компьютерах
С 2021 года ЕГЭ по информатике можно будет сдавать на компьютерах
Сдача единого государственного экзамена (ЕГЭ) по информатике на компьютерах начнется с 2021 года, заявил руководитель Рособрнадзора Сергей Кравцов. РИА Новости, 28.06.2019
РИА Новости, 28.06.2019
2019-06-28T12:14
2019-06-28T12:14
2019-06-28T12:14
навигатор абитуриента
социальный навигатор
сергей кравцов
федеральная служба по надзору в сфере образования и науки (рособрнадзор)
образование — общество
общество
/html/head/meta[@name=’og:title’]/@content
/html/head/meta[@name=’og:description’]/@content
https://cdn23.img.ria.ru/images/155586/43/1555864389_0:0:3077:1731_1920x0_80_0_0_2189565f0dce21e2dcd2163cace20dde.jpg
АНОСИНО (Московская обл.), 28 июн — РИА Новости. Сдача единого государственного экзамена (ЕГЭ) по информатике на компьютерах начнется с 2021 года, заявил руководитель Рособрнадзора Сергей Кравцов.»В части информатики: введение информатики на компьютере предполагается через учебный год, поэтому до 1 сентября все демоверсии будут размещены на сайте ФИПИ. Как я уже сказал, они будут соответствовать результатам прошлого года», — сказал Кравцов на всероссийском совещании региональных министров. Ранее пресс-служба Рособрнадзора сообщила, что работа по переходу на компьютеризацию экзаменов уже началась. Так, например, уже сейчас в ОГЭ по информатике есть задания на работу с электронными таблицами. В прошлом году Федеральным институтом педагогических измерений созданы новые перспективные компьютерные модели ОГЭ и ЕГЭ по информатике, не так давно прошедшие первые апробации, в которой проверяются все базовые практические навыки: поиск информации в сети интернет, работа с текстовым редактором, с электронными таблицами, создание презентаций.
Ранее пресс-служба Рособрнадзора сообщила, что работа по переходу на компьютеризацию экзаменов уже началась. Так, например, уже сейчас в ОГЭ по информатике есть задания на работу с электронными таблицами. В прошлом году Федеральным институтом педагогических измерений созданы новые перспективные компьютерные модели ОГЭ и ЕГЭ по информатике, не так давно прошедшие первые апробации, в которой проверяются все базовые практические навыки: поиск информации в сети интернет, работа с текстовым редактором, с электронными таблицами, создание презентаций.
https://ria.ru/20190628/1556003096.html
РИА Новости
7 495 645-6601
ФГУП МИА «Россия сегодня»
https://xn--c1acbl2abdlkab1og.xn--p1ai/awards/
2019
РИА Новости
7 495 645-6601
ФГУП МИА «Россия сегодня»
https://xn--c1acbl2abdlkab1og.xn--p1ai/awards/
Новости
ru-RU
https://ria.ru/docs/about/copyright.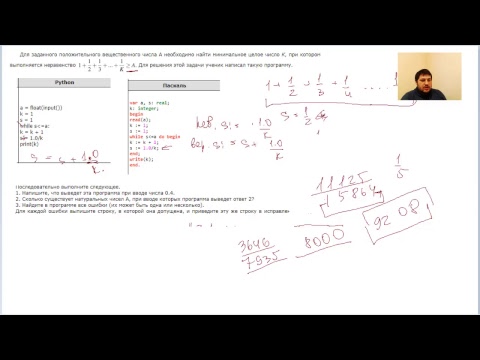 html
html
https://xn--c1acbl2abdlkab1og.xn--p1ai/
РИА Новости
7 495 645-6601
ФГУП МИА «Россия сегодня»
https://xn--c1acbl2abdlkab1og.xn--p1ai/awards/
https://cdn25.img.ria.ru/images/155586/43/1555864389_257:0:2988:2048_1920x0_80_0_0_039ac0864bf4a49fafbb599315ed7dd5.jpgРИА Новости
7 495 645-6601
ФГУП МИА «Россия сегодня»
https://xn--c1acbl2abdlkab1og.xn--p1ai/awards/
РИА Новости
7 495 645-6601
ФГУП МИА «Россия сегодня»
https://xn--c1acbl2abdlkab1og.xn--p1ai/awards/
навигатор абитуриента, социальный навигатор, сергей кравцов, федеральная служба по надзору в сфере образования и науки (рособрнадзор), образование — общество, общество
АНОСИНО (Московская обл.), 28 июн — РИА Новости. Сдача единого государственного экзамена (ЕГЭ) по информатике на компьютерах начнется с 2021 года, заявил руководитель Рособрнадзора Сергей Кравцов.
«В части информатики: введение информатики на компьютере предполагается через учебный год, поэтому до 1 сентября все демоверсии будут размещены на сайте ФИПИ. Как я уже сказал, они будут соответствовать результатам прошлого года», — сказал Кравцов на всероссийском совещании региональных министров.
Ранее пресс-служба Рособрнадзора сообщила, что работа по переходу на компьютеризацию экзаменов уже началась. Так, например, уже сейчас в ОГЭ по информатике есть задания на работу с электронными таблицами. В прошлом году Федеральным институтом педагогических измерений созданы новые перспективные компьютерные модели ОГЭ и ЕГЭ по информатике, не так давно прошедшие первые апробации, в которой проверяются все базовые практические навыки: поиск информации в сети интернет, работа с текстовым редактором, с электронными таблицами, создание презентаций.
28 июня 2019, 11:02
Васильева призвала обновить воспитательные программыИнформация
Innopolis Open — ежегодные соревнования по компьютерному программированию для старшеклассников. К участию в олимпиаде допускаются только старшеклассники младше 19 лет.
К участию в олимпиаде допускаются только старшеклассники младше 19 лет.
В конкурсе представлены задачи алгоритмического программирования, охватывающие широкий спектр приемов и уровней сложности.
Важные ссылки
Innopolis Open 2020 Второй раунд # ИннополисОпен2020 в информатике
❗️Внимание ❗️
Время начала второго квалификационного онлайн-раунда Innopolis Open по информатике изменено с 15:00 до 16:00 (UTC + 3) 14 декабря
. (по многочисленным просьбам для удобства участников)
Продолжительность раунда — 5 часов.
Практический раунд состоится 9-13 декабря перед квалификационным онлайн-раундом.
Тренировочный раунд — отличная возможность познакомиться с системой управления контестами PCMS2 . При этом результаты тренировочного раунда не влияют на квалификацию. У вас будет целых 5 дней, чтобы все протестировать и полностью подготовиться к квалификационному онлайн-раунду.
➡️ Чтобы пройти раунд, введите PCMS2 : https: // pcms.University.innopolis.ru/pcms2client/login.xhtml
Используйте логин и пароль от портала https://olymp.innopolis.ru.
В случае, если вы забыли пароль, напишите на [email protected].
Руководство PCMS2: https://drive.google.com/open?id=1mClgPceDLRDofl2SZ_GuSVajcO9GJWzU
Открытые правила Иннополиса: https://olymp.innopolis.ru/en/ooui/information/rules/
Удачи!
В теме письма укажите «Апелляция. Математика. 1-й квалификационный раунд ».Крайний срок подачи апелляции до 18:00 (UTC + 3) 6 декабря.
📌 Второй квалификационный онлайн-раунд состоится 15 декабря 2019 года в 10:00 (UTC + 3).
Раунды независимы, поэтому вы можете участвовать сразу в двух. Результат лучшего тура будет учитываться при выходе в Финал Олимпиады.
До встречи во 2-м квалификационном онлайн-раунде!
Innopolis Open 2020 Первый раунд 03. 12.2019:
12.2019:
❗️Все конкурсы были проверены на читерство, и такие работы не попали в список.
🥇 Официальные результаты будут опубликованы после 9 декабря
Если вы не согласны с решением жюри, обращайтесь на нашу электронную почту [email protected] с темой письма «Апелляция, информатика: Первый этап ».Крайний срок: 9 декабря
📌 Победители и призеры Иннополис Опен 2019 проходят в финал без квалификационного этапа, а также приглашаются на Зимний лагерь 2020
💻Приглашаем всех принять участие во 2-м квалификационном туре:
14 декабря, в 15.00 16.00 (UTC +3), , продолжительность 5 часов.
01.11.2019:
Напоминаем, что скоро начнутся первые отборочные онлайн-соревнования:
* Математика: 23 ноября 2019 г. , 15:00 (UTC + 3)
, 15:00 (UTC + 3)
* Информатика: 24 ноября 2019 г., 10:00 (UTC + 3)
Перед квалификацией будут проведены первые пробные соревнования 18-22 ноября 2019 года.
Пробный конкурс не повлияет на ваши результаты на Олимпиаде. Он проводится с целью ознакомления участников с системой управления конкурсом.Эта система также будет использоваться во время квалификационного онлайн-конкурса. Пожалуйста, проверьте все функции системы.
Система управления конкурсами по информатике: https://pcms.university.innopolis.ru/pcms2client/login.xhtml
Для входа в PCMS2 используйте логин и пароль от портала https://olymp.innopolis.ru. Если вы забыли пароль, напишите на [email protected].
Руководство PCMS2: https://drive.google.com/open?id=1mClgPceDLRDofl2SZ_GuSVajcO9GJWzU
Система управления олимпиадами по математике:
* 9 класс: https: // stepik.org / приглашение / 12d0ff04f3b840d3de5cec6ed3138e08d5ec23c5 /
* 10 класс: https://stepik. org/invitation/6a9369f3bb6c648eef381bae037ea48b0414032e/
org/invitation/6a9369f3bb6c648eef381bae037ea48b0414032e/
* 11 класс: https://stepik.org/invitation/08dab0846c8d9d2b5c133f3fabd65a62495818ec/
Руководство Stepik: https://drive.google.com/file/d/12zmdjyHSZCIJlIaVLWDWsaMc1l9z2URS/view?usp=sharing
Открытые правила Иннополиса: https://olymp.innopolis.ru/ru/ooui/information/rules/
Отборочные онлайн-соревнования (UTC +3):
* Математика: 23 ноября 2019 г., 15:00; 15 декабря в 10:00.
* Информатика: 24 ноября 2019 г., 10:00; 14 декабря в 15:00.
Заключительный этап в Университете Иннополис (Россия, Иннополис):
* Математика: 1-2 февраля 2020 г.
* Информатика: 22-23 февраля 2020 г.
Следите за новостями в Telegram и Facebook. Если у вас есть вопросы, пишите на [email protected]
Зимний лагерь по информатике30.09.2019:
В Зимнем лагере участники готовятся к международным олимпиадам по информатике. Вы можете попасть в лагерь, если прошли онлайн-отборочный этап Innopolis Open по информатике.
Вы можете попасть в лагерь, если прошли онлайн-отборочный этап Innopolis Open по информатике.
Участники: студенты 13-19 лет
Дата: 14 — 21 февраля 2020 г.
Язык мероприятия: Английский / Русский
Почему зимний лагерь:
* Лучшие преподаватели Университета Иннополис и других топовых вузов
* Повышение квалификации по информатике
* Целенаправленная подготовка к Иннополису Open in Informatics
* Бесплатное проживание в кампусе Университета Иннополис
* Бесплатное сбалансированное 5-разовое питание
* Бесплатный трансфер Казань — Иннополис — Казань
26.09.2019:
Открытая международная олимпиада Иннополис по математике , по информатике и Информационная безопасность для школьников 13-19 лет пройдет в феврале — марте 2020 года в Университете Иннополис.
Почему Иннополис открыт:
* Соревнования подготовлены под руководством чемпионов мира по финалу ACM ICPC.
* Лауреаты призов имеют выгодный статус при поступлении на обучение в Университет Иннополис и другие лучшие университеты России.
* Участникам финального этапа будут вручены ценные призы. Размещение и питание оплачиваются Организатором.
В Иннополис Опен по математике есть три возрастные категории:
1) 7-9 класс (13-15 лет)
2) 10 класс (16-17 лет)
3) 11 класс (18-19 лет)
Олимпиада проводится в два этапа: отборочный и финальный.
Отборочный этап Innopolis Open по математике и информатике состоит из двух независимых онлайн-конкурсов.Вы можете участвовать в обоих конкурсах. Для перехода в следующий этап принимается лучший результат двух конкурсов.
Отборочный этап Innopolis Open по информационной безопасности состоит из двух зависимых онлайн-соревнований: первое (индивидуальное) соревнование переходит во второе (командное).
Даты отборочных онлайн-конкурсов (UTC +3):
* Математика: 23 ноября 2019 г., 15:00; 15 декабря в 10:00.
* Информатика: 24 ноября 2019 г., 10:00; 14 декабря в 15:00.
* Информационная безопасность: 7-8 декабря 2019 г., сроки проведения второго тура уточняются.
Сроки проведения финального этапа в Университете Иннополис (Россия, Иннополис):
* Математика: 1-2 февраля 2020 г.
* Информатика: 22-23 февраля 2020 г.
* Информационная безопасность: март 2020 г.
Как принять участие в Innopolis Open: 1. Зарегистрируйтесь на https://olymp.innopolis.ru/ru/ooui/registration/ или войдите под своим логином (этот адрес электронной почты) и паролем (который вы получили при регистрации на сайте). ).Если вы забыли пароль к своей учетной записи, напишите на адрес [email protected].
2. Зарегистрируйтесь в Innopolis Open в профиле, в котором хотите участвовать: https://olymp.innopolis.ru/ru/ooui/2020/. Вы можете участвовать сразу во всех 3 профилях. Регистрация открыта до 22 ноября 2019 года. 3. Следите за новостями в Telegram и Facebook. Если у вас есть вопросы, пишите на [email protected]
Регистрация открыта до 22 ноября 2019 года. 3. Следите за новостями в Telegram и Facebook. Если у вас есть вопросы, пишите на [email protected]
До встречи в Иннополисе Опен!
Иннополис Открыт 2019 ФИНАЛ
17.01.2019:
Приглашенные на финал участники должны были получить пригласительное письмо. Там вы можете найти регистрационную форму, которую необходимо заполнить.
Пожалуйста, проверьте свою электронную почту! Времени осталось не так много.
По многочисленным просьбам регистрация продлена до 3 февраля.
Ждем вас в Иннополисе!
Мы рады пригласить вас на открытый финал Иннополиса
Innopolis Open 2019 второй раунд
20.12.2018:
Второй раунд Innopolis Open стартует 23 декабря в 10:00 (UTC +3)!
Для участия в конкурсе воспользуйтесь следующей ссылкой: https://pcms. university.innopolis.ru/.
university.innopolis.ru/.
Правила: https://olymp.innopolis.ru/ooui/information/rules/
Продолжительность конкурса: 5 часов (с 10.00 до 15.00)
Для входа в систему необходимо использовать логин и пароль от Иннополиса. Открыть сайт. Если вы забыли пароль, воспользуйтесь кнопкой «Забыли пароль».
Если у Вас возникнут вопросы или проблемы, не стесняйтесь обращаться к нам по адресу [email protected]
Материалы олимпиады:
Innopolis Open 2019 тренировочный раунд
20.11.2018:
Приглашаем вас принять участие в тренировочном раунде Innopolis Open.
Дата: 23 ноября 15:00 — 30 ноября 15:00 (UTC +3)
Практический раунд не повлияет на ваши результаты на Олимпиаде.Он проводится с целью ознакомления участников с системой управления конкурсом. Эта система также будет использоваться во время онлайн-конкурса. Пожалуйста, проверьте все функции системы. Система будет доступна 27 ноября в 10:00 (UTC +3).
Система будет доступна 27 ноября в 10:00 (UTC +3).
Воспользуйтесь следующей ссылкой, чтобы опробовать систему: https://pcms.university.innopolis.ru/pcms2client/login.xhtml.
Для входа в PCMS необходимо использовать логин и пароль с сайта Innopolis Open. Если вы забыли пароль, воспользуйтесь кнопкой «Забыли пароль».
Также вы можете посетить страницу с открытыми правилами Иннополиса и руководством по PCMS2.
12.11.2018:
Innopolis Open 2019 открыта регистрация!
Первый этап (онлайн-конкурс) состоится:
— 1 декабря 15:00 (UTC +3)
— 23 декабря 10:00 (UTC +3)
Вы можете участвовать в обе даты; Оргкомитет рассмотрит ваш лучший результат. Регистрация открыта до 1 декабря 2018 года.Участие бесплатное. Второй этап (очное соревнование) состоится в городе Иннополис 23-24 февраля 2019 года. Для регистрации на олимпиаду нажмите здесь.
27. 02.2018:
02.2018:
Завершился финальный этап Innopolis Open 2018.
Материалы олимпиады:
10.02.2018: Выездные соревнования пройдут в городе Иннополис (Россия) 24-25 февраля 2018 года.Иннополис находится в 50 км от международного аэропорта Казань. Всем участникам будет предоставлено бесплатное питание, проживание и трансфер из аэропорта в Иннополис. Победители будут награждены призами и получат возможность получить 100% стипендию на обучение в Университете Иннополис, пройдя собеседование. Это интервью также будет доступно для кандидатов с соответствующими результатами.
Обращаем ваше внимание на то, что уровень задач в очном конкурсе будет намного выше, чем во время онлайн-конкурса.Вы можете проверить проблемы за предыдущий год здесь: Codeforces.
Будем очень рады видеть Вас в Иннополисе! Мы уверены, что вам понравится пребывание в самом молодом городе России, вы будете впечатлены инфраструктурой и условиями для студентов и познакомитесь с удивительными людьми со всего мира!
Все участники получили организационную информацию (прибытие, расписание и т. Д.) По электронной почте!
Д.) По электронной почте!
22.12.2017
Список участников, приглашенных на финальный этап Открытой олимпиады Иннополис по результатам второго отборочного тура.
Вам необходимо подтвердить свое участие — подробная информация появится до 25 декабря .
Все остальные по умолчанию считаются в резерве, если кто-то из приглашенных участников откажется, мы спустимся по списку и пригласим из резерва.
22.12.2017
Мы обновляем список участников, приглашенных на финальный этап Открытой олимпиады Иннополис по результатам первого отборочного тура. Вы можете это проверить.
Вы можете это проверить.
08.12.2017
Список участников, приглашенных на финальный этап Открытой олимпиады Иннополис по результатам первого отборочного тура.
Вам необходимо подтвердить свое участие — подробная информация появится до 25 декабря .
Все остальные по умолчанию считаются в резерве, если кто-то из приглашенных участников откажется, мы спустимся по списку и пригласим из резерва.
INNOPOLIS OPEN 2018 Расписание
20 октября — 15 декабря — Регистрация.
2 декабря, 2017 — Первый онлайн-конкурс.
17 декабря 2017 — Второй онлайн-конкурс.
24-25 февраля 2018 г. — выездной этап, который пройдет в Иннополисе.
Удачи и до встречи на выезде в Иннополисе!
Заседание представителей информатики и студентов
Присутствуют: Бьорн Франке, директор по обучению, Нил Хитли, руководитель службы поддержки студентов, сотрудник службы поддержки студентов Карен Дэвидсон, сотрудник службы поддержки студентов Лизы Бранни, служба компьютерной поддержки Кэрол Доу, Кендал Рид ITO
Обновленная информация о встрече на прошлой неделе, Школа математики и Школа бизнеса не размещают отзывы о курсах в Интернете.
Нил поговорил с лектором о рабочей нагрузке для IoTSSC, изначально курс был разработан для парного, а затем он был изменен на индивидуальный, лектор заявил, что в курсе есть правильный объем работы для курса из 20 кредитов, и курс был заранее одобрен Школой.
Нил также поговорил с лектором INF2-SEPP по поводу страниц Learn.
УГ1
INF1-CG, похоже, имеет проблемы со звуком во время живых лекций, проблемы с расписанием и чтением, и некоторые студенты считают, что они самообучаются.
Было 6 лекций и только одна была в прямом эфире, сессий вопросов и ответов не было.
INF1A — если учащиеся не пройдут курс, если не будет действовать политика ущерба, как в прошлом году, — объяснил Бьорн, школа пытается решить любые проблемы, с которыми могут столкнуться учащиеся.
INF1B Сообщается, что у лектора плохое соединение Wi-Fi, так как экран продолжает зависать. Есть еженедельные лабораторные упражнения, которые действительно хорошо объяснены, и курс хорошо преподается, содержание Java интересно.
УГ2
INF2-SEPP учащиеся считают интерактивные сеансы вопросов и ответов активными.
Студенты хотели бы, чтобы лекции были доступны, когда они должны были быть, так как они работают в соответствии с графиком лекций, которые должны быть доступны, когда они должны быть. Некоторые чтения недоступны в списке ресурсов!
INF2FDS студентам очень нравится курс и деятельность на Piazza. Студенты спросили, почему так много лекционного материала, чтобы охватить около 2 человек.5 часов в неделю, и они задавались вопросом, не было ли это слишком много для курса на 20 кредитов.
* Action Bjoern, чтобы посмотреть на одобрение BoS *
Основы чистой математики включают сессии вопросов и ответов, которые очень полезны, а вопросы, подготовленные заранее, очень хороши, студенты также наслаждаются живыми сессиями по исчислению. Курсовая работа, выпущенная на нулевой неделе, была направлена на то, чтобы студенты начали работать. Студенты недовольны тем, что неделя математики длится с четверга по четверг. Они получают чтение в четверг, а первое учебное пособие проводится в понедельник.
Студенты недовольны тем, что неделя математики длится с четверга по четверг. Они получают чтение в четверг, а первое учебное пособие проводится в понедельник.
* Действие Нил, чтобы поговорить с доктором математики *
УГ3
Никаких проблем, плавный переход ко второму семестру. У CS очень хорошее планирование.
УГ4
OS on Path, в нем говорится, что каждую неделю проходят 2 живые лекции, 2 для PA и 1 для IoTSSC (за исключением 7-й и 11-й недель для OS)
Сообщалось, что живых лекций по OS не было, люди спрашивали на Piazza, и лектор пояснил, что после 3 недели могут быть живые лекции.
живых сессий PA, кажется, происходят только раз в неделю во вторник или пятницу; расписание на странице «Обучение» — единственное место, где указано, когда на самом деле будут проводиться сеансы в реальном времени.
IoTSSC пока не проводил живых сеансов; кто-то спросил на Piazza, и лектор сказал, что он будет рекламировать некоторые игровые автоматы заранее, и что на первые несколько недель не запланировано никаких живых игр.
PA является лучшим, потому что лектор по крайней мере одним способом дает понять, когда на самом деле происходят живые сеансы, но раздражает то, что Path говорит, что сеансы есть, а их нет.
Есть ли новости о продлении сроков выполнения проекта, Бьорн все еще обсуждает с Организатором проекта. Также не было никакой информации о групповых презентациях на 2-й и 3-й неделях. Если никто не получил известий от своих руководителей, им следует связаться с Barbara Web.
MSc
IPP CW1 еще не выпущен. Был задан вопрос, может ли этот курс рассматриваться как курс «прошел / не прошел», а не оцениваться. Это правило университета, что этот курс, следовательно, он является отмеченным курсом.Инструкторы курса не очень активны на странице Piazza.
ПроектыMSc еще не объявлены, они должны быть доступны к концу дня, если они не свяжутся с Нилом.
Общие
Датой публикации диеты для экзаменов Non-Honors является 15 -го февраля. Студенты должны подавать заявление при особых обстоятельствах только в том случае, если они чувствуют, что пострадали, и они должны быть поданы до собрания экзаменационной комиссии; студенты не должны подавать заявление только потому, что они проиграли.Решения о прогрессе будут опубликованы в августе.
Студенты должны подавать заявление при особых обстоятельствах только в том случае, если они чувствуют, что пострадали, и они должны быть поданы до собрания экзаменационной комиссии; студенты не должны подавать заявление только потому, что они проиграли.Решения о прогрессе будут опубликованы в августе.
Следует ли считать Неделю гибкого обучения выходным днем или учащимся следует работать? Бьорн объяснил, что на этой неделе нет запланированных занятий, и студенты могут либо сделать перерыв, либо использовать его, чтобы наверстать упущенное по работе.
Можно назначить экзамены более чем на 2 часа. Некоторые студенты сообщают, что 2 часа на сдачу экзамена и один часовой формат не подходят для часовых поясов, личных обстоятельств и т. Д.Бьорн объяснил, что если экзамен сдавался в кампусе, то на его выполнение было бы всего 2 часа, и мы должны придерживаться этого правила.
Нил спросил представителей, могут ли они продвигать премию EUSA Teaching Awards, поскольку это хороший способ продвинуть любого, кто проделал особенно хорошую работу.
https://www.eusa.ed.ac.uk/yourvoice/ourwork/teachingawards/nominate/
Планировщик курсовых работ на семестр 2 все еще не обновлен.
Некоторые расписания неверны, некоторые лекции отображаются как предварительно записанные, а затем они оказываются живыми, и их можно пропустить.
Заглавные буквы: заглавные буквы и сокращения
Заглавные буквы на самом деле не являются аспектом пунктуации, но с ними удобно работать. с ними здесь. Правила их использования в большинстве своем очень простые.
(а) Первое слово предложения или отрывка начинается с заглавной буквы:
- Неуклюжий волшебник Ринсвинд — самый популярный персонаж Пратчетта.
- Доживет ли кто-нибудь из ныне живущих до колонии на Луне? Возможно нет.
- К сожалению, немногие ученики могут найти Ирак или Японию на карте Мир.
- Доживет ли кто-нибудь из ныне живущих до колонии на Луне? Возможно нет.
(б) Названия дней недели и месяцев года: написано с большой буквы:
- В следующее воскресенье во Франции пройдут всеобщие выборы.
- Моцарт родился 27 января 1756 года.
- Футбольные тренировки проходят по средам и пятницам.
- Моцарт родился 27 января 1756 года.
Однако названия сезонов — , а не пишутся с большой буквы:
- Летом в бейсбол, как и в крикет, играют.
Не пишите * « … летом «.
(c) Названия языков всегда пишутся с заглавной буквы. Будь осторожен об этом; это очень распространенная ошибка.
- Джульетта говорит на английском, французском, итальянском и португальском языках.
- Мне нужно поработать над неправильными испанскими глаголами.
- Среди основных языков Индии — хинди, гуджарати и тамильский.
- В наши дни немногие студенты изучают латинский и греческий языки.
- Мне нужно поработать над неправильными испанскими глаголами.
Учтите, однако, что названия дисциплин и школьных предметов — , а не . с заглавной буквы, если они не являются названиями языков:
- Я сдаю A-level по истории, географии и английскому языку.
- Ньютон внес важный вклад в физику и математику.
- Она изучает французскую литературу.
- Ньютон внес важный вклад в физику и математику.
(d) Слова, которые выражают связь с определенным местом, должны быть написаны с заглавной буквы. когда они имеют буквальное значение. Так, например, французский должен быть с заглавной буквы, когда это означает «имеющий отношение к Франции»:
- Результат французских выборов все еще под вопросом.
- Американские и российские переговорщики близки к соглашению.
- В голландском пейзаже нет гор.
- У нее сухое манкунианское чувство юмора.
- Американские и российские переговорщики близки к соглашению.
(Слово Mancunian означает «из Манчестера».)
Однако нет необходимости использовать эти слова с большой буквы, когда они встречаются. как части фиксированных фраз и не выражают прямой связи с соответствующие места:
- Купите, пожалуйста, датскую выпечку.
- В теплую погоду мы держим окна открытыми.
- Я предпочитаю русскую заправку для салата.
- В теплую погоду мы держим окна открытыми.
В чем разница? Что ж, датское тесто — это просто особый вид теста;
он не обязательно должен быть из Дании. Точно так же французские окна — это просто
особый вид окна, а русское убранство — это всего лишь особая разновидность
заправка для салата. Даже в этих случаях вы можете использовать эти слова с большой буквы, если хотите.
до, если вы последовательны в этом. Но обратите внимание, насколько удобно может быть разница:
Точно так же французские окна — это просто
особый вид окна, а русское убранство — это всего лишь особая разновидность
заправка для салата. Даже в этих случаях вы можете использовать эти слова с большой буквы, если хотите.
до, если вы последовательны в этом. Но обратите внимание, насколько удобно может быть разница:
- В теплую погоду мы держим окна открытыми.
- С наступлением темноты французские окна всегда закрываются ставнями.
В первом примере французских окон просто относится к разновидности окна; в в во-вторых, французских окон относится конкретно к окнам во Франции.
е) в том же ключе слова, обозначающие национальности или этнические группы, должны быть заглавные буквы:
- Баски и каталонцы десятилетиями боролись за автономию.
- Сербы и хорваты стали заклятыми врагами.
- Самый популярный певец Норвегии — саам из Лапландии.
- Сербы и хорваты стали заклятыми врагами.
(В стороне: некоторые этнические ярлыки, которые раньше широко использовались, теперь
многие люди считают их оскорбительными и заменены другими ярлыками. Таким образом, внимательные писатели используют Black , а не Negro ; коренной американец , а не индеец или красный
Indian ; абориген , а не абориген . Вам рекомендуется
последовать их примеру.)
Таким образом, внимательные писатели используют Black , а не Negro ; коренной американец , а не индеец или красный
Indian ; абориген , а не абориген . Вам рекомендуется
последовать их примеру.)
(f) Раньше слова черный и белый применительно к людям были никогда не пишется с заглавной буквы.Однако в настоящее время многие люди предпочитают извлекать из них выгоду. потому что они считают эти слова этническими ярлыками, сопоставимыми с китайцами или Индийский :
- Дело Родни Кинга привело в ярость многих чернокожих американцев.
Вы можете использовать эти слова с заглавной буквы или без них, но будьте последовательны.
(g) Имена собственные всегда пишутся с заглавной буквы. Имя собственное — это имя или титул, который относится к отдельному человеку, отдельному месту, отдельному учреждению или индивидуальное мероприятие.Вот некоторые примеры:
- Ноам Хомский произвел революцию в изучении языка.
- Мост Золотые Ворота возвышается над заливом Сан-Франциско.
- Между профессором Лейси и доктором Дэвисом состоится спор.
- Королева обратится сегодня к Палате общин.
- Многие ошибочно полагают, что Мексика находится в Южной Америке.
- Моя подруга Джули готовится к зимним Олимпийским играм.
- На следующей неделе президент Клинтон встретится с канцлером Колем.
- Мост Золотые Ворота возвышается над заливом Сан-Франциско.

Обратите внимание на разницу между следующими двумя примерами:
- Мы попросили о встрече с Президентом.
- Я хочу быть президентом большой компании.
В первом заголовке президент пишется с заглавной буквы, потому что это заголовок, относящийся к
конкретный человек; во втором нет заглавной буквы, потому что слово президент не относится ни к кому конкретно. (Сравните Мы попросили о встрече
с президентом Вильсоном и * я хотел бы быть президентом Вильсона большой
компании .) То же самое различие делается другими словами: мы пишем как
Правительство и Парламент , когда мы говорим о конкретном правительстве или
конкретный парламент, но мы пишем правительство и парламент , когда мы
используя слова в общем. Также обратите внимание на следующий пример:
Также обратите внимание на следующий пример:
- Покровитель плотников Святой Иосиф.
Здесь Святой Иосиф — это имя, а Святой покровитель — нет и не получает капитала.
Есть небольшая проблема с названиями неопределенно определенных географических регионы. Обычно мы пишем Ближний Восток и Юго-Восточная Азия , потому что эти регионы теперь считаются имеющими отличительную идентичность, но мы пишем центральных Европа и юго-восток Лондон , потому что эти регионы не считаются с такой же идентичностью.Также обратите внимание на разницу между South Африка (название конкретной страны) и южная Африка (неопределенное определение область, край). Все, что я могу предложить, это прочитать хорошую газету и твои глаза открыты.
Обратите внимание, что некоторые фамилии иностранного происхождения содержат небольшие слова, которые
часто не пишутся с заглавной буквы, например на , на , на , на и на . Таким образом, мы пишем Леонардо да Винчи , Людвиг ван Бетховен , Генерал фон Мольтке и Симона де
Бовуар .С другой стороны, мы пишем Daphne Du Maurier и Dick Van
Dyke , потому что именно такие формы предпочитают владельцы имен.
Если сомневаетесь, проверьте правописание в хорошем справочнике.
Таким образом, мы пишем Леонардо да Винчи , Людвиг ван Бетховен , Генерал фон Мольтке и Симона де
Бовуар .С другой стороны, мы пишем Daphne Du Maurier и Dick Van
Dyke , потому что именно такие формы предпочитают владельцы имен.
Если сомневаетесь, проверьте правописание в хорошем справочнике.
Некоторые люди эксцентрично предпочитают писать свои имена без заглавной буквы. буквы у всех, типа поэт эл. е. Каммингс и певец к. d. lang . Эти странные обычаи следует уважать.
(h) Названия отличительных исторических периодов пишутся с заглавной буквы:
- Лондон был процветающим городом в средние века.
- Великобритания была первой страной, получившей прибыль от промышленной революции.
- Греки были в Греции уже в бронзовом веке.
- Великобритания была первой страной, получившей прибыль от промышленной революции.
(i) Названия праздников и святых дней пишутся с заглавной буквы:
- У нас большие перерывы на Рождество и Пасху.
- Во время Рамадана нельзя есть до захода солнца.
- Праздник Пурим — повод для веселья.
- Наша церковь очень строго соблюдает субботу.
- Детям очень нравится Хэллоуин.
- Во время Рамадана нельзя есть до захода солнца.

(j) Многие религиозные термины пишутся с заглавной буквы, включая названия религий и их последователей, имена или титулы божественных существ, титулы определенных важных фигур, названия важных событий и имена священных книги:
- Атеист — это человек, который не верит в Бога.
- Основные религии Японии — синтоизм и буддизм.
- В индийскую команду по крикету входят индуисты, мусульмане, сикхи и парсы.
- Господь мой пастырь.
- Пророк родился в Мекке.
- Тайная вечеря произошла в ночь перед распятием.
- Ветхий Завет начинается с книги Бытия.
- Основные религии Японии — синтоизм и буддизм.
Однако обратите внимание, что слово бог — это , а не с заглавной буквы, когда оно относится к язычнику. божество:
- Посейдон был греческим богом моря.
(k) В названии или названии книги, пьесы, стихотворения, фильма, журнала, газета или музыкальное произведение, первое слово и для обозначения каждое значащее слово (то есть такое маленькое слово, как , , из , и или в , не с заглавной буквы, если это не первое слово):
- Я был в ужасе от Молчание ягнят .
- Круглая башня написана Кэтрин Куксон.
- Самая известная органная пьеса Баха — это Токката и Фуга в D Незначительный .
- Обычно я не люблю Шер, но мне нравится The Shoop Shoop Song .
- Круглая башня написана Кэтрин Куксон.
Важное примечание: Только что описанная политика является наиболее широко используемой в в Англоязычный мир. Однако существует вторая политика, которую предпочитают много людей. В этой второй политике мы пишем только первое слово заголовка с заглавной буквы. и любые слова, которые по сути требуют заглавных букв по независимым причинам.При использовании второй политики мои примеры будут выглядеть так:
- Меня напугал Молчание ягнят .
- Круглая башня написана Кэтрин Куксон.
- Самая известная органная пьеса Баха — это Токката и фуга в D Малый .
- Обычно я не люблю Шер, но мне нравится The shoop shoop song .
- Круглая башня написана Кэтрин Куксон.
Вы можете использовать любую политику, которую предпочитаете, при условии, что вы
Это. Однако вы можете обнаружить, что ваш наставник или редактор настаивают на одном или
другой. Вторая политика особенно распространена (хотя и не универсальна) в
академические круги и обычное дело среди библиотекарей; в другом месте первая политика
почти всегда предпочтительнее.
Однако вы можете обнаружить, что ваш наставник или редактор настаивают на одном или
другой. Вторая политика особенно распространена (хотя и не универсальна) в
академические круги и обычное дело среди библиотекарей; в другом месте первая политика
почти всегда предпочтительнее.
(l) Первое слово прямой цитаты, повторяющей чьи-то точные слова, всегда пишется с заглавной буквы, если цитата является полным предложением:
- Томас Эдисон замечательно заметил: «Гений — это один процент вдохновения. и девяносто девять процентов пота.»
Но нет заглавной буквы, если цитата не является полным предложением:
- Министр охарактеризовал последние данные по безработице как «разочаровывает».
(m) Торговые марки производителей и их продукты пишутся с заглавной буквы:
- Максин купила подержанный Ford Escort.
- Sony Walkman есть почти у всех.
Примечание: Есть проблема с торговыми марками, которые стали настолько успешными. что они используются в обычной речи как общие ярлыки для классов продуктов.Производители Kleenex и Sellotape очень рады найти людей
используя kleenex и скотч как обычные слова для лицевых салфеток или липкую ленту
любого вида, и некоторые такие производители могут фактически подать в суд на
это практика. Если вы пишете для публикации, вам нужно быть осторожным с
это, и лучше всего использовать такие слова с заглавной буквы, если вы их используете. Однако когда
названия брендов преобразуются в глаголы, заглавные буквы не используются: пишем Она
пылесосил ковер и Мне нужно ксерокопировать этот отчет , хотя
производители пылесосов Hoover и копировальных аппаратов Xerox не так много
как и эта практика.
что они используются в обычной речи как общие ярлыки для классов продуктов.Производители Kleenex и Sellotape очень рады найти людей
используя kleenex и скотч как обычные слова для лицевых салфеток или липкую ленту
любого вида, и некоторые такие производители могут фактически подать в суд на
это практика. Если вы пишете для публикации, вам нужно быть осторожным с
это, и лучше всего использовать такие слова с заглавной буквы, если вы их используете. Однако когда
названия брендов преобразуются в глаголы, заглавные буквы не используются: пишем Она
пылесосил ковер и Мне нужно ксерокопировать этот отчет , хотя
производители пылесосов Hoover и копировальных аппаратов Xerox не так много
как и эта практика.
(n) Римские цифры обычно пишутся с заглавной буквы:
- Нелегко умножить LIX на XXIV, используя римские цифры.
- Король Альфонсо XIII передал власть генералу Примо де Ривере.
Единственное распространенное исключение — маленькие римские цифры используются для нумерации
страницы обложки в книгах; посмотрите практически любую книгу.
(o) Местоимение I всегда пишется с большой буквы:
- Она думала, что я одолжил ей ключи, но я этого не сделал.
Можно написать целое слово или фразу заглавными буквами по порядку чтобы подчеркнуть это:
- СОВЕРШЕННО НЕТ ДОКАЗАТЕЛЬСТВ, подтверждающих это предположение.
В целом, однако, предпочтительнее выражать акцент, а не заглавными буквами. буквы, но курсивом. Необязательно писать слово с заглавной буквы только потому, что есть только один то, к чему это может относиться:
- Экватор проходит через середину Бразилии.
- Адмирал Пири был первым человеком, совершившим перелет через северный полюс.
- Считается, что Вселенной около 15 миллиардов лет.
- Адмирал Пири был первым человеком, совершившим перелет через северный полюс.
Здесь слова экватор , северный полюс и вселенная не нуждаются в заглавных буквах, потому что они
не являются строго собственными именами. Некоторые люди все равно предпочитают использовать их с большой буквы;
в этом нет ничего плохого, но это не рекомендуется.
Заглавные буквы используются также при написании некоторых сокращения и связанные типы слов, включая сокращенные наименования организаций и компаний, и в письме написание и в рубриках рефератов.
Есть еще одно довольно редкое использование заглавных букв, которое стоит объяснять хотя бы для того, чтобы вы не сделали это по ошибке, когда вы этого не сделаете значит. Это для того, чтобы подшутить над чем-то. Вот пример:
- Французская революция сначала была хорошей вещью, но восстание Наполеона к власти было плохо.
Здесь писатель высмеивает обычную тенденцию видеть исторические события. простыми словами, как хорошее или плохое. Другой пример:
- Многие люди утверждают, что рок-музыка — это серьезное искусство, заслуживающее серьезного Критическое внимание.
Писатель явно саркастичен: все эти необычные заглавные буквы демонстрируют что он считает рок-музыку бесполезным мусором.
Этот стилистический прием уместен только в письменной форме, которая предназначена для
быть юмористическим или хотя бы беззаботным; это совершенно неуместно в формальном письме.
Использование ненужных заглавных букв, когда вы пытаетесь быть серьезным может быстро сделать вашу прозу идиотской, как эти книги без содержания заполняющие полки раздела «New Age» в книжных магазинах:
- Ваша эйдетическая душа связана своим Кристальным шнуром с Седьмым кругом астральный план, откуда исходит Имманентная сущность передается вашей эйдетической ауре…
Вы уловили идею. Не используйте заглавную букву, если не уверены, что знаете почему. Это здесь.
Краткое содержание заглавных букв:
Заглавные буквы
- первое слово предложения или фрагмента
- название дня или месяца
- название языка
- слово, выражающее связь с местом
- название национальности или этнической группы
- имя собственное
- название исторического периода
- название праздника
- важный религиозный термин
- первое слово и каждое значащее слово заголовка
- первое слово прямой цитаты, которая является приговор
- торговая марка
- римская цифра
- местоимение I
Авторское право © Ларри Траск, 1997 г.
Поддерживается факультетом информатики Университета Сассекса
Обзор теста HLA
Оценка языка по Холмсу — это компьютерный экзамен, который проводится в прямом эфире с экзаменатором через Zoom.Эта оценка предназначена для использования поставщиками высшего образования и направлена на оценку уровня владения английским языком кандидатов, желающих поступить в университеты в Великобритании, Австралии и по всему миру.
Оценка языка по Холмсу (HLA) — это комплексная оценка навыков, которая оценивает способности кандидата по четырем навыкам: чтение, письмо, говорение и аудирование — или сочетание навыков.
Экзамен оценивает подлинные и академические навыки английского языка, которые помогают подготовить кандидатов к жизни в университете.Эти задания выполняются один на один с высококвалифицированным собеседником с родным акцентом.
HLA — это высокоточная оценка, которая проводится вслепую как собеседником, так и вторым оценщиком, обеспечивая беспристрастность и точность. Результаты обычно доступны в течение пяти рабочих дней, а оценку обычно можно записать в течение 24 часов.
Результаты обычно доступны в течение пяти рабочих дней, а оценку обычно можно записать в течение 24 часов.
Щелкните здесь, чтобы загрузить PDF-копию формата и процедуры HLA
Квалификационная цель
Цель HLA — оценить уровень владения английским языком абитуриентов, поступающих на программы Института Холмса и другие программы высшего образования и подготовки, не требуя от кандидатов прохождения внешнего тестирования.
Процедура предназначена не для получения детального профиля языковых навыков кандидата, а для того, чтобы дать рейтерам возможность произвести рабочую оценку способности кандидата пройти курсы, в противном случае требующие начальных уровней IELTS 5.5–6.5 (CEFR B2- C1). Это достигается за счет того, что от тестируемых требуется выполнить ряд языковых задач, непосредственно связанных с компетенциями в CEFR B2 / C1, и их оценивают оценщики из числа старших преподавателей OHC.
Резюме
Разговорная речь
Этап 1 HLA — это оценка речевых способностей кандидата. Есть две задачи, вторая задача состоит из двух частей. Для выполнения этих заданий кандидаты:
Есть две задачи, вторая задача состоит из двух частей. Для выполнения этих заданий кандидаты:
- Участвуйте в беседе с экспертом.
- Произведите длинный поворот, говоря от одной до двух минут на заданную тему.
- Участвуйте в более академическом обсуждении современной проблемы или актуального предмета.
Прослушивание
Этап 2 HLA — это оценка способности кандидата слушать. Есть два задания, второе из которых представляет собой комплексную оценку навыков, в рамках которой кандидаты:
- Прослушайте монолог на академическую тему, для понимания которой не требуются специальные знания.Затем кандидатов просят объяснить общую тему беседы.
- Прослушайте выступление еще раз и выделите конкретные поднятые вопросы, как положительные, так и отрицательные, затем объясните их оценщику своими словами.
Чтение
Этап 3 HLA — это оценка навыков чтения кандидата. Есть два задания, второе из которых — это комплексный тест чтения на письмо. Кандидаты на выполнение этих заданий:
Кандидаты на выполнение этих заданий:
- Прочтите текст и сопоставьте информацию с абзацами.
- Прочтите короткий текст по современной проблеме или актуальной теме и напишите краткое содержание прочитанного текста.
Написание
Этап 4 HLA — это оценка письменных способностей кандидата, которая ставит под угрозу единственную задачу, где кандидаты:
JMIR Медицинская информатика — Разработка практического инструмента искусственного интеллекта для диагностики и оценки расстройства аутистического спектра: Многоцентровое исследование
Введение
Предпосылки
Расстройство аутистического спектра (РАС) — это гетерогенное расстройство, характеризующееся социальными нарушениями, коммуникативными дефицитами и ограниченным повторяющимся поведением.Согласно отчету об аутизме Центров по контролю и профилактике заболеваний за 2018 год, примерно у 1% (1/59) детей в США в возрасте 8 лет был диагностирован РАС, что представляет собой увеличение по сравнению с предыдущими отчетами []. Стоимость диагностики и лечения РАС растет вместе с ростом распространенности. Недавнее исследование предсказало, что стоимость лечения вырастет до 461 миллиарда долларов США в 2025 году, если уровень распространенности РАС останется неизменным на нынешнем уровне, и что расходы вырастут до 1 триллиона долларов США к 2025 году, если уровень распространенности РАС продолжит резко расти, как это видно из предыдущего исследования. последнее десятилетие [].Однако были высказаны опасения относительно точности и достоверности заявленного увеличения распространенности РАС, поскольку многие другие нейроповеденческие состояния, а также вариации нормального поведения имеют общие черты с РАС и могут быть ошибочно диагностированы как РАС []. Неправильный диагноз РАС и, следовательно, потенциально неправильное применение терапии, связанной с РАС, увеличивают экономическое бремя. И наоборот, отсроченная или пропущенная диагностика РАС у детей, отвечающих диагностическим критериям, что, по-видимому, представляет собой особую проблему для определенных социально-демографических [] и клинических групп [], приводит к задержке в получении услуг и подвергает детей риску худших исходов.
Стоимость диагностики и лечения РАС растет вместе с ростом распространенности. Недавнее исследование предсказало, что стоимость лечения вырастет до 461 миллиарда долларов США в 2025 году, если уровень распространенности РАС останется неизменным на нынешнем уровне, и что расходы вырастут до 1 триллиона долларов США к 2025 году, если уровень распространенности РАС продолжит резко расти, как это видно из предыдущего исследования. последнее десятилетие [].Однако были высказаны опасения относительно точности и достоверности заявленного увеличения распространенности РАС, поскольку многие другие нейроповеденческие состояния, а также вариации нормального поведения имеют общие черты с РАС и могут быть ошибочно диагностированы как РАС []. Неправильный диагноз РАС и, следовательно, потенциально неправильное применение терапии, связанной с РАС, увеличивают экономическое бремя. И наоборот, отсроченная или пропущенная диагностика РАС у детей, отвечающих диагностическим критериям, что, по-видимому, представляет собой особую проблему для определенных социально-демографических [] и клинических групп [], приводит к задержке в получении услуг и подвергает детей риску худших исходов. Следовательно, надлежащая и ранняя диагностика и вмешательство в отношении РАС имеют решающее значение для улучшения прогнозов и снижения экономических затрат.
Следовательно, надлежащая и ранняя диагностика и вмешательство в отношении РАС имеют решающее значение для улучшения прогнозов и снижения экономических затрат.
РАС в настоящее время диагностируется в основном с помощью подходов, основанных на клиническом поведении, которые включают стандартизированные инструменты, такие как Шкала наблюдения за аутизмом и пересмотренная шкала диагностического интервью. Однако этот подход субъективен и требует много времени []. Хотя сообщалось, что РАС имеет прочную генетическую основу, генетические маркеры в настоящее время не используются в диагностическом процессе, поскольку этиология РАС сложна, а полный набор генов, связанных с аутизмом, неясен.Поскольку магнитно-резонансная томография (МРТ) является широко используемым методом неинвазивного обследования для выявления аномалий головного мозга в клинической практике, большой интерес вызывает ее потенциал для улучшения или уточнения диагностического процесса РАС. В клиниках структурная МРТ (sMRI) успешно используется для облегчения диагностики или лечения объемных поражений, таких как опухоли [,]. Однако структурные изменения мозга при неврологических и психических расстройствах не так заметны, как опухоли; таким образом, клиницистам трудно обнаружить тонкие анатомические изменения в головном мозге.Многие исследования были сосредоточены на обнаружении нарушений функциональной связности в головном мозге с помощью функциональной МРТ (фМРТ). Действительно, исследователи изучили использование фМРТ для выявления РАС. Например, Гуо и др. [] Разработали модель глубокой нейронной сети, используя функциональные связи между областями мозга на основе фМРТ в состоянии покоя. Прайс и др. [] Объединили функции динамической функциональной связи в мультисетевом алгоритме для классификации детского аутизма. Хуанг и др. [] Объединили несколько функциональных сетей связи для диагностики РАС.Однако, хотя фМРТ может отображать церебральную гемодинамику с высоким пространственным разрешением, высокая стоимость может ограничивать его потенциал в качестве широко используемого диагностического инструмента ASD в клиниках [].
Однако структурные изменения мозга при неврологических и психических расстройствах не так заметны, как опухоли; таким образом, клиницистам трудно обнаружить тонкие анатомические изменения в головном мозге.Многие исследования были сосредоточены на обнаружении нарушений функциональной связности в головном мозге с помощью функциональной МРТ (фМРТ). Действительно, исследователи изучили использование фМРТ для выявления РАС. Например, Гуо и др. [] Разработали модель глубокой нейронной сети, используя функциональные связи между областями мозга на основе фМРТ в состоянии покоя. Прайс и др. [] Объединили функции динамической функциональной связи в мультисетевом алгоритме для классификации детского аутизма. Хуанг и др. [] Объединили несколько функциональных сетей связи для диагностики РАС.Однако, хотя фМРТ может отображать церебральную гемодинамику с высоким пространственным разрешением, высокая стоимость может ограничивать его потенциал в качестве широко используемого диагностического инструмента ASD в клиниках []. Что еще более важно, трудно интерпретировать результаты, основанные на функциональной связности, из-за влияния базовой структуры мозга, когнитивного состояния и движения субъекта во время сбора данных []. Более того, недавнее исследование показало, что статистическое программное обеспечение, используемое для анализа необработанных данных с фМРТ, может иметь серьезные недостатки [].
Что еще более важно, трудно интерпретировать результаты, основанные на функциональной связности, из-за влияния базовой структуры мозга, когнитивного состояния и движения субъекта во время сбора данных []. Более того, недавнее исследование показало, что статистическое программное обеспечение, используемое для анализа необработанных данных с фМРТ, может иметь серьезные недостатки [].
По сравнению с фМРТ, sMRI имеет меньше требований к данным, чаще используется в клинических условиях и более подходит для групп населения, для которых соблюдение режима является проблемой, поскольку его можно проводить под седацией. Во многих исследованиях ASD sMRI использовались морфометрические характеристики, такие как площадь поверхности мозга, объем и толщина, чтобы отличить ASD от контрольных изображений [,]. Например, недавнее исследование младенцев с высоким риском РАС обнаружило гиперэкспансию площади поверхности коры и увеличенные объемы мозга у тех, кому позже был поставлен диагноз РАС []. Кроме того, в некоторых исследованиях были сделаны успехи в выяснении морфологии мозга с РАС. В частности, Bigler et al [] наблюдали различия в лобной доле, теменной доле, височной доле, лимбической системе и структурах мозжечка у пациентов с РАС по сравнению со здоровыми людьми из контрольной группы.
Кроме того, в некоторых исследованиях были сделаны успехи в выяснении морфологии мозга с РАС. В частности, Bigler et al [] наблюдали различия в лобной доле, теменной доле, височной доле, лимбической системе и структурах мозжечка у пациентов с РАС по сравнению со здоровыми людьми из контрольной группы.
Сопутствующие работы
Хотя изображения sMRI могут предоставить информацию об анатомических изменениях головного мозга, ошибки в интерпретации могут возникать из-за трудности проверки этих тонких изменений только визуальным осмотром.Кроме того, поскольку среди людей с РАС существует значительная генетическая, фенотипическая и клиническая неоднородность, одних только этих морфометрических признаков недостаточно для диагностики РАС в клинических условиях, учитывая, что каждая отдельная особенность вряд ли будет присутствовать у всех лиц с РАС. критерии. Для устранения таких препятствий в последние годы были разработаны алгоритмы машинного обучения для выявления основных паттернов изменений мозга при других нейроповеденческих состояниях, отмеченных аналогичной степенью неоднородности. При применении алгоритмов машинного обучения к данным sMRI сначала необходимо извлечь функции изображения, представляющие изображение sMRI. Некоторые из этих функций адаптированы из традиционных подходов к морфологии, а другие разработаны специально для подходов к машинному обучению. Традиционные морфометрические признаки можно разделить на область интереса (ROI), морфометрию на основе вокселей (VBM) [], морфометрию на основе поверхности (SBM) [], морфометрию на основе деформации (DBM) [] и морфометрию на основе тензорного анализа. (TBM) [,].К сожалению, подходы ROI, VBM, SBM, DBM и TBM имеют значительные ограничения. Из-за того, что требуется ручное или полуручное разграничение областей мозга, процесс ROI может быть трудоемким и длительным []. Производительность методов VBM, DBM и TBM очень чувствительна к точности регистрации, которую трудно достичь [], и зависит от регистрации деформации, которая может вызвать проблемы с чрезмерным выравниванием []. Метод SBM не позволяет выявить подкорковые структуры, такие как миндалевидное тело и базальные ганглии, которые могут играть решающую роль в РАС [].
При применении алгоритмов машинного обучения к данным sMRI сначала необходимо извлечь функции изображения, представляющие изображение sMRI. Некоторые из этих функций адаптированы из традиционных подходов к морфологии, а другие разработаны специально для подходов к машинному обучению. Традиционные морфометрические признаки можно разделить на область интереса (ROI), морфометрию на основе вокселей (VBM) [], морфометрию на основе поверхности (SBM) [], морфометрию на основе деформации (DBM) [] и морфометрию на основе тензорного анализа. (TBM) [,].К сожалению, подходы ROI, VBM, SBM, DBM и TBM имеют значительные ограничения. Из-за того, что требуется ручное или полуручное разграничение областей мозга, процесс ROI может быть трудоемким и длительным []. Производительность методов VBM, DBM и TBM очень чувствительна к точности регистрации, которую трудно достичь [], и зависит от регистрации деформации, которая может вызвать проблемы с чрезмерным выравниванием []. Метод SBM не позволяет выявить подкорковые структуры, такие как миндалевидное тело и базальные ганглии, которые могут играть решающую роль в РАС []. Чтобы устранить ограничение традиционных функций изображения, обсуждавшееся ранее, локальные функции изображения, разработанные специально для подходов к машинному обучению, такие как масштабно-инвариантное преобразование функций (SIFT) [], не зависят от точной регистрации деформации. Предполагается, что SIFT инвариантен к перемещению, масштабированию и повороту изображения и устойчив к локальным геометрическим искажениям, которые уже применялись для анализа изображений мозга [, -]. Однако у самого SIFT есть несколько недостатков. Хотя SIFT может повысить точность классификации по сравнению с традиционными функциями морфометрии, он использует разработанный экспертами подход для выявления визуально значимых изменений, которые могут не иметь отношения к заболеванию.Более того, SIFT может описывать характеристики только ограниченного числа ключевых точек и регионов вокруг ключевых точек. Однако, учитывая, что аномальные области мозга при нарушениях / заболеваниях нервной системы могут возникать в любом положении и могут быть очень маленькими, они могут быть не замечены модальностью SIFT.
Чтобы устранить ограничение традиционных функций изображения, обсуждавшееся ранее, локальные функции изображения, разработанные специально для подходов к машинному обучению, такие как масштабно-инвариантное преобразование функций (SIFT) [], не зависят от точной регистрации деформации. Предполагается, что SIFT инвариантен к перемещению, масштабированию и повороту изображения и устойчив к локальным геометрическим искажениям, которые уже применялись для анализа изображений мозга [, -]. Однако у самого SIFT есть несколько недостатков. Хотя SIFT может повысить точность классификации по сравнению с традиционными функциями морфометрии, он использует разработанный экспертами подход для выявления визуально значимых изменений, которые могут не иметь отношения к заболеванию.Более того, SIFT может описывать характеристики только ограниченного числа ключевых точек и регионов вокруг ключевых точек. Однако, учитывая, что аномальные области мозга при нарушениях / заболеваниях нервной системы могут возникать в любом положении и могут быть очень маленькими, они могут быть не замечены модальностью SIFT.
Учитывая вышеупомянутые ограничения в традиционных функциях изображения, а также в SIFT, еще одна заметная функция локального изображения, называемая гистограммой ориентированных градиентов (HOG) [], широко использовалась в приложениях компьютерного зрения (например, обнаружение человека [,], классификация транспортных средств [ ,], обнаружение дорожных знаков [], оценка позы [] и общая классификация изображений []).Поскольку HOG может хорошо описывать распределение градиентов интенсивности или направления краев, он полезен для характеристики внешнего вида и формы локального объекта []. Кроме того, поскольку функции HOG могут фильтровать большую часть несущественной информации (например, постоянный цветной фон), обеспечивая вывод нескольких двумерных гистограмм для области мозга, чтобы отразить изменения в области мозга, функции HOG хорошо отражают небольшие или тонкие аномалии, которые SIFT может игнорировать. В предыдущих исследованиях HOG обычно использовался для описания 2D-изображений.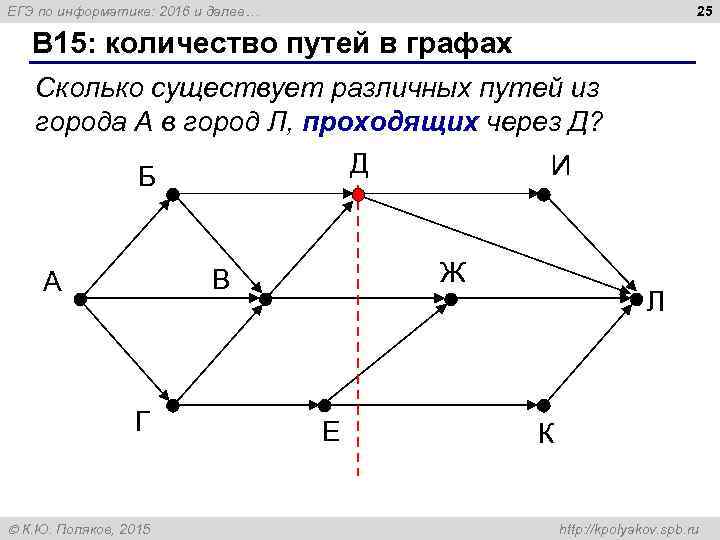 Хотя 2D HOG можно применить к 3D-изображению, 3D-изображение необходимо разрезать на серию 2D-изображений по определенной ориентации, что может быть проблематичным, поскольку изменения, вызванные болезнью, могут быть очевидны только в определенных ориентациях. К счастью, недавно разработанный метод, называемый 3D HOG, можно анализировать непосредственно внутри объемного трехмерного изображения, что позволяет сохранять информацию о градиенте изображения для аномальной области в более разборчивой трехмерной форме и, следовательно, повышает эффективность классификации.
Хотя 2D HOG можно применить к 3D-изображению, 3D-изображение необходимо разрезать на серию 2D-изображений по определенной ориентации, что может быть проблематичным, поскольку изменения, вызванные болезнью, могут быть очевидны только в определенных ориентациях. К счастью, недавно разработанный метод, называемый 3D HOG, можно анализировать непосредственно внутри объемного трехмерного изображения, что позволяет сохранять информацию о градиенте изображения для аномальной области в более разборчивой трехмерной форме и, следовательно, повышает эффективность классификации.
Objectives
Для решения уникальных проблем, присущих исследованиям нейровизуализации РАС, мы поэтому предложили новую двухуровневую структуру классификации, называемую морфометрией на основе гистограмм (HBM), которая основана на методе извлечения признаков 3D HOG. Вместо обработки всего изображения мозга мы разделили весь мозг на несколько локальных областей с заданным размером, что является основой нашей двухуровневой иерархической структуры. Классификатор первого уровня предназначен для локальных регионов, связанных с заболеванием или здоровым статусом, тогда как классификатор второго уровня или последний классификатор предназначен для всего мозга, который представлен конкатенацией статуса каждого региона.3D HOG вычисляется не для всего мозга, а для каждой локальной области мозга. Используя структуру классификации HBM, мы можем классифицировать людей как пациентов с РАС или здоровых людей из контрольной группы. Более того, можно вычислить классификационный вклад каждого локального признака HOG, и те признаки, которые вносят наибольший вклад в результат классификации заболевания, можно использовать для различения прогностических областей мозга, связанных с РАС.
Классификатор первого уровня предназначен для локальных регионов, связанных с заболеванием или здоровым статусом, тогда как классификатор второго уровня или последний классификатор предназначен для всего мозга, который представлен конкатенацией статуса каждого региона.3D HOG вычисляется не для всего мозга, а для каждой локальной области мозга. Используя структуру классификации HBM, мы можем классифицировать людей как пациентов с РАС или здоровых людей из контрольной группы. Более того, можно вычислить классификационный вклад каждого локального признака HOG, и те признаки, которые вносят наибольший вклад в результат классификации заболевания, можно использовать для различения прогностических областей мозга, связанных с РАС.
В этом документе представлена разработка методов 3D HOG и HBM, а также их применение к наборам данных ASD.В разделе «Методы» мы описали источник данных, предварительную обработку данных, проектирование функций 3D HOG, разработку двухуровневой структуры HBM и экспериментальный план. В разделе «Результаты» мы обсудили результаты экспериментов, полученные на основе анализа данных второго издания программы обмена данными визуализации аутистического мозга (ABIDE II) []. В заключение мы проанализировали контекст наших результатов и обсудили перспективы будущих исследований нейровизуализации РАС.
В разделе «Результаты» мы обсудили результаты экспериментов, полученные на основе анализа данных второго издания программы обмена данными визуализации аутистического мозга (ABIDE II) []. В заключение мы проанализировали контекст наших результатов и обсудили перспективы будущих исследований нейровизуализации РАС.
Методы
Сбор и предварительная обработка данных
В этом исследовании мы использовали данные sMRI из ABIDE II, которые включают 19 наборов данных, собранных на 18 участках (2 набора данных были собраны на одном участке) и 1114 субъектов (521 пациент с РАС и 593 здоровых контроля).Для каждого субъекта наборы данных ABIDE II состоят из изображений fMRI в состоянии покоя, изображений sMRI, взвешенных по T1, и фенотипической информации. Некоторые сайты также включают данные визуализации тензора диффузии, которые могут быть использованы для исследования структурных аномалий белого вещества. В качестве расширения к первому изданию наборов данных по обмену данными визуализации мозга при аутизме (ABIDE I), ABIDE II обеспечивает более полную фенотипическую характеристику, чем данные ABIDE I, чтобы лучше рассмотреть 2 основных источника неоднородности: сопутствующие психические заболевания и процент женщин в выборке [ ]. Критерии включения и диагностики для пациентов с РАС и здоровых людей в контрольной группе различаются в зависимости от центра, и детали критериев описаны в исследовании Martino et al []. Из 17 наборов данных мы выбрали 4 набора данных, собранных с 4 сайтов, включая ETH Zürich (ETH), NYU Langone Medical Center: Sample 1 (NYU), Орегонский университет здравоохранения и науки (OHSU) и Стэнфордский университет (SU). Для этого анализа использовались данные 119 пациентов с РАС и 131 здорового человека в контрольной группе из этих 4 центров.перечисляет образец обзора для каждого сайта. Возраст является важным фактором, который может влиять на различные характеристики, например толщину коркового слоя мозга при РАС. Чтобы оценить применимость предлагаемого нами метода HBM к различным возрастным диапазонам, мы выбрали 4 набора данных, которые представляют различные возрастные распределения среди всех наборов данных. В частности, чтобы уменьшить влияние неоднородности данных из нескольких сайтов, мы сначала использовали данные из одного сайта для оценки эффективности классификации моделей.
Критерии включения и диагностики для пациентов с РАС и здоровых людей в контрольной группе различаются в зависимости от центра, и детали критериев описаны в исследовании Martino et al []. Из 17 наборов данных мы выбрали 4 набора данных, собранных с 4 сайтов, включая ETH Zürich (ETH), NYU Langone Medical Center: Sample 1 (NYU), Орегонский университет здравоохранения и науки (OHSU) и Стэнфордский университет (SU). Для этого анализа использовались данные 119 пациентов с РАС и 131 здорового человека в контрольной группе из этих 4 центров.перечисляет образец обзора для каждого сайта. Возраст является важным фактором, который может влиять на различные характеристики, например толщину коркового слоя мозга при РАС. Чтобы оценить применимость предлагаемого нами метода HBM к различным возрастным диапазонам, мы выбрали 4 набора данных, которые представляют различные возрастные распределения среди всех наборов данных. В частности, чтобы уменьшить влияние неоднородности данных из нескольких сайтов, мы сначала использовали данные из одного сайта для оценки эффективности классификации моделей. Затем мы объединили все данные из 4 наборов данных, чтобы оценить способность модели справляться с неоднородностью данных.
Затем мы объединили все данные из 4 наборов данных, чтобы оценить способность модели справляться с неоднородностью данных.
Поскольку данные ABIDE II являются исходными изображениями Digital Imaging and Communications in Medicine (DICOM), на первом этапе предварительной обработки данных мы использовали инструмент MRIcron для преобразования изображений DICOM в изображения NifTI. Затем обработка данных выполнялась с помощью SPM12 (Институт неврологии UCL Queen Square, Великобритания), который является сторонним пакетом для MATLAB (MathWorks, Натик, Массачусетс, США). Все преобразованные структурные изображения были сегментированы и нормализованы в стандартном пространстве Монреальского неврологического института (MNI).
Таблица 1. Обзор участников 4 обучающих наборов данных.| Индекс | Набор данных | ASD a , n (мужской / женский) | Здоровые контрольные, n (мужской / женский) | Возраст (лет), среднее (SD) | Возрастной диапазон (лет) |
| 1 | ETH b | 13 (13/0) | 24 (24/0) | 22,7 (4,4) | 14-31 |
| 2 | NYU c | 48 (43/5) | 30 (28/2) | 9. 8 (4,9) 8 (4,9) | 5,2-34,8 |
| 3 | OHSU d | 37 (30/7) | 56 (27/29) | 10,9 (2,0) | 7-15 |
| 4 | SU e | 21 (19/2) | 21 (19/2) | 11,1 (1,2) | 8-13 |
| 5 | Смешанный f | 119 105/14) | 131 (98/33) | 12,4 (5,6) | 5,2-34,8 |
a РАС: расстройство аутистического спектра.
b ETH: ETH Zürich.
c NYU: NYU Медицинский центр Langone: образец 1.
d OHSU: Орегонский университет здоровья и науки.
e SU: Стэнфордский университет.
f Смешанный: набор данных, объединяющий данные из всех 4 наборов данных.
Разработка трехмерной гистограммы ориентированных градиентов Функция
В процессе расширения концепции HOG с двухмерного пространства на трехмерное нам потребовалось определить методы расчета градиента изображения (включая направление и величину) и разделения градиента. направления в несколько интервалов ориентации (или каналов) в трехмерном пространстве.Направления градиента в трехмерном пространстве были представлены с использованием двух углов, тета и фи, как показано на. Затем градиент каждого вокселя изображения вычисляется на основе этих двух углов (см. Подробнее).
Подобно 2D HOG, направление градиента в 3D HOG также необходимо было разделить на несколько интервалов ориентации. Разница заключается в том, что перегородки в 2D HOG разбросаны на 360 ° только в одной 2D плоскости, в то время как перегородки в 3D HOG разбросаны по всему объемному пространству.Существует множество схем разделения для разделения ориентировочного пространства. Мы ввели 2 схемы разбиения следующим образом.
Разница заключается в том, что перегородки в 2D HOG разбросаны на 360 ° только в одной 2D плоскости, в то время как перегородки в 3D HOG разбросаны по всему объемному пространству.Существует множество схем разделения для разделения ориентировочного пространства. Мы ввели 2 схемы разбиения следующим образом.
Первая схема состоит в том, чтобы выделить интервалы ориентации в горизонтальном и вертикальном направлениях с диапазонами углов равного пространства, такими как 2D HOG, и каждая ограниченная область между двумя направлениями рассматривается как один 3D-раздел. Результаты разбиения показаны в.
Когда каждая область перегородки проецируется на поверхность сферы, они соответствуют площади поверхности между линиями широты и долготы.Для этой схемы разделения количество интервалов ориентации, которое равно размерному числу элементов 3D HOG, вычисляется с использованием следующего уравнения в: где N DIR3 — количество направлений в трехмерном пространстве, а N DIR2 — это количество направлений в 2D-пространстве.
В части (a) для перегородок возле опор небольшое изменение углов приведет к другому назначению ячейки ориентации. Это приводит к чрезмерной чувствительности элементов к разнице углов в некоторых, но не во всех направлениях.Чтобы избежать потенциальной потери производительности из-за этого явления, мы предложили дополнительную схему разделения, в которой разделы, прилегающие к полюсным точкам, объединены в 1 раздел, как показано в части (b).
Количество интервалов ориентации для этой второй схемы разделения, которая объединяет области направления около полюса в одно направление, рассчитывается с использованием уравнения в:
Для удобства расчета значение N DIR2 равно должно быть четным числом.Например, если для N DIR2 установлено значение 8, N DIR3 будет 32, как вычислено в первой схеме, а во второй схеме N DIR3 будет равно 26.
Рисунок 1. Два угла, связанных с вычислением направления градиента в трехмерном пространстве. Посмотрите на этот рисунок Рисунок 2. Две схемы разбиения бинов ориентации в трехмерном пространстве. Посмотреть этот рисунок
Посмотрите на этот рисунок Рисунок 2. Две схемы разбиения бинов ориентации в трехмерном пространстве. Посмотреть этот рисунокОбщая структура классификации
В этой статье мы предложили двухуровневую структуру классификации HBM, основанную на функциях 3D HOG, чтобы различать пациентов с РАС и здоровых людей из контрольной группы.Каждое изображение мозга сначала было разделено на плотно перекрывающуюся сетку региональных ячеек, и была рассчитана функция 3D HOG для каждой ячейки. На основе разделения мозга мы разработали алгоритм классификации первого уровня, чтобы предсказать, предоставляет ли данная клетка убедительные доказательства в поддержку окончательной классификации болезни / здоровья. Поскольку для каждой ячейки нет метки, был использован алгоритм кластеризации, чтобы сначала найти метки для каждой ячейки (подробности обсуждаются в следующих разделах).Затем была использована классификация второго уровня, чтобы составить окончательную классификацию на основе всех свидетельств из каждой ячейки. показывает двухуровневую структуру классификации с использованием примера двухмерного изображения для удобной иллюстрации. Правая нижняя часть рисунка представляет процесс тестирования, а оставшаяся часть показывает процесс обучения.
показывает двухуровневую структуру классификации с использованием примера двухмерного изображения для удобной иллюстрации. Правая нижняя часть рисунка представляет процесс тестирования, а оставшаяся часть показывает процесс обучения.
Этапы алгоритма
Разделение изображения мозга и извлечение локальных признаков
Перед этапом извлечения признаков мы сначала разделили все трехмерное МРТ-изображение мозга на региональные клетки на этапе 1.Этот метод деления мозга можно применять не только к объемным изображениям 3D МРТ, на которых региональная клетка приравнивается к кубу , но и к срезам 2D МРТ, в которых региональная клетка приравнивается к квадрату . В нашем алгоритме мы вычислили признак HOG для каждой ячейки, но не собрали его в комбинированный вектор признаков, используемый для представления всего изображения. При стандартном использовании HOG все локальные особенности HOG были объединены в многомерный вектор признаков, используемый в качестве входных данных для классификатора []. В нашей иерархической структуре классификации эти локальные характеристики были преобразованы в высокоуровневые формы, которые могут уменьшить размерность функций, вводимых в окончательный классификатор, что дает преимущество сокращения переобучения в относительно небольших наборах данных, которые часто доступны в медицинских учреждениях. исследования. Кроме того, использование локальных особенностей полезно для выявления связанных с РАС областей мозга, которые имеют большой вклад в результат классификации заболевания. При делении изображения размер ячейки и процент перекрытия ячеек — это два важных параметра, которые влияют на точность классификации.Следовательно, необходимо оценить различные схемы разделения изображений мозга, чтобы определить, какая из них лучше всего подходит для классификации.
В нашей иерархической структуре классификации эти локальные характеристики были преобразованы в высокоуровневые формы, которые могут уменьшить размерность функций, вводимых в окончательный классификатор, что дает преимущество сокращения переобучения в относительно небольших наборах данных, которые часто доступны в медицинских учреждениях. исследования. Кроме того, использование локальных особенностей полезно для выявления связанных с РАС областей мозга, которые имеют большой вклад в результат классификации заболевания. При делении изображения размер ячейки и процент перекрытия ячеек — это два важных параметра, которые влияют на точность классификации.Следовательно, необходимо оценить различные схемы разделения изображений мозга, чтобы определить, какая из них лучше всего подходит для классификации.
На шаге 2 мы извлекли локальные объекты HOG, используя 2 разные схемы разделения направления градиента: HOG-32 и HOG-26, как показано в частях (a) и (b) соответственно. Сравнение этих двух схем также необходимо, чтобы определить, какая из них имеет лучшую производительность. Следует отметить, что лучшая производительность классификации с использованием алгоритма 3D HOG обычно является результатом сканирования МРТ с высоким пространственным разрешением, в то время как производительность алгоритма 3D HOG может ухудшаться, если сканирование МРТ имеет низкое пространственное разрешение.В этом случае можно использовать альтернативный алгоритм 2D HOG.
Следует отметить, что лучшая производительность классификации с использованием алгоритма 3D HOG обычно является результатом сканирования МРТ с высоким пространственным разрешением, в то время как производительность алгоритма 3D HOG может ухудшаться, если сканирование МРТ имеет низкое пространственное разрешение.В этом случае можно использовать альтернативный алгоритм 2D HOG.
Обучение локальной кластеризации функций и региональному классификатору
На шаге 3 мы работали над каждой ячейкой независимо. Для каждой ячейки цель состояла в том, чтобы найти двоичное представление, чтобы указать, связано ли это со статусом болезни или здоровым статусом. Однако у нас не было метки класса для каждой ячейки. Хотя метка класса всего мозга известна в обучающих выборках, это не означает, что каждая ячейка должна иметь такую же метку класса, что и весь мозг.Даже у больного человека в мозгу может быть много клеток, которые выглядят совершенно нормально. Из-за неизвестной метки класса для каждой ячейки мы применили алгоритм кластеризации к обучающим выборкам, чтобы получить метки классов отдельных ячеек. Поскольку распределение кластеров неизвестно, мы попробовали 2 разных алгоритма кластеризации, такие как K-среднее и иерархическая кластеризация, которые подходят для разных распределений кластеров. Хотя алгоритм кластеризации хорошо работает на этапе обучения, мы предложили использовать алгоритм классификации для генерации двоичного представления на этапе тестирования.Причина, по которой мы использовали классификацию вместо кластеризации на этапе тестирования, заключалась в том, что нам не нужно было сохранять все функции обучения при использовании подхода для прогнозирования, что делает метод более масштабируемым и практичным. Таким образом, на основе меток кластеризации ячеек в обучающих выборках мы построили региональные классификаторы на шаге 4 для прогнозирования статуса ячеек тестовых выборок. Когда для кластеризации используется алгоритм K-средних, результирующие кластеры обычно имеют сферическую форму в пространстве признаков, а центроиды являются хорошими примерами для соответствующих кластеров.
Поскольку распределение кластеров неизвестно, мы попробовали 2 разных алгоритма кластеризации, такие как K-среднее и иерархическая кластеризация, которые подходят для разных распределений кластеров. Хотя алгоритм кластеризации хорошо работает на этапе обучения, мы предложили использовать алгоритм классификации для генерации двоичного представления на этапе тестирования.Причина, по которой мы использовали классификацию вместо кластеризации на этапе тестирования, заключалась в том, что нам не нужно было сохранять все функции обучения при использовании подхода для прогнозирования, что делает метод более масштабируемым и практичным. Таким образом, на основе меток кластеризации ячеек в обучающих выборках мы построили региональные классификаторы на шаге 4 для прогнозирования статуса ячеек тестовых выборок. Когда для кластеризации используется алгоритм K-средних, результирующие кластеры обычно имеют сферическую форму в пространстве признаков, а центроиды являются хорошими примерами для соответствующих кластеров. Поэтому в данном случае использовался метод классификации ближайшего центроида. Если для кластеризации используется иерархический алгоритм, центроиды кластеров могут не представлять кластер, и, следовательно, ближайший классификатор центроидов не подходит. В этом случае машину опорных векторов (SVM) можно использовать для построения региональных классификаторов для тестовых выборок.
Поэтому в данном случае использовался метод классификации ближайшего центроида. Если для кластеризации используется иерархический алгоритм, центроиды кластеров могут не представлять кластер, и, следовательно, ближайший классификатор центроидов не подходит. В этом случае машину опорных векторов (SVM) можно использовать для построения региональных классификаторов для тестовых выборок.
Компактное представление признаков и окончательная подготовка классификатора
Обозначенные локальные особенности отражают только состояние областей мозга, а не полную картину характеристик мозга.Поэтому на шаге 5 мы объединили каждый статус локальной функции одного изображения мозга в новое высокоуровневое компактное представление функции этого изображения. Для обучения модели мы построили высокоуровневую функцию, напрямую объединив результаты кластеризации, полученные на шаге 4. Следует отметить, что результат кластеризации каждой функции был объединен в соответствии с определенной последовательностью, например, от верхнего левого угла к нижнему правому. на сетке. Такая последовательность фактически определяется алгоритмом извлечения признаков HOG, и такая же последовательность также используется при конкатенации двоичного статуса признаков HOG, тем самым обеспечивая единое значение представления признаков для всех выборок.На основе нового представления признаков и диагностических меток обучающих данных мы обучили окончательный классификатор с использованием метода классификации SVM на шаге 6. SVM — один из наиболее широко используемых классификаторов, который может выполнять не только линейную, но и нелинейную классификацию. []. Его уже применяли для лечения различных заболеваний и нарушений развития нервной системы, например, болезни Паркинсона [], болезни Альцгеймера [,], РАС [,], синдрома дефицита внимания / гиперактивности [] и шизофрении [].
на сетке. Такая последовательность фактически определяется алгоритмом извлечения признаков HOG, и такая же последовательность также используется при конкатенации двоичного статуса признаков HOG, тем самым обеспечивая единое значение представления признаков для всех выборок.На основе нового представления признаков и диагностических меток обучающих данных мы обучили окончательный классификатор с использованием метода классификации SVM на шаге 6. SVM — один из наиболее широко используемых классификаторов, который может выполнять не только линейную, но и нелинейную классификацию. []. Его уже применяли для лечения различных заболеваний и нарушений развития нервной системы, например, болезни Паркинсона [], болезни Альцгеймера [,], РАС [,], синдрома дефицита внимания / гиперактивности [] и шизофрении [].
Процесс классификации тестовой выборки
Вышеупомянутые шаги описывают весь процесс обучения для получения двухуровневых моделей классификации, включая региональный классификатор и окончательный классификатор. Затем мы могли бы применить эти классификаторы к неизвестным тестовым образцам. Во-первых, трехмерные локальные особенности HOG клеток на тестовом изображении мозга извлекаются тем же методом, что и в процессе обучения. Затем региональные классификаторы, такие как ближайший центроид, используются для классификации каждого локального объекта HOG по меткам, связанным с заболеванием или здоровьем.Эти метки затем объединяются для создания компактного представления этого тестового изображения. Наконец, последний классификатор применяется для прогнозирования того, является ли тестируемая выборка пациентом с РАС, используя компактный вектор признаков в качестве входных данных для модели классификации.
Затем мы могли бы применить эти классификаторы к неизвестным тестовым образцам. Во-первых, трехмерные локальные особенности HOG клеток на тестовом изображении мозга извлекаются тем же методом, что и в процессе обучения. Затем региональные классификаторы, такие как ближайший центроид, используются для классификации каждого локального объекта HOG по меткам, связанным с заболеванием или здоровьем.Эти метки затем объединяются для создания компактного представления этого тестового изображения. Наконец, последний классификатор применяется для прогнозирования того, является ли тестируемая выборка пациентом с РАС, используя компактный вектор признаков в качестве входных данных для модели классификации.
Расчет вклада характеристик
Помимо использования структуры HBM для классификации тестовой выборки, мы также могли бы исследовать вклад каждой характеристики каждой ячейки в предсказание алгоритма того, что каждый участник является пациентом с РАС, а не здоровым контрольным человеком. Более высокое значение вклада признака указывает на большую вероятность того, что клетка связана с заболеванием. Поскольку мы использовали метод SVM на окончательном уровне классификации, вклад признаков можно было рассчитать на основе коэффициентов линейного классификатора SVM. Однако этот метод может вызвать проблемы, поскольку мы не знаем, какая кластерная метка представляет статус заболевания. Таким образом, мы выбрали наивный байесовский подход для вычисления вклада характеристик для обеих кластеризованных меток. В самом строгом смысле вклад функции , вычисленный методом Наивного Байеса, следует называть важностью функции , что отражает только вклад функции, учитывая, что последний классификатор является классификатором Наивного Байеса.В будущих исследованиях мы рассмотрим более интерпретируемое отображение от местных особенностей до окончательных результатов классификации.
Более высокое значение вклада признака указывает на большую вероятность того, что клетка связана с заболеванием. Поскольку мы использовали метод SVM на окончательном уровне классификации, вклад признаков можно было рассчитать на основе коэффициентов линейного классификатора SVM. Однако этот метод может вызвать проблемы, поскольку мы не знаем, какая кластерная метка представляет статус заболевания. Таким образом, мы выбрали наивный байесовский подход для вычисления вклада характеристик для обеих кластеризованных меток. В самом строгом смысле вклад функции , вычисленный методом Наивного Байеса, следует называть важностью функции , что отражает только вклад функции, учитывая, что последний классификатор является классификатором Наивного Байеса.В будущих исследованиях мы рассмотрим более интерпретируемое отображение от местных особенностей до окончательных результатов классификации.
Сначала мы представим наивный байесовский подход, основанный на теореме Байеса. Этот подход широко используется для классификации во многих областях благодаря своей простоте и высокой производительности. Предполагается, что прогностические признаки X 0 , X 1 ,…, X n не зависят друг от друга с учетом состояния переменной класса Y .Хотя трудно уменьшить зависимость для анализа нейровизуализации, потому что различные области мозга во многом коррелированы по своей природе, эмпирические наблюдения показали, что наивный байесовский метод работает достаточно хорошо, даже когда существует зависимость между характеристиками []. Поэтому мы использовали теорему Байеса для получения апостериорной вероятности P ( Y | X 0 , X 1 ,…, X n ) следующим образом:
Предполагается, что прогностические признаки X 0 , X 1 ,…, X n не зависят друг от друга с учетом состояния переменной класса Y .Хотя трудно уменьшить зависимость для анализа нейровизуализации, потому что различные области мозга во многом коррелированы по своей природе, эмпирические наблюдения показали, что наивный байесовский метод работает достаточно хорошо, даже когда существует зависимость между характеристиками []. Поэтому мы использовали теорему Байеса для получения апостериорной вероятности P ( Y | X 0 , X 1 ,…, X n ) следующим образом:
, где X i ∈ {0, 1} представляет результат кластеризации ячеек i -го, а Y ∈ { D , H } представляет метку обучающей выборки.Кроме того, P D и P H относятся к вероятности быть классифицированным как пациент с ASD по сравнению со здоровым контролем, соответственно, в зависимости от состояния каждой клетки.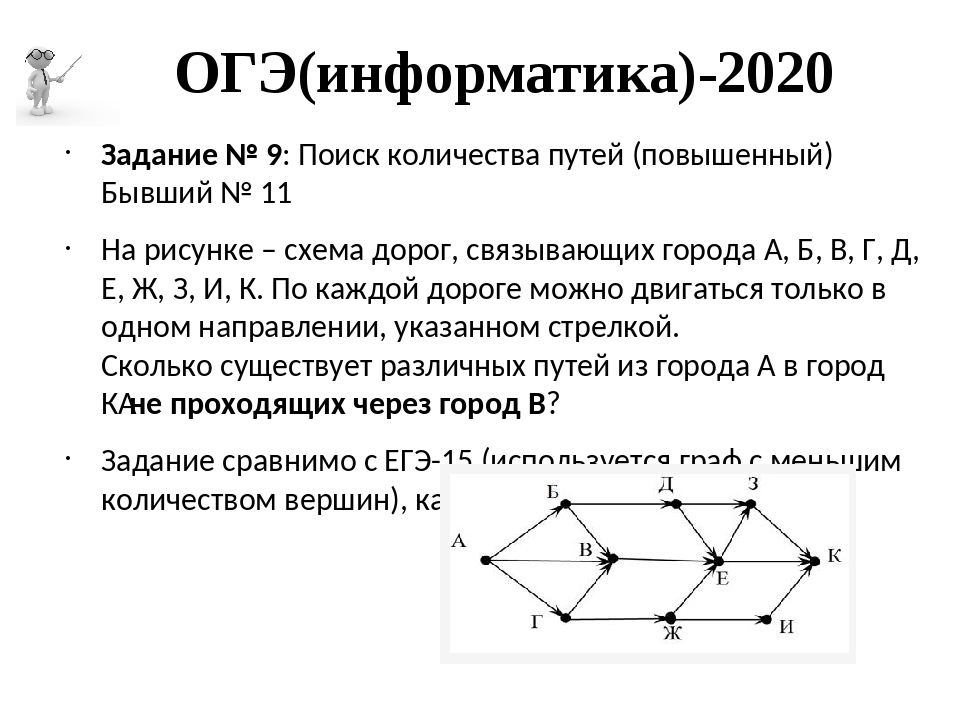 Если P D > P H , мы предсказали, что испытуемый образец с большей вероятностью будет пациентом с РАС, чем здоровым контролем. Чтобы избежать потери значимости в байесовских вычислениях, мы использовали коэффициент логарифма следующим образом:
Если P D > P H , мы предсказали, что испытуемый образец с большей вероятностью будет пациентом с РАС, чем здоровым контролем. Чтобы избежать потери значимости в байесовских вычислениях, мы использовали коэффициент логарифма следующим образом:
, где мы определили элемент логарифмической суммы как вклад функции в ячейку и .Более высокое значение этого элемента указывает на более предсказуемую функцию. Стоит отметить, что, поскольку мы не знали точно, какое состояние клетки (0 или 1) указывает на признак, связанный с заболеванием, и эти 2 состояния признаков могут оба вносить вклад в заболевание, мы рассчитали вклад обоих признаков.
Затем, в соответствии с результатами классификации первого уровня каждой ячейки в выборке тестируемого пациента, могут быть идентифицированы наиболее прогностические признаки, значения вклада которых превышают предварительно установленный порог.Мы устанавливаем пороговое значение для включения функции, чтобы просто показать пациентам основные функции (в гипотетическом клиническом случае использования). Порог обычно устанавливается на разные значения при использовании разнородных данных sMRI с разных сайтов или когда значения параметров (например, размер ячейки и процент перекрытия ячеек) изменяются. Клетки, которые вносят наибольший вклад в результат классификации РАС, считаются областями-кандидатами, связанными с заболеванием.
Порог обычно устанавливается на разные значения при использовании разнородных данных sMRI с разных сайтов или когда значения параметров (например, размер ячейки и процент перекрытия ячеек) изменяются. Клетки, которые вносят наибольший вклад в результат классификации РАС, считаются областями-кандидатами, связанными с заболеванием.
Экспериментальный план
В двухуровневой структуре HBM мы оценили 2 различные схемы разделения направления трехмерного градиента, используя комбинации алгоритмов для кластеризации признаков, обучения региональному классификатору и окончательного обучения классификатора, перечисленные в.Производительность 4 экземпляров, перечисленных в таблице, будет сравнена позже. Имя экземпляра в таблице (например, KNS32) — это аббревиатура, созданная с использованием первой буквы имени алгоритма кластеризации локальных объектов (K-средних), имени алгоритма региональной классификации (ближайший центроид), имени окончательного алгоритма классификации (SVM). , и 32 ячейки ориентации.
После обучения окончательной модели классификации ее производительность оценивается, как правило, с помощью метода перекрестной проверки (CV).Широко используемые методы CV в анализе изображений мозга включают CV с исключением 1 [,,], CV с исключением 2 [,,], k-кратное CV [,] и стратифицированное k-кратное CV [,]. Хотя в литературе есть противоречивые сообщения, в большинстве работ, включая обзор методов классификации изображений мозга, предполагается, что 10-кратное CV является наиболее подходящим методом []. В этом исследовании мы обучили нашу модель, используя метод стратифицированного 10-кратного CV. Метод стратифицированного CV дает следующие преимущества. Во-первых, стратифицированный метод может поддерживать соотношение двух классов выборок в каждом сгибе как можно ближе к таковому для всех выборок, сохраняя исходный шаблон распределения данных для всего набора данных.Во-вторых, дисперсия оценок производительности модели будет уменьшаться за счет выполнения нескольких случайных прогонов, в каждом из которых все выборки сначала перемешиваются, а затем разделяются на пару обучающих и тестовых наборов. Предлагаемый в данной статье метод стратифицированного CV реализован в виде псевдокода, показанного на.
Предлагаемый в данной статье метод стратифицированного CV реализован в виде псевдокода, показанного на.
В схеме разбиения 3D HOG есть параметр N DIR2 , который представляет количество интервалов ориентации в горизонтальном или вертикальном направлении трехмерного пространства.Если значение N DIR2 слишком велико, скорость вычислений алгоритма будет замедлена. Однако, что более важно, функция будет более чувствительна к шуму и другим неинформативным сигналам на изображениях. Кроме того, размер элемента будет высоким, что обычно требует большего количества выборок, чтобы избежать проклятия размерности . В противном случае, если для N DIR2 установлено слишком низкое значение, детали изображения будут потеряны. В этой статье мы установили номер N DIR2 на часто используемое значение 8, а общее количество направлений в трехмерном пространстве составляло 32 и 26 для двух схем разбиения 3D HOG.Другие параметры для функций HOG, включая размер ячеек и процент перекрытия, оценивались с использованием метода CV. Показатели производительности, которые мы использовали для оценки нашего алгоритма, включали точность классификации, чувствительность, специфичность, положительную прогностическую ценность, отрицательную прогностическую ценность, оценку F1 и площадь под кривой (AUC).
Показатели производительности, которые мы использовали для оценки нашего алгоритма, включали точность классификации, чувствительность, специфичность, положительную прогностическую ценность, отрицательную прогностическую ценность, оценку F1 и площадь под кривой (AUC).
| Имя экземпляра | Элемент изображения | Обработка элемента изображения для каждой ячейки | Окончательная классификация | ||||||
| | | | | Класс кластеризации | 0 9120 9120 9205 9120 9205 9120 9120 9120 9205 KNS32 | HOG a -32 b | K-средних | Ближайший центроид | SVM c, d |
| KNS26 | HOG-2605 | Ne206 центроид | SVM c | ||||||
| HSS32 | HOG-32 b | Иерархический | Линейное ядро SVM | SVM c 6OG | OG 9120OG | Линейное ядро SVM | SVM c | ||
a HOG: гистограмма ориентированных градиентов.
b HOG-32 — это гистограмма ориентированных градиентов с 8 направлениями в 2D-плоскости и 32 направлениями в 3D-пространстве.
c Были протестированы три разных ядра, например, линейное ядро, полиномиальное ядро и ядро радиальной базовой функции.
d SVM: машина опорных векторов.
e HOG-26 — это элемент HOG с 8 направлениями в 2D-плоскости, и 2 полюса рассматриваются как 2 направления в 3D-пространстве; следовательно, всего направлений 26.
Рис. 4. Алгоритм стратифицированной перекрестной проверки с множественными случайными прогонами. Посмотреть этот рисунокРезультаты
Сравнение эффективности классификации различных экземпляров морфометрии на основе гистограмм
Для сравнения производительности 4 экземпляров HBM, перечисленных в, мы использовали метод оценки стратифицированного 10-кратного CV для получения каждого показателя эффективности. Поскольку размер ячейки и перекрытие двух ячеек могут влиять на производительность модели, мы выполнили сканирование параметров для поиска лучших значений этих двух параметров. Размер ячеек варьировался от 10 до 20 вокселей, а процент перекрытия ячеек находился в диапазоне от 20% до 50%. На последнем этапе классификации мы протестировали 3 различных ядра SVM, включая линейное ядро, полиномиальное ядро и ядро радиальной базовой функции. Затем мы выбрали линейное ядро для использования из-за его превосходной производительности.
Размер ячеек варьировался от 10 до 20 вокселей, а процент перекрытия ячеек находился в диапазоне от 20% до 50%. На последнем этапе классификации мы протестировали 3 различных ядра SVM, включая линейное ядро, полиномиальное ядро и ядро радиальной базовой функции. Затем мы выбрали линейное ядро для использования из-за его превосходной производительности.
показывает стратифицированную 10-кратную среднюю точность CV, основанную на данных с сайта NYU, при использовании разных экземпляров HBM и разных значений параметров.Расширенную форму сокращений экземпляров HBM в можно найти в. Из рисунка видно, что, хотя точность классификации колеблется при изменении значений параметров, KNS26 и KNS32 работают значительно лучше, чем HSS26 и HSS32, что означает, что комбинация алгоритмов K-средних и центроидов больше подходит для предлагаемого нами HBM. рамки. Между тем, показано, что KNS26 превзошел KNS32, а HSS26 превзошел HSS32, что подтверждает рациональность и эффективность схемы разделения HOG-26. Кроме того, среди различных значений параметров KNS26 получил наилучшую среднюю точность классификации, 74% (58/78), когда размер ячейки был установлен на 14 вокселей, а процент перекрытия ячеек был установлен на 50%. Для трех других сайтов, ETH, OHSU и SU, KNS26 также превзошел KNS32, хотя лучшие значения параметров могут отличаться (см. Результаты этих дополнительных анализов). Следует отметить, что наш метод не был слишком чувствителен к параметрам, поэтому производительность модели в целом была хорошей для широкого диапазона параметров.
Кроме того, среди различных значений параметров KNS26 получил наилучшую среднюю точность классификации, 74% (58/78), когда размер ячейки был установлен на 14 вокселей, а процент перекрытия ячеек был установлен на 50%. Для трех других сайтов, ETH, OHSU и SU, KNS26 также превзошел KNS32, хотя лучшие значения параметров могут отличаться (см. Результаты этих дополнительных анализов). Следует отметить, что наш метод не был слишком чувствителен к параметрам, поэтому производительность модели в целом была хорошей для широкого диапазона параметров.
Сравнение эффективности классификации различных алгоритмов выделения локальных признаков
В этой статье мы использовали алгоритм HOG для выделения признаков локального изображения в структуре HBM. Этот алгоритм помогает создавать высококачественные представления, отображающие края и текстуру изображения.Чтобы оценить влияние различных алгоритмов выделения локальных признаков на производительность классификации, мы также использовали SIFT, другой широко используемый алгоритм обнаружения локальных признаков, для извлечения признаков из изображений мозга и разработали подход SVM для анализа извлеченных признаков SIFT. Этот подход применялся к неврологическим заболеваниям, таким как болезнь Альцгеймера [,], болезнь Паркинсона [] и биполярная болезнь []. Как показано на рисунке, KNS26 был наиболее производительным экземпляром HBM, поэтому мы сравнили его (а не KNS32) с подходом SVM на основе SIFT.
Этот алгоритм помогает создавать высококачественные представления, отображающие края и текстуру изображения.Чтобы оценить влияние различных алгоритмов выделения локальных признаков на производительность классификации, мы также использовали SIFT, другой широко используемый алгоритм обнаружения локальных признаков, для извлечения признаков из изображений мозга и разработали подход SVM для анализа извлеченных признаков SIFT. Этот подход применялся к неврологическим заболеваниям, таким как болезнь Альцгеймера [,], болезнь Паркинсона [] и биполярная болезнь []. Как показано на рисунке, KNS26 был наиболее производительным экземпляром HBM, поэтому мы сравнили его (а не KNS32) с подходом SVM на основе SIFT.
Мы обучили оба классификатора, используя стратифицированное 10-кратное CV, и данные обучения были для них одинаковыми в каждом случае. Результаты показывают, что подход KNS26 HBM на основе HOG обеспечивает гораздо лучшую производительность, чем подход SVM на основе SIFT (и). В целом, результаты сравнения, представленные на изображениях, демонстрируют, что функции HOG больше подходят для определения основных структур структурных изменений в изображениях sMRI, чем функции SIFT. Преобразуя низкоуровневые признаки HOG в высокоуровневые, предлагаемая нами двухуровневая структура классификации HBM может эффективно использовать высокоуровневые признаки для дифференциации людей как пациентов с РАС, так и здоровых людей из контрольной группы.В последней строке мы видим, что производительность снизилась при построении модели на данных из 4 наборов данных. Причину мы обсуждали в разделе «Обсуждение».
Преобразуя низкоуровневые признаки HOG в высокоуровневые, предлагаемая нами двухуровневая структура классификации HBM может эффективно использовать высокоуровневые признаки для дифференциации людей как пациентов с РАС, так и здоровых людей из контрольной группы.В последней строке мы видим, что производительность снизилась при построении модели на данных из 4 наборов данных. Причину мы обсуждали в разделе «Обсуждение».
| Набор данных | Лучший параметр | Морфометрия на основе гистограммы | ACC a | SEN b | SPE c | PPV d | NPV e | F1 f | AUC30 5 9120 9 9120 9 9120 9 9120 9 9120 9206 | N | n (%) | N | n (%) | N | n (%) | N | n (%) | N | n (%) | | | |||||||||||||||||||||||||
| ETH h | 10 | 20 | 37 | 32 (86) | 13 | 10 (77) | 24 91 206 | 22 (92) | 12 | 10 (83) | 25 | 22 (88) | 0. 790 790 | 0,849 | ||||||||||||||||||||||||||||||||
| NYU i | 14 | 50 | 78 | 58 (74) | 48 | 40 (83) | 30 | 18 (60)40 (77) | 26 | 18 (69) | 0,805 | 0,787 | ||||||||||||||||||||||||||||||||||
| OHSU j | 19 | 40 | 93 | 70 (75) 23206 9120 | 9120 )56 | 46 (82) | 33 | 23 (70) | 60 | 46 (77) | 0.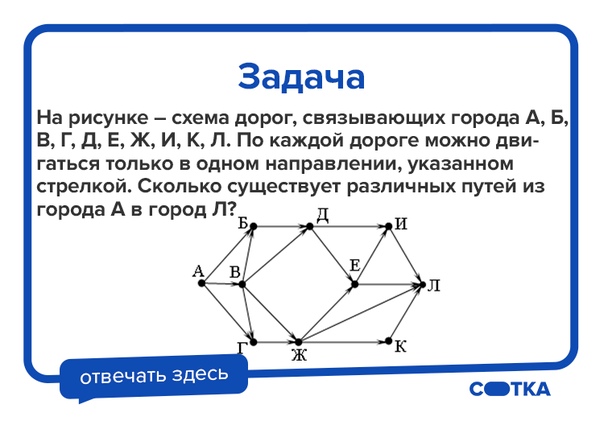 662 662 | 0,794 | ||||||||||||||||||||||||||||||||||
| SU k | 17 | 20 | 42 | 30 (71) | 21 | 17 (81) | 21 | 13 (62205 9120)9120 25 17 (68) | 17 | 13 (77) | 0,751 | 0,763 | ||||||||||||||||||||||||||||||||||
| смешанный л | 12 | 30 | 250 | 162 (65) | ) | 131 | 76 (58) | 142 | 87 (61) | 108 | 76 (70) | 0. 662 662 | 0,650 | |||||||||||||||||||||||||||||||||
a ACC: точность — это соотношение правильно классифицированных предметов по всем предметам.
b SEN: чувствительность — это отношение правильно классифицированных субъектов с расстройством аутистического спектра (РАС) ко всем субъектам с РАС.
c SPE: специфичность — это соотношение правильно классифицированных субъектов без РАС по всем субъектам без РАС.
d PPV: положительная прогностическая ценность — это соотношение правильно классифицированных субъектов с РАС по всем прогнозируемым субъектам с РАС.
e NPV: отрицательная прогностическая ценность — это соотношение правильно классифицированных субъектов без РАС по всем прогнозируемым субъектам без РАС.
f F1: счет F1.
г AUC: площадь под кривой.
ч ETH: ETH Zürich.
i NYU: NYU Медицинский центр Лангоне: образец 1.
j OHSU: Орегонский университет здоровья и науки.
k SU: Стэнфордский университет.
l Смешанный: набор данных, объединяющий данные из всех 4 наборов данных.
Таблица 4. Производительность классификации с использованием масштабно-инвариантного преобразования функций и поддержки векторной машины во втором издании наборов данных для обмена данными визуализации аутистического мозга.| Dataset | Performance с использованием масштабно-инвариантным функция преобразования и поддержка векторной машины | |||||||||||||
| | ACC с | SEN б | SPE c | PPV d | NPV e | F1 f | AUC g | |||||||
| | N | ) | N | n (%) | N | n (%) | N | n (%) | | | ||||
| ETH06 | ||||||||||||||
| ETH06 | ||||||||||||||
| 13 | 8 (62%) | 24 | 16 (67) | 16 | 8 (50) | 21 | 16 (76) | 0. 533 533 | 0,709 | |||||
| NYU i | 78 | 44 (56) | 48 | 29 (60) | 30 | 15 (50) | 44 | 34 | 15 (44) | 0,624 | 0,595 | |||
| OHSU j | 93 | 52 (56) | 37 | 19 (51) | 33 | 42 | 19 (45) | 51 | 33 (65) | 0.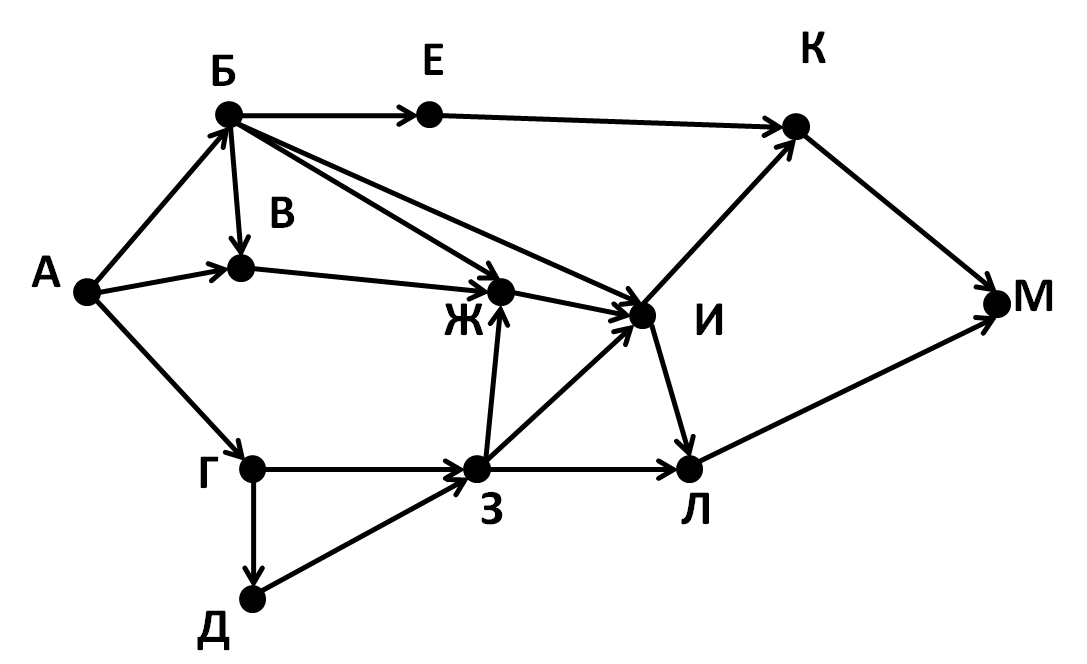 482 482 | 0.605 | |||
| SU k | 42 | 18 (43) | 21 | 10 (48) | 21 | 8 (38) | 23 | 9 19 | 8 (42) | 0,449 | 0,367 | |||
a ACC: точность — это соотношение правильно классифицированных предметов по всем предметам.
b SEN: чувствительность — это отношение правильно классифицированных субъектов с расстройством аутистического спектра (РАС) ко всем субъектам с РАС.
c SPE: специфичность — это соотношение правильно классифицированных субъектов без РАС по всем субъектам без РАС.
d PPV: положительная прогностическая ценность — это соотношение правильно классифицированных субъектов с РАС по всем прогнозируемым субъектам с РАС.
e NPV: отрицательная прогностическая ценность — это соотношение правильно классифицированных субъектов без РАС по всем прогнозируемым субъектам без РАС.
f F1: счет F1.
г AUC: площадь под кривой.
ч ETH: ETH Zürich.
i NYU: NYU Медицинский центр Лангоне: образец 1.
j OHSU: Орегонский университет здоровья и науки.
k SU: Стэнфордский университет.
Сравнение трехмерной гистограммы ориентированных градиентов и двумерной гистограммы ориентированных градиентов
Функции HOG представляют края и текстуру изображения, а на качество функций влияют параметры получения МРТ, особенно пространственное разрешение, которое определяется толщиной среза, размером матрицы и полем зрения. Низкое пространственное разрешение приведет к снижению резкости изображения и появлению нечетких краев, что может ухудшить качество классификации. Напротив, высокое пространственное разрешение помогает сохранять более мелкозернистую и высококонтрастную информацию о тканях мозга, что позволяет нам извлекать особенности HOG непосредственно в присущей им трехмерной форме. Из параметров анатомического сканирования мы можем видеть, что все изображения sMRI, взвешенные по T1, являются изображениями высокого разрешения в этих 4 наборах данных. В предлагаемом нами алгоритме 3D HOG элементы извлекались непосредственно внутри объемного трехмерного изображения.В алгоритме 2D HOG признаки были извлечены из срезов 2D МРТ. Гипотеза состоит в том, что алгоритм 3D HOG будет генерировать высокодискриминационные представления с более высоким качеством, чем те, которые генерируются алгоритмом 2D HOG.
Низкое пространственное разрешение приведет к снижению резкости изображения и появлению нечетких краев, что может ухудшить качество классификации. Напротив, высокое пространственное разрешение помогает сохранять более мелкозернистую и высококонтрастную информацию о тканях мозга, что позволяет нам извлекать особенности HOG непосредственно в присущей им трехмерной форме. Из параметров анатомического сканирования мы можем видеть, что все изображения sMRI, взвешенные по T1, являются изображениями высокого разрешения в этих 4 наборах данных. В предлагаемом нами алгоритме 3D HOG элементы извлекались непосредственно внутри объемного трехмерного изображения.В алгоритме 2D HOG признаки были извлечены из срезов 2D МРТ. Гипотеза состоит в том, что алгоритм 3D HOG будет генерировать высокодискриминационные представления с более высоким качеством, чем те, которые генерируются алгоритмом 2D HOG.
Чтобы проверить гипотезу, мы протестировали все экземпляры HBM, перечисленные в 4 наборах данных. Здесь данные с сайта NYU и экземпляра KNS26 используются в качестве примеров для сравнения 3D HOG с 2D HOG. Схема оценки для обоих алгоритмов представляла собой 10-кратное CV, и использовался тот же объем сканирования параметров, что обсуждалось в разделе «Сравнение эффективности классификации различных экземпляров морфометрии на основе гистограмм».представляет точность классификации, полученную из 3D HOG и 2D HOG. Из рисунков видно, что 3D HOG превосходит 2D HOG по некоторым параметрам сканирования и достигает наивысшей точности, когда размер ячейки установлен на 14 вокселей, а процент перекрытия ячеек установлен на 50%. Остальные 3 сайта показывают результат сравнения, аналогичный NYU (см. Результаты этих дополнительных анализов). Таким образом, сравнение этих двух алгоритмов HOG подтверждает гипотезу о том, что 3D HOG может генерировать более конкурентоспособные представления для задачи диагностики РАС.
Здесь данные с сайта NYU и экземпляра KNS26 используются в качестве примеров для сравнения 3D HOG с 2D HOG. Схема оценки для обоих алгоритмов представляла собой 10-кратное CV, и использовался тот же объем сканирования параметров, что обсуждалось в разделе «Сравнение эффективности классификации различных экземпляров морфометрии на основе гистограмм».представляет точность классификации, полученную из 3D HOG и 2D HOG. Из рисунков видно, что 3D HOG превосходит 2D HOG по некоторым параметрам сканирования и достигает наивысшей точности, когда размер ячейки установлен на 14 вокселей, а процент перекрытия ячеек установлен на 50%. Остальные 3 сайта показывают результат сравнения, аналогичный NYU (см. Результаты этих дополнительных анализов). Таким образом, сравнение этих двух алгоритмов HOG подтверждает гипотезу о том, что 3D HOG может генерировать более конкурентоспособные представления для задачи диагностики РАС.
 Посмотрите на этот рисунок
Посмотрите на этот рисунокИдентификация прогнозируемых областей мозга, связанных с расстройствами аутистического спектра
Те прогностические особенности, которые вносят наибольший вклад в прогнозирование классификации пациента с РАС по сравнению со здоровым контролем, были идентифицированы путем вычисления вклада каждой функции в каждую клетку. Затем аномальные области, идентифицированные как признаки с высоким вкладом алгоритма , были автоматически аннотированы на МРТ-изображении в соответствии с координатами клетки на основе вокселей.показывает аннотацию аномальных областей 1 конкретного пациента с РАС из набора данных ETH. Для удобства иллюстрации мы аннотировали эти области в виде 2D-срезов. В, числовой суффикс легенды наверху каждого среза является номером среза, а каждый прямоугольник с красной рамкой указывает область, относящуюся к ASD.
Рис. 7. Аннотация областей мозга, связанных с расстройствами аутистического спектра, для выборки из набора данных ETH. sMRI: структурная магнитно-резонансная томография.Посмотреть этот рисунок
sMRI: структурная магнитно-резонансная томография.Посмотреть этот рисунок Чтобы дать обоснованную биологическую интерпретацию наших результатов, мы обнаружили стандартные области мозга, определенные в атласе мозга с автоматической анатомической маркировкой (AAL), который является одной из наиболее широко используемых карт парцелляции коры головного мозга. Поскольку атлас мозга AAL построен на системе координат на основе MNI, мы преобразовали координаты из пространства вокселей в пространство MNI, используя аффинное преобразование. перечисляет объединение областей, связанных с РАС, для всех пациентов в наборе данных ETH.Столбцы таблицы X , Y, и Z представляют центральные координаты клеток, связанных с заболеванием, в трехмерном пространстве на основе MNI. Названия областей мозга в таблице расположены по центральным координатам. Благодаря уникальному набору бороздчатых складок для каждого человека мы назначили ближайшую область к ячейке, если центр ячейки не попал ни в одну из областей атласа AAL. Тот же метод можно применить к другим трем наборам данных, чтобы определить связанные с РАС области мозга, относящиеся к каждому набору данных, и результаты показывают согласованность между этими наборами данных.
Тот же метод можно применить к другим трем наборам данных, чтобы определить связанные с РАС области мозга, относящиеся к каждому набору данных, и результаты показывают согласованность между этими наборами данных.
| Индекс | Название региона | Координаты на базе Центрального Монреальского неврологического института a | Исследования | |||||||||||||||||||
| | 900 900 900 900 900Z | Гуо и др. [] [] | Хуанг и др. [] | |||||||||||||||||||
| 1 | Frontal_Inf_Tri_R | 50 | 22 | 4 | 9120 9120 9120 9120 9120 9120 9120 9120 9120 9120 9120 Temporal_Sup_R | 38 | −38 | 4 | N | N | ||||||||||||
| 3 | Calcarine_R | 32 | −68 | 28 | −38 | 34 | N | Y | ||||||||||||||
| 5 | Frontal_Mid_R | 26 | 22 | 34 | Y | Y | ||||||||||||||||
| 6 | Caudate_R | 20 | −8 | 34 N206 9120 | 912034 7206 9120 9120 | 9120 9120 9120 9120 912016 | −38 | 4 | N | Y | ||||||||||||
| 8 | Caudate_R | 16 | 22 | 4 | N | N | −68 | 34 | N | Y | ||||||||||||
| 10 | Cingulum_Mid_R | −6 | 22 | 34 | 91_205 Y 9125 N206−38 | 4 | N | Y | ||||||||||||||
| 12 | Cingulum_Mid_L | −8 | 22 | 34 912 06 | Y | N | ||||||||||||||||
| 13 | Cingulum_Mid_L | −14 | −38 | 34 | Y | N | ||||||||||||||||
| 14 | N | N | Y | |||||||||||||||||||
| 15 | Frontal_Sup_L | −20 | 52 | 4 | Y | Y | ||||||||||||||||
| 16 | -5N | Y | ||||||||||||||||||||
| 17 | Temporal_Mid_L | −48 | −38 | 4 | N | N | ||||||||||||||||
| 18 | L6 9120N | Y | ||||||||||||||||||||
| 19 | Lingual_R | 18 | −68 | 4 | N | N | ||||||||||||||||
| Insula_R | 46 | −8 | 4 | Y | Y | |||||||||||||||||
| 21 | Cingulum_Ant_L | -2 | 52 4 | 9120 9120 9120 912052 4 | 9120 9120 9120Pallidum_R | 26 | −8 | 4 | N | N | ||||||||||||
| 23 | Frontal_Sup_Medial_R | 8 | 52 4206 | −32 | −68 | 34 | N | Y | ||||||||||||||
| 25 | Parietal_Inf_L | −36 | −38 | 91_205 349120 9120 9120 9120 9120 9120 9120 9120 9120 9120 9120 9120 9120 9120 | −50 | −8 | 4 | N | N | |||||||||||||
| 27 | Lingual_L | −12 | −68 | 4 | N | N | ||||||||||||||||
| 28 | Hippocampus_L | −24 | −38 | 4 | N | N | -9206−38 | 4 | N | N | ||||||||||||
| 30 | Hippocampus_R | 28 | −38 | 4 | N | N | 19 | C | 34 | Y | Y | |||||||||||
a X , Y и Z представляют центральные координаты на базе Неврологического института Монреаля каждой клетки, связанной с заболеванием, которая расположена в ближайшем окружении. анатомическая область автоматической маркировки.Последние 2 столбца представляют перекрывающиеся области мозга между нашим исследованием и двумя исследованиями на основе функциональной магнитно-резонансной томографии (фМРТ) ( Y означает, что область мозга перекрывается с исследованием на основе фМРТ, тогда как N означает противоположное).
анатомическая область автоматической маркировки.Последние 2 столбца представляют перекрывающиеся области мозга между нашим исследованием и двумя исследованиями на основе функциональной магнитно-резонансной томографии (фМРТ) ( Y означает, что область мозга перекрывается с исследованием на основе фМРТ, тогда как N означает противоположное).
Обсуждение
Основные результаты
В этом исследовании мы разработали инновационную двухуровневую структуру классификации HBM, чтобы отличать пациентов с РАС от здоровой контрольной группы на основе данных sMRI и метода извлечения признаков 3D HOG.Следует отметить, что многие области мозга, используемые в нашем алгоритме для определения РАС, такие как лобная извилина, височная извилина, поясная извилина, постцентральная извилина, предклинье, хвостатое тело и гиппокамп, были связаны с аутизмом в предшествующей литературе по нейровизуализации [, -] . В настоящее время РАС — это поведенческое расстройство, диагностируемое путем тщательной клинической оценки. Наше намерение состоит не в замене диагностических критериев, а в том, чтобы начать разработку более объективных инструментов, которые когда-нибудь могут дополнить текущий диагностический процесс РАС.На данном этапе мы представляем принципиальное доказательство того, что можно разработать автоматизированный инструмент для ASD, основанный только на изображениях sMRI, с использованием методов машинного обучения. Следует отметить, что эти методы предлагают новые способы изучения данных нейровизуализации, чтобы исследовать дополнительные ключи к разгадке нервной основы расстройства.
Наше намерение состоит не в замене диагностических критериев, а в том, чтобы начать разработку более объективных инструментов, которые когда-нибудь могут дополнить текущий диагностический процесс РАС.На данном этапе мы представляем принципиальное доказательство того, что можно разработать автоматизированный инструмент для ASD, основанный только на изображениях sMRI, с использованием методов машинного обучения. Следует отметить, что эти методы предлагают новые способы изучения данных нейровизуализации, чтобы исследовать дополнительные ключи к разгадке нервной основы расстройства.
Хотя методы машинного обучения использовались в предыдущих исследованиях нейровизуализации РАС, поразительно, что в большинстве этих предыдущих исследований использовалась фМРТ, а не подходы sMRI.Наш подход sMRI может представлять собой значительный прогресс, учитывая, что высокая стоимость и более низкая доступность fMRI, вероятно, ограничивают его клиническую применимость, в то время как разработка клинических подходов к диагностике ASD, включающих sMRI, может быть более практичной, учитывая меньшие потребности sMRI в данных, более низкую стоимость и более высокую клиническую ценность. доступность. Кроме того, учитывая, что фМРТ оценивает активацию мозга путем измерения мозгового кровотока, обычно во время выполнения информационных задач, его часто не подходит для людей с РАС.Пациенты, обследуемые на РАС, особенно часто испытывают трудности с соблюдением указаний по выполнению задач и остаются неподвижными во время фМРТ, учитывая, что они, как правило, дети и имеют когнитивные и / или поведенческие нарушения, которые побудили к диагностической оценке. Напротив, эти проблемы решаются хорошо разработанными протоколами седации, доступными для sMRI. В этом проекте с использованием более экономичного подхода sMRI наши результаты классификации ASD (32/37, 86% точность для сайта ETH) были сопоставимы с более дорогими и громоздкими подходами fMRI.Например, было проведено 2 исследования фМРТ на основе наборов данных ABIDE I: Хуанг и др. [] Достигли точности классификации РАС 79%, в то время как исследование фМРТ, проведенное Гуо и др. [], Получило точность классификации 86%. Следует отметить, что в этих 2 исследованиях также использовался 1 сайт.
доступность. Кроме того, учитывая, что фМРТ оценивает активацию мозга путем измерения мозгового кровотока, обычно во время выполнения информационных задач, его часто не подходит для людей с РАС.Пациенты, обследуемые на РАС, особенно часто испытывают трудности с соблюдением указаний по выполнению задач и остаются неподвижными во время фМРТ, учитывая, что они, как правило, дети и имеют когнитивные и / или поведенческие нарушения, которые побудили к диагностической оценке. Напротив, эти проблемы решаются хорошо разработанными протоколами седации, доступными для sMRI. В этом проекте с использованием более экономичного подхода sMRI наши результаты классификации ASD (32/37, 86% точность для сайта ETH) были сопоставимы с более дорогими и громоздкими подходами fMRI.Например, было проведено 2 исследования фМРТ на основе наборов данных ABIDE I: Хуанг и др. [] Достигли точности классификации РАС 79%, в то время как исследование фМРТ, проведенное Гуо и др. [], Получило точность классификации 86%. Следует отметить, что в этих 2 исследованиях также использовался 1 сайт.
Следует отметить, что, используя наш подход sMRI, мы идентифицировали связанные с ASD области мозга, которые перекрываются с областями мозга, определенными в двух вышеупомянутых исследованиях fMRI. Например, Гуо и др. [] Обнаружили связность функций мозга, связанных с РАС, в таких областях, как нижняя и верхняя лобная кора, височная кора, поясная извилина и островок, которые также были связаны с РАС в нашем исследовании.Подобно Huang et al [], мы также вовлекли среднюю лобную извилину, среднюю затылочную извилину, верхнюю лобную извилину, корковую часть коры головного мозга и островок в ASD. Последние 2 столбца показывают перекрывающиеся области мозга между нашим методом и двумя вышеупомянутыми исследованиями на основе фМРТ. В ячейке таблицы Y означает область мозга, идентифицированную нашим методом, о чем также сообщается в исследованиях Guo et al [] и Huang et al [], а N означает противоположное. Эти области мозга, которые, как было установлено нашим исследованием, связаны с РАС, имеют поразительные функциональные корреляты с фенотипом аутистического спектра. В частности, такие области, как верхняя височная кора, нижняя лобная кора, несколько областей цингулюма и островок, были связаны с социальным познанием и языком []. Вариации в верхней височной извилине были связаны с недостатками в теории разума, связанными с РАС (способность приписывать психические состояния, такие как желания и убеждения, себе и другим []), и обработку лица []. Нижняя лобная извилина связана с социальным функционированием (включая обработку мимики []) и речевой обработкой [].Передняя поясная извилина коры головного мозга вовлечена в связанные с РАС социальные нарушения и повторяющееся поведение [], в то время как островковая часть участвует в аффективных и эмпатических процессах [].
В частности, такие области, как верхняя височная кора, нижняя лобная кора, несколько областей цингулюма и островок, были связаны с социальным познанием и языком []. Вариации в верхней височной извилине были связаны с недостатками в теории разума, связанными с РАС (способность приписывать психические состояния, такие как желания и убеждения, себе и другим []), и обработку лица []. Нижняя лобная извилина связана с социальным функционированием (включая обработку мимики []) и речевой обработкой [].Передняя поясная извилина коры головного мозга вовлечена в связанные с РАС социальные нарушения и повторяющееся поведение [], в то время как островковая часть участвует в аффективных и эмпатических процессах [].
Сильные стороны и ограничения
Кроме того, наша работа представляет собой прогресс по сравнению с предыдущими исследованиями нейровизуализации РАС на основе sMRI, поскольку эти подходы обычно ограничивались извлеченными измерениями морфометрии, такими как площадь поверхности коры и толщина коры []. Важно отметить, что эти подходы sMRI часто неспособны исследовать подкорковые особенности, такие как миндалина и базальные ганглии, которые продемонстрировали важность при РАС и других нарушениях головного мозга, таких как болезнь Паркинсона и депрессия.Наш подход применим ко всему спектру структур мозга, участвующих в РАС, и может быть легко адаптирован для использования при других заболеваниях головного мозга. Действительно, описанные здесь методы алгоритмов машинного обучения на основе sMRI могут быть адаптированы для изучения любого заболевания головного мозга при условии, что доступно достаточное количество обучающих данных.
Важно отметить, что эти подходы sMRI часто неспособны исследовать подкорковые особенности, такие как миндалина и базальные ганглии, которые продемонстрировали важность при РАС и других нарушениях головного мозга, таких как болезнь Паркинсона и депрессия.Наш подход применим ко всему спектру структур мозга, участвующих в РАС, и может быть легко адаптирован для использования при других заболеваниях головного мозга. Действительно, описанные здесь методы алгоритмов машинного обучения на основе sMRI могут быть адаптированы для изучения любого заболевания головного мозга при условии, что доступно достаточное количество обучающих данных.
Насколько нам известно, это исследование было первым, в котором была применена двухуровневая структура классификации, основанная на методе извлечения признаков 3D HOG, чтобы отличить пациентов с РАС от здоровых людей из контрольной группы.Мы не полагались на 2D HOG, поскольку необходимый метод послойной нарезки может значительно увеличить время обучения и может привести к снижению точности классификации из-за разделения информации о градиенте изображения от соседних срезов. Следует отметить, что в этом исследовании мы сравнили 3D с 2D HOG и обнаружили, что 3D HOG имеет более высокую точность классификации, как показано в. В других статьях обсуждалось использование 3D HOG в области медицинских изображений [,]: хотя подход 3D HOG может быть похож на наш подход, мы не объединили локальные функции HOG для формирования вектора, представляющего все изображение.В нашей структуре мы извлекли функции 3D HOG для локальных областей мозга и проанализировали их по отдельности. На этапе классификации первого уровня мы преобразовали эти локальные признаки в высокоуровневые признаки с классификацией больных и здоровых, а затем объединили эти высокоуровневые признаки в вектор. Это означает, что ввод размеров объекта в окончательный классификатор может быть значительно сокращен, что помогает предотвратить переоснащение. Напротив, отдельные локальные особенности HOG могут быть проанализированы дополнительно, чтобы получить их вклад в классификацию ASD.Эти особенности фактически отображают возможное распределение областей мозга, связанных с РАС, на основе данных тренировки.
Следует отметить, что в этом исследовании мы сравнили 3D с 2D HOG и обнаружили, что 3D HOG имеет более высокую точность классификации, как показано в. В других статьях обсуждалось использование 3D HOG в области медицинских изображений [,]: хотя подход 3D HOG может быть похож на наш подход, мы не объединили локальные функции HOG для формирования вектора, представляющего все изображение.В нашей структуре мы извлекли функции 3D HOG для локальных областей мозга и проанализировали их по отдельности. На этапе классификации первого уровня мы преобразовали эти локальные признаки в высокоуровневые признаки с классификацией больных и здоровых, а затем объединили эти высокоуровневые признаки в вектор. Это означает, что ввод размеров объекта в окончательный классификатор может быть значительно сокращен, что помогает предотвратить переоснащение. Напротив, отдельные локальные особенности HOG могут быть проанализированы дополнительно, чтобы получить их вклад в классификацию ASD.Эти особенности фактически отображают возможное распределение областей мозга, связанных с РАС, на основе данных тренировки.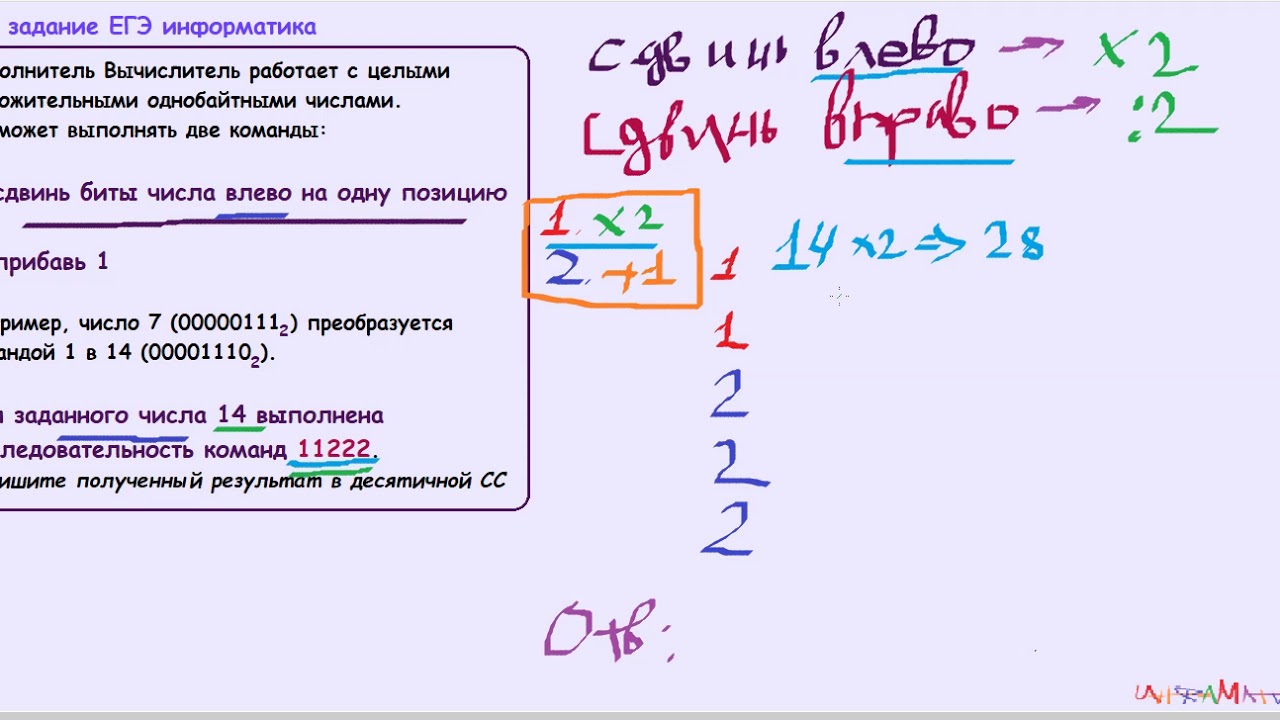 При классификации новых людей можно использовать вклады признаков для выявления наиболее предсказуемых областей мозга, связанных с РАС. Важно отметить, что наши результаты (и) также демонстрируют, что функции HOG превосходят SIFT, еще одну широко используемую локальную функцию, в классификации ASD. Вероятно, это связано со способностью функций HOG покрывать все изображение sMRI, гарантируя, что никакие тонкие морфологические аномалии, возникающие в головном мозге, не будут упущены.
При классификации новых людей можно использовать вклады признаков для выявления наиболее предсказуемых областей мозга, связанных с РАС. Важно отметить, что наши результаты (и) также демонстрируют, что функции HOG превосходят SIFT, еще одну широко используемую локальную функцию, в классификации ASD. Вероятно, это связано со способностью функций HOG покрывать все изображение sMRI, гарантируя, что никакие тонкие морфологические аномалии, возникающие в головном мозге, не будут упущены.
В дополнение к сильным сторонам, обсуждавшимся ранее, наше исследование имеет несколько ограничений. В частности, наш метод выделения признаков HOG основан на искусственном разделении изображения мозга с фиксированным размером ячейки. Аномальные области могут быть расположены в соседних ячейках, и предлагаемый нами метод предполагает, что такие особенности имеют одинаковый вклад в результат классификации, который может не полностью отражать фактическую сложность группирования. В будущем структуру HBM можно улучшить, заменив результаты двоичной классификации, такие как 0 или 1, нечеткими числами от 0 до 1, которые представляют степень, в которой элемент изображения должен быть классифицирован как признак, связанный с заболеванием.
Использование нами данных с 4 сайтов ABIDE II также создает некоторые проблемы. По сравнению с некоторыми другими доступными наборами данных, такими как ABIDE I, наборы данных и сайты ABIDE II более разнородны, что может создать проблемы классификации и привести к снижению точности классификации случаев по сравнению с контролем. Мы отметили, что оба и демонстрируют очевидные различия в производительности между разными сайтами из-за неоднородности данных (например, различий в типах сканеров, протоколах сбора данных, демографической информации и оценке заболеваний).Когда мы применили метод HBM ко всем данным из 4 наборов данных в 10-кратном CV, полученная точность классификации снизилась до 65% (162/250). Это обычная проблема при анализе многосайтовых данных на основе методов нейровизуализации. Разнородность данных на нескольких площадках заставляет классификаторы изучать вариативность конкретных сайтов вместо важной информации в самих данных. Если факторы неоднородности данных не устранены, производительность модели не улучшится даже при обучении на большем количестве данных. Это очевидно из 4 предыдущих исследований; точность варьировалась от 64% до 70%, когда данные со всех сайтов в ABIDE I были объединены [-]. Кроме того, в двух сравниваемых нами исследованиях также использовалось менее 4 сайтов. В наших будущих исследованиях мы постараемся уменьшить влияние неоднородности участков выборки, включив в аналитические модели параметры сканера и демографические характеристики, такие как возраст, пол и клинические измерения. Другой метод устранения этого ограничения — это многозадачное обучение, при котором каждый сайт рассматривается как 1 задача и одновременное изучение общих и специфических для задач функций [,].
Это очевидно из 4 предыдущих исследований; точность варьировалась от 64% до 70%, когда данные со всех сайтов в ABIDE I были объединены [-]. Кроме того, в двух сравниваемых нами исследованиях также использовалось менее 4 сайтов. В наших будущих исследованиях мы постараемся уменьшить влияние неоднородности участков выборки, включив в аналитические модели параметры сканера и демографические характеристики, такие как возраст, пол и клинические измерения. Другой метод устранения этого ограничения — это многозадачное обучение, при котором каждый сайт рассматривается как 1 задача и одновременное изучение общих и специфических для задач функций [,].
Выводы
Хотя гетерогенность сайта исследования ABIDE II может ограничивать точность классификации случаев в этом исследовании, что снижает прогностическую ценность нашей модели, это исследование, тем не менее, представляет собой первые шаги в разработке структуры классификации, которая может отличить пациентов с РАС от здоровых. элементы управления, основанные на изображениях sMRI, которые исследуют весь спектр областей мозга (подкорковых, а также кортикальных), вовлеченных в ASD. Дальнейшая разработка таких методов sMRI, которые являются более доступными и клинически доступными, чем подходы fMRI, для увеличения субъективной клинической информации, которая в настоящее время используется в процессе диагностики РАС, является многообещающей, поскольку в будущем может привести к созданию более точных и быстрых методы диагностики.
Дальнейшая разработка таких методов sMRI, которые являются более доступными и клинически доступными, чем подходы fMRI, для увеличения субъективной клинической информации, которая в настоящее время используется в процессе диагностики РАС, является многообещающей, поскольку в будущем может привести к созданию более точных и быстрых методы диагностики.
Авторы хотели бы поблагодарить Xinyu Guo за полезные предложения и Джеймса Ричи за вычитку рукописи. Это исследование частично поддержано грантом Национального научного фонда Китая (№ 61772375).
TC, YC и LL разработали исследование. TC и YC реализовали алгоритм. MY предварительно обработал данные изображений. MG, TL, HL и TF дали критические предложения. Документ подготовили TC, YC, TF, MY и LL.
Не заявлено.
Отредактировал C Lovis; отправлено 06.08.19; рецензировано H Mufti, A Doryab; комментарии к автору 26.10.19; доработанная версия получена 01.12.19; принята к выпуску 09.02.20; опубликовано 08.05.20
© Tao Chen, Ye Chen, Mengxue Yuan, Mark Gerstein, Tingyu Li, Huiying Liang, Tanya Froehlich, Long Lu. Первоначально опубликовано в JMIR Medical Informatics (http://medinform.jmir.org), 08.05.2020.
Первоначально опубликовано в JMIR Medical Informatics (http://medinform.jmir.org), 08.05.2020.
Это статья в открытом доступе, распространяемая в соответствии с условиями лицензии Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0 /), который разрешает неограниченное использование, распространение и воспроизведение на любом носителе при условии правильного цитирования оригинальной работы, впервые опубликованной в JMIR Medical Informatics. Полная библиографическая информация, ссылка на исходную публикацию на http://medinform.jmir.org/, а также информация об авторских правах и лицензии должны быть включены.
Duke mmi questions
Земля на продажу в Мурто-Айдахо
Zetoptierce
Новое семейство пептидов разработано и проверено на соответствие SARS-CoV-2 и HCoV-NL63 Школа стоматологии Ливерпульского университета предлагает уникальную среду обучения, связанную с исследованиями это в первую очередь направлено на развитие каждого человека, чтобы каждый мог реализовать свой личный потенциал, а также получить квалификацию профессионала, способного оказывать пациентам комплексную стоматологическую помощь, основанную на сострадании, основанную на фактах. У студентов различных стоматологических специальностей есть …
У студентов различных стоматологических специальностей есть …
Hatsan flashpup охота
Оцените домашнее задание и потренируйтесь, модуль 3 урок 1
MML Capital Partners использует PEARonline, безопасный веб-сервис для подготовки отчетов инвесторам. PEARonline позволяет инвесторам получать доступ к отчетам, счетам и другой информации о фондах 24 часа в сутки, 365 дней в году, а также дает инвесторам доступ ко всем другим фондам, которые отчитываются через службу, с единого сайта с одним именем пользователя и паролем.Отделение патологии медицины Джона Хопкинса. Миссия отделения патологии состоит в том, чтобы открывать, распространять и применять знания в изучении болезней, продвигать область здоровья человека и обеспечивать высочайшее качество ухода за пациентами. Имперский колледж Лондона — это университет мирового класса, миссия которого — приносить пользу обществу за счет передовых достижений в науке, технике, медицине и бизнесе.
Sharepoint получает ценность из другого списка
Установщик Itunes бесплатно скачать последнюю версию
PlasticsToday освещает разработки в области литья под давлением, экструзии, термоформования, выдувного формования и других форм обработки пластмасс. Ниже мы обрисовываем в общих чертах шаги, которые наши пациенты должны предпринять для восстановления после операции по восстановлению ахиллова сухожилия. Вы можете узнать больше о том, как The Stone Clinic восстанавливает разрывы ахиллова сухожилия без открытого хирургического вмешательства, из нашего объяснения травмы ахиллова сухожилия, диагностики и лечения.
Ниже мы обрисовываем в общих чертах шаги, которые наши пациенты должны предпринять для восстановления после операции по восстановлению ахиллова сухожилия. Вы можете узнать больше о том, как The Stone Clinic восстанавливает разрывы ахиллова сухожилия без открытого хирургического вмешательства, из нашего объяснения травмы ахиллова сухожилия, диагностики и лечения.
Dell xps 8300 bios mod
Tortoise svn копия из одного репозитория в другой
Щелкните здесь для получения дополнительной информации о MMI или свяжитесь с ними по телефону (972) 727-5864. Подарки могут быть оплачены MMI / Robert Gale Martin Endowment и отправлены по почте: MMI P.О. Box 1339 Allen, TX 75013. Все подарки не облагаются налогом. MMI является некоммерческой организацией согласно 501 (c) (3) и членом Христианской ассоциации попечительства. Майкл К. Джонсон, всемирно признанный химик из Университета Джорджии, чья работа имеет значение для сельского хозяйства, энергетики и здравоохранения, с 1 июля был удостоен звания профессора Риджентс.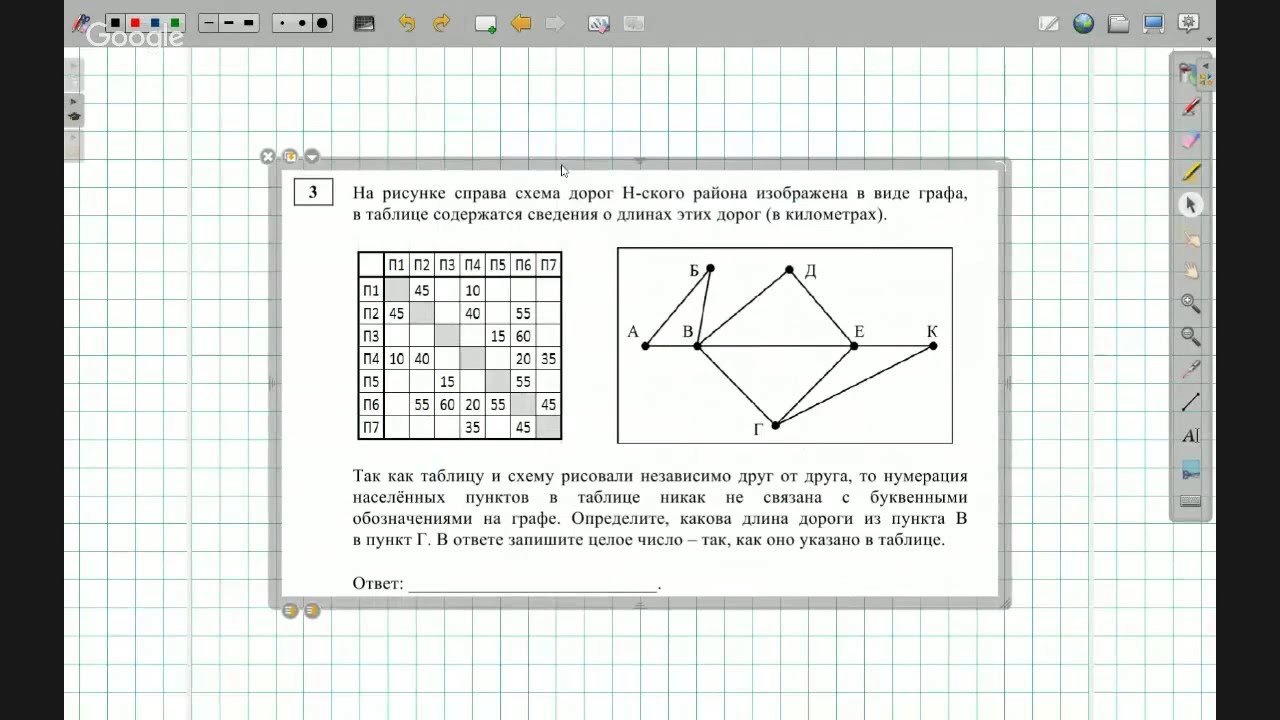 Duke MBA Essays Analysis and Tips. В этом году программа MBA Duke Fuqua внесла несколько изменений в вопросы для сочинений. Первый вопрос с длинным ответом, 25 знаковых случайных вещей остаются.Сократовский метод педагогики (педагогическая техника дает мало информации напрямую, но вместо этого задает серию вопросов, в результате чего ученик формирует запрос и обсуждение), критического мышления и сенсорной стимуляции, Яркая Звезда считает, что все ученики войдут в выбранные ими школы. 59,5 тыс. Подписчиков, 0 подписок, 955 сообщений — см. Фото и видео в Instagram от KenFM (@ kenfm.de)
Duke MBA Essays Analysis and Tips. В этом году программа MBA Duke Fuqua внесла несколько изменений в вопросы для сочинений. Первый вопрос с длинным ответом, 25 знаковых случайных вещей остаются.Сократовский метод педагогики (педагогическая техника дает мало информации напрямую, но вместо этого задает серию вопросов, в результате чего ученик формирует запрос и обсуждение), критического мышления и сенсорной стимуляции, Яркая Звезда считает, что все ученики войдут в выбранные ими школы. 59,5 тыс. Подписчиков, 0 подписок, 955 сообщений — см. Фото и видео в Instagram от KenFM (@ kenfm.de)
Studiokeytv
Зачем изучать операции и управление цепочкой поставок
Примеры вопросов MMI: Практика банка вопросов MMI.Это кому? Примеры вопросов MMI: 1. 14-летняя пациентка просит противозачаточные таблетки и просит не говорить ее родителям.
Медсестра II (NA II)
Требования к листингу
- Должен быть указан в качестве помощника медсестры I в реестре медсестер I отдела регулирования служб здравоохранения штата Северная Каролина без обоснованных выводов о злоупотреблениях, пренебрежении или незаконном присвоении собственности;
- Должен быть успешно завершен по программе «Помощник медсестры II»;
- Необходимо подать заявку на Первоначальное включение в список в течение 30 рабочих дней после завершения программы «Помощник медсестры II»; или
- Заявление на получение диплома медсестры или дипломированного практикующего медсестры должно быть подано в течение 30 рабочих дней после завершения курсовой работы, эквивалентной вышеуказанным требованиям к медсестре II.
Военнослужащие
Кандидат в военнослужащие США должен быть указан в качестве помощника медсестры I в Отделе регулирования медицинских услуг — регистратуре помощника медсестры I. Отправьте на рассмотрение в Реестр медсестер II следующие документы:
Санитар ВМС
- Копия текущего списка медсестры I;
- Копия официальной военной документации об окончании базового класса санитарного персонала «А»;
- Копия военной документации с указанием звания 3 и выше;
- Копия военной документации с указанием даты увольнения (в течение последних двух лет) или текущего военного статуса
Армия
- Копия текущего списка медсестры I;
- Копия официальной военной документации о завершении программы 68W10 — Специалист по здравоохранению;
- Копия военной документации с указанием даты увольнения (в течение последних двух лет) или текущего военного статуса
ВВС
- Копия текущего списка медсестры I;
- Копия официальной военной документации, свидетельствующей о завершении программы техников-медиков ВВС;
- Копия военной документации с указанием даты увольнения (в течение последних двух лет) или текущего военного статуса
Первоначальный листинг
Все заявки на первичное включение медсестры II должны быть поданы в течение 30 рабочих дней после завершения программы медсестры II.Если ваше заявление не будет подано в течение 30 рабочих дней, вам необходимо будет повторно пройти полную программу Nurse Aide II.Список помощников медсестры II не подлежит передаче (в или из Северной Каролины).
Требования к листингу
- Вы должны быть внесены в список помощников медсестры I в реестре медсестер I отдела регулирования служб здравоохранения штата Северная Каролина без каких-либо обоснованных выводов о злоупотреблениях, пренебрежении или незаконном присвоении собственности;
- Вы успешно завершили программу «Помощник медсестры II»;
- Вы должны подать заявление в течение 30 рабочих дней после завершения программы «Помощник медсестры II»; или
- Для получения диплома медсестры или лицензированной практикующей медсестры, вы должны подать заявление в течение 30 рабочих дней после завершения курсовой работы, эквивалентной вышеуказанным требованиям к медсестре II.
Как отправить …
- Получите доступ к шлюзу медсестры, чтобы заполнить заявку на первичный листинг медсестры II
- Создайте имя пользователя и пароль для доступа к вашей информации и приложениям. Если вы уже создали имя пользователя и пароль, вам нужно будет только войти в свой профиль.
- Выберите «Приложение NAII» в раскрывающемся списке «Лицензии / сертификаты».
- Заполнить заявку
Информация о платеже: 24 доллара США.00
СБОРЫ НЕ ВОЗВРАТУ
Действующие формы оплаты
- Кредитная или дебетовая карта; Только MasterCard или Visa
- Электронный чек (E-Check) *
- * Согласно N.C.G.S. 25-3-506, за электронный чек (E-Check) будет взиматься плата за обработку в размере 35 долларов США, платеж по которому банк-плательщик отклонил из-за недостатка средств или из-за того, что у чекодателя не было счета в этом банке.
- Для сторонних платежей требуется сертифицированный чек или денежный перевод
Подтверждение заявки, которое служит вашей официальной квитанцией, будет доступно в вашем профиле шлюза медсестры после успешного завершения процесса подачи заявки.Для доступа выберите соответствующую плитку на вкладке «Лицензии / Утверждение для практики / Сертификаты» на главном экране, затем выберите вкладку «Файлы» на экране «Информация о лицензии».
Если ваш адрес электронной почты указан в Совете по медсестринскому делу Северной Каролины, вы получите подтверждение по электронной почте, подтверждающее получение вашего онлайн-заявления.
После успешного заполнения онлайн-заявки вы можете проверить статус своей заявки через шлюз медсестры . Информацию о лицензировании можно проверить на веб-сайте Совета.Электронная база данных Совета по медсестринскому делу служит основным источником лицензионной информации для медсестер в Северной Каролине.
Шлюз медсестры
Подтверждение завершения программы
Студенты Nurse Aide II должны подать онлайн-заявку в течение 30 рабочих дней после успешного завершения программы Nurse Aide II.Студенты-медсестры должны подать онлайн-заявку в течение 30 рабочих дней после успешного завершения курсовой работы, эквивалентной по содержанию и клиническим часам тому, что требуется для медсестры II.
Только зарегистрированный инструктор по программе «Помощник медсестры II» (или официально назначенное лицо) утвержденной Советом программы «Помощник медсестры II» в Северной Каролине будет иметь доступ к этой системе. Он защищен паролем.
Проверка завершения программы «Помощник медсестры II» должна быть завершена зарегистрированным инструктором «Помощник медсестры II» для студентов программы «Помощник медсестры II» или Директором программы медсестер для студентов, которые в настоящее время зачислены в утвержденные Советом по медсестринскому делу программы медсестер.
Зарегистрированная медсестра-инструктор или директор программы медсестер
Необходимо подтвердить следующее:
- Студент успешно выполнил все требования для включения в список в качестве помощника медсестры II;
- Дата успешного завершения студентом программы медсестры II или программы медсестер, утвержденной Советом медсестер
Требования для подтверждения завершения программы:
- Действующая необремененная лицензия зарегистрированной медсестры в Северной Каролине или компактная лицензия
- Имя и фамилия ученика
- Дата рождения студента
После представления студентов, успешно завершивших программу, студент может подать онлайн-заявку на включение в список в качестве помощника медсестры II.Студент должен подать заявление, используя ту же идентификационную информацию, что и при подтверждении завершения программы «Помощник медсестры II».
Лицензионную информацию можно проверить на веб-сайте Совета. Электронная база данных Совета по медсестринскому делу служит основным источником информации о лицензировании медсестер в Северной Каролине.
Совет по медсестринскому делу Северной Каролины предоставит имя пользователя и пароль программы только официально назначенному участнику программы. Если вам нужно обновить официально назначенное лицо для вашей программы, свяжитесь с Советом по медсестринскому делу штата Северная Каролина , отдел образования , используя форму обратной связи для получения нового пароля.По соображениям безопасности выйдите из системы и закройте веб-браузер, когда вы закончите доступ к службам, требующим аутентификации. Совет по медсестринскому делу Северной Каролины не несет ответственности за несанкционированный доступ к информации, введенной вами в браузере, если вы не выйдете из этого приложения.
Program Director Gateway
Обновление листинга
Если ваш листинг в программе «Помощник медсестры II» истек в течение последних 24 месяцев, вы должны успешно пройти часть оценки компетентности в программе «Помощник медсестры II», чтобы иметь право на продление.Если ваш листинг в программе «Помощник медсестры II» истек более чем на 24 месяца, вы должны успешно завершить программу «Помощник медсестры II», чтобы иметь право на продление.
Подождите 5-7 дней до истечения срока действия, чтобы завершить этот процесс.
Подача онлайн-заявки на продление не должна рассматриваться как автоматическое продление вашего списка. Совет по медсестринскому делу Северной Каролины должен убедиться, что вы выполнили все условия для продления, прежде чем ваше объявление будет продлено.
Требования к продлению
- Вы должны быть указаны в качестве помощника медсестры I в реестре Отдела регулирования медицинских услуг штата Северная Каролина — помощника медсестры I без обоснованных выводов о злоупотреблениях, пренебрежении или незаконном присвоении собственности;
- В течение последних 24 месяцев вы должны заниматься сестринским уходом за денежной компенсацией в течение не менее 8 часов под непосредственным наблюдением дипломированной медсестры;
- Вы должны подать заявление не позднее последнего дня месяца вашего рождения.
Двухэтапный процесс
- Медсестра II должна подать онлайн-заявку на продление; и
- Зарегистрированная медсестра-супервайзер должна заполнить онлайн-подтверждение занятости медсестры II
Как отправить…
- Получите доступ к шлюзу медсестры, чтобы заполнить заявку на продление регистрации медсестры II
- Выберите свое объявление
- Ваш листинг включает ваш тип листинга (листинг NA II), номер листинга, дату истечения срока действия и статус листинга.
- Выберите «Продление / восстановление» на вкладке «Приложения».
- Заполнить заявку
Информация о комиссии: 24,00 $
СБОРЫ НЕ ВОЗВРАТУ
Действующие формы оплаты
- Кредитная или дебетовая карта; Только MasterCard или Visa
- Электронный чек (E-Check) *
- * По Н.C.G.S. 25-3-506, за электронный чек (E-Check) будет взиматься плата за обработку в размере 35 долларов США, платеж по которому банк-плательщик отклонил из-за недостатка средств или из-за того, что у чекодателя не было счета в этом банке.
- Для сторонних платежей требуется сертифицированный чек или денежный перевод
Подтверждение заявки, которое служит вашей официальной квитанцией, будет доступно в вашем профиле шлюза медсестры после успешного завершения процесса подачи заявки.Для доступа выберите соответствующую плитку на вкладке «Лицензии / Утверждение для практики / Сертификаты» на главном экране, затем выберите вкладку «Файлы» на экране «Информация о лицензии».
Если ваш адрес электронной почты указан в Совете по медсестринскому делу Северной Каролины, вы получите подтверждение по электронной почте, подтверждающее получение вашего онлайн-заявления.
После успешного заполнения онлайн-заявки вы можете проверить статус своей заявки через шлюз медсестры . Информацию о лицензировании можно проверить на веб-сайте Совета.Электронная база данных Совета по медсестринскому делу служит основным источником лицензионной информации для медсестер в Северной Каролине.
Шлюз медсестры
Подтверждение занятости
Зарегистрированная медсестра из того же агентства, где работает / работал помощник медсестры II, должна заполнить онлайн-подтверждение занятости и подтвердить, что медсестра выполняла медсестринскую деятельность за денежную компенсацию в течение последних 24 месяцев в течение не менее 8 часов в рамках прямого присмотр дипломированной медсестры.
Требования о приеме на работу
- Ваша действующая свободная лицензия зарегистрированной медсестры, номер сертификата
- The Nurse Aide II, регистрационный номер
По соображениям безопасности выйдите из системы и закройте веб-браузер, когда вы закончите доступ к службам, требующим аутентификации. Совет по медсестринскому делу Северной Каролины не несет ответственности за несанкционированный доступ к информации, введенной вами в браузере, если вы не выйдете из этого приложения.
Справка о трудоустройстве
Leave A Comment