
Ненаследственная изменчивость — что это, определение и ответ
Изменчивость организмов проявляется в разнообразии особей (одного вида, породы или сорта), отличающихся друг от друга по комплексу признаков, свойств и качеств.
На основании причин возникновения изменчивости выделяют два её вида:
→ ненаследственную (модификационную, фенотипическую)
→ наследственную (генотипическую).
Генотип — генетический материал организма
Фенотип — признаки организма (внешние и внутренние)
Модификационная (фенотипическая) изменчивость заключается в том, что под действием разных условий внешней среды у организмов одного вида, генотипически одинаковых, наблюдается изменение признаков (фенотипа). Изменения эти индивидуальны и не наследуются, т. е. не передаются особям следующих поколений.
Примеры проявления фенотипической изменчивости
1. В одном из опытов корневище одуванчика разрезали вдоль острой бритвой и высадили половинки в разных условиях ― в низине и в горах. К концу сезона из этих проростков выросли совершенно не похожие друг на друга растения. Первое из них (в низине) было высоким, с большими листьями и крупным цветком. Второе, выросшее в горах, в суровых условиях, оказалось низкорослым, с мелкими листьями и цветком.
В одном из опытов корневище одуванчика разрезали вдоль острой бритвой и высадили половинки в разных условиях ― в низине и в горах. К концу сезона из этих проростков выросли совершенно не похожие друг на друга растения. Первое из них (в низине) было высоким, с большими листьями и крупным цветком. Второе, выросшее в горах, в суровых условиях, оказалось низкорослым, с мелкими листьями и цветком.
Генотип у этих двух растений абсолютно идентичен (ведь они выросли из половинок одного корневища), но их фенотипы существенно различались в результате разных условий произрастания. Потомки этих двух растений, выращенные в одинаковых условиях, ничем не отличались друг от друга. Следовательно, фенотипические изменения не наследуются.
Биологическое значение модификационной изменчивости заключается в обеспечении индивидуальной приспособляемости организма к различным условиям внешней среды.
2.Рассмотрим другой пример. Представим себе, что две сестры, однояйцовых близнеца (т. е. с идентичными генотипами) выбрали еще в детстве разные увлечения: одна посвятила себя тяжелой атлетике, а другая― игре на скрипке. Очевидно, через десяток лет между ними будет наблюдаться существенное физическое различие. И также ясно, что у спортсмена его новорожденный сын не родится с «атлетическими» признаками.
Очевидно, через десяток лет между ними будет наблюдаться существенное физическое различие. И также ясно, что у спортсмена его новорожденный сын не родится с «атлетическими» признаками.
Статистические закономерности модификационной изменчивости можно выразить вариационным рядом и вариационной кривой.
Вариационный ряд – ряд значений признака, расположенных в порядке возрастания или убывания.
Вариационный ряд листьев лавровишни (цифрами обозначена длина листа)
Вариационная кривая – это графическое отображение зависимости частоты проявления варианта от его интенсивности.
Вариационная кривая распределения семян тыквы по их величине
Изменения фенотипа под воздействием условий внешней среды могут происходить не беспредельно, а только в ограниченном диапазоне (широком или узком), который обусловлен генотипом.
Диапазон, в пределах которого признак может изменяться, носит название нормы реакции.
Так, например, признаки у коров, учитываемые в животноводстве, ― удойность (т. е. количество вырабатываемого молока) и жирность молока ― могут изменяться, но в разных пределах. В зависимости от условий содержания и кормления животных удойность варьируется существенно (от стаканов до нескольких ведер в сутки). В данном случае говорят о широкой норме реакции.
А вот жирность молока очень незначительно колеблется в зависимости от условий содержания (всего на сотые доли процента), т. е. этот признак характеризуется узкой нормой реакции.
К широкой норме реакции чаще относятся количественные показатели, к узкой – качественные
| Широкая норма реакции | Узкая норма реакции |
|---|---|
| Высота растения | Форма цветка |
| Размеры листьев | Размеры сердца |
| Рост человека | Размеры печени |
| Вес животных | Жирность молока |
| Яйценоскость кур | Половые различия |
| Удои молока | Окраска шерсти |
Итак, условия внешней среды обусловливают изменения признака в пределах нормы реакции. Границы же последней продиктованы генотипом. Следовательно, изменения самой нормы реакции могут произойти только в результате изменения генотипа (т. е. в результате генотипической изменчивости).
Границы же последней продиктованы генотипом. Следовательно, изменения самой нормы реакции могут произойти только в результате изменения генотипа (т. е. в результате генотипической изменчивости).
Модификационная изменчивость
Причина: Изменение условий среды
Результат: Приспособленность
Характер: Массовый
Big Data (большие данные): что это и как их используют, примеры
Фото: Mint Images / Shutterstock
Смартфоны предлагают нам загрузить все данные в облако, а большие компании вроде Google и «Яндекса» — воспользоваться своими экосистемами. Проще говоря, мы живем в эпоху Big Data. Но что это значит на самом деле?
1
Что такое Big Data?
Big Data или большие данные — это структурированные или неструктурированные массивы данных большого объема. Их обрабатывают при помощи специальных автоматизированных инструментов, чтобы использовать для статистики, анализа, прогнозов и принятия решений.
Сам термин «большие данные» предложил редактор журнала Nature Клиффорд Линч в спецвыпуске 2008 года [1]. Он говорил о взрывном росте объемов информации в мире. К большим данным Линч отнес любые массивы неоднородных данных более 150 Гб в сутки, однако единого критерия до сих пор не существует.
«Лиза Алерт» использует Big Data, чтобы находить пропавших людей
До 2011 года анализом больших данных занимались только в рамках научных и статистических исследований. Но к началу 2012-го объемы данных выросли до огромных масштабов, и возникла потребность в их систематизации и практическом применении.
Всплеск интереса к большим данным в Google Trends
С 2014 на Big Data обратили внимание ведущие мировые вузы, где обучают прикладным инженерным и IT-специальностям. Затем к сбору и анализу подключились IT-корпорации — такие, как Microsoft, IBM, Oracle, EMC, а затем и Google, Apple, Facebook (с 21 марта 2022 года соцсеть запрещена в России решением суда) и Amazon. Сегодня большие данные используют крупные компании во всех отраслях, а также — госорганы. Подробнее об этом — в материале «Кто и зачем собирает большие данные?»
Подробнее об этом — в материале «Кто и зачем собирает большие данные?»
2
Какие есть характеристики Big Data?
Компания Meta Group предложила основные характеристики больших данных [2]:
- Volume — объем данных: от 150 Гб в сутки;
- Velocity — скорость накопления и обработки массивов данных. Большие данные обновляются регулярно, поэтому необходимы интеллектуальные технологии для их обработки в режиме онлайн;
- Variety — разнообразие типов данных. Данные могут быть структурированными, неструктурированными или структурированными частично. Например, в соцсетях поток данных не структурирован: это могут быть текстовые посты, фото или видео.
Сегодня к этим трем добавляют еще три признака [3]:
- Veracity — достоверность как самого набора данных, так и результатов его анализа;
- Variability — изменчивость. У потоков данных бывают свои пики и спады под влиянием сезонов или социальных явлений.

- Value — ценность или значимость. Как и любая информация, большие данные могут быть простыми или сложными для восприятия и анализа. Пример простых данных — это посты в соцсетях, сложных — банковские транзакции.

3
Как работает Big Data: как собирают и хранят большие данные?
Большие данные необходимы, чтобы проанализировать все значимые факторы и принять правильное решение. С помощью Big Data строят модели-симуляции, чтобы протестировать то или иное решение, идею, продукт.
Главные источники больших данных:
- интернет вещей (IoT) и подключенные к нему устройства;
- соцсети, блоги и СМИ;
- данные компаний: транзакции, заказы товаров и услуг, поездки на такси и каршеринге, профили клиентов;
- показания приборов: метеорологические станции, измерители состава воздуха и водоемов, данные со спутников;
- статистика городов и государств: данные о перемещениях, рождаемости и смертности;
- медицинские данные: анализы, заболевания, диагностические снимки.

С 2007 года в распоряжении ФБР и ЦРУ появилась PRISM — один из самых продвинутых сервисов, который собирает персональные данные обо всех пользователях соцсетей, а также сервисов Microsoft, Google, Apple, Yahoo и даже записи телефонных разговоров.
Современные вычислительные системы обеспечивают мгновенный доступ к массивам больших данных. Для их хранения используют специальные дата-центры с самыми мощными серверами.
Как выглядит современный дата-центр
Помимо традиционных, физических серверов используют облачные хранилища, «озера данных» (data lake — хранилища большого объема неструктурированных данных из одного источника) и Hadoop — фреймворк, состоящий из набора утилит для разработки и выполнения программ распределенных вычислений. Для работы с Big Data применяют передовые методы интеграции и управления, а также подготовки данных для аналитики.
4
Big Data Analytics — как анализируют большие данные?
Благодаря высокопроизводительным технологиям — таким, как грид-вычисления или аналитика в оперативной памяти, компании могут использовать любые объемы больших данных для анализа. Иногда Big Data сначала структурируют, отбирая только те, что нужны для анализа. Все чаще большие данные применяют для задач в рамках расширенной аналитики, включая искусственный интеллект.
Иногда Big Data сначала структурируют, отбирая только те, что нужны для анализа. Все чаще большие данные применяют для задач в рамках расширенной аналитики, включая искусственный интеллект.
Выделяют четыре основных метода анализа Big Data [4]:
1. Описательная аналитика (descriptive analytics)
Антон Мироненков, управляющий директор «X5 Технологии»:
«Есть два больших класса моделей для принятия решений по ценообразованию. Первый отталкивается от рыночных цен на тот или иной товар.
Второй класс моделей связан с выстраиванием кривой спроса, которая отражает объемы продаж в зависимости от цены. Это более аналитическая история. В онлайне такой механизм применяется очень широко, и мы переносим эту технологию из онлайна в офлайн».
2. Прогнозная или предикативная аналитика (predictive analytics) — помогает спрогнозировать наиболее вероятное развитие событий на основе имеющихся данных. Для этого используют готовые шаблоны на основе каких-либо объектов или явлений с аналогичным набором характеристик. С помощью предикативной (или предиктивной, прогнозной) аналитики можно, например, просчитать обвал или изменение цен на фондовом рынке. Или оценить возможности потенциального заемщика по выплате кредита.
3. Предписательная аналитика (prescriptive analytics) — следующий уровень по сравнению с прогнозной. С помощью Big Data и современных технологий можно выявить проблемные точки в бизнесе или любой другой деятельности и рассчитать, при каком сценарии их можно избежать их в будущем.
С помощью Big Data и современных технологий можно выявить проблемные точки в бизнесе или любой другой деятельности и рассчитать, при каком сценарии их можно избежать их в будущем.
Сеть медицинских центров Aurora Health Care ежегодно экономит $6 млн за счет предписывающей аналитики: ей удалось снизить число повторных госпитализаций на 10% [5].
4. Диагностическая аналитика (diagnostic analytics) — использует данные, чтобы проанализировать причины произошедшего. Это помогает выявлять аномалии и случайные связи между событиями и действиями.
Например, Amazon анализирует данные о продажах и валовой прибыли для различных продуктов, чтобы выяснить, почему они принесли меньше дохода, чем ожидалось.
Данные обрабатывают и анализируют с помощью различных инструментов и технологий [6] [7]:
- Cпециальное ПО: NoSQL, MapReduce, Hadoop, R;
- Data mining — извлечение из массивов ранее неизвестных данных с помощью большого набора техник;
- ИИ и нейросети — для построения моделей на основе Big Data, включая распознавание текста и изображений. Например, оператор лотерей «Столото» сделал большие данные основой своей стратегии в рамках Data-driven Organization. С помощью Big Data и искусственного интеллекта компания анализирует клиентский опыт и предлагает персонифицированные продукты и сервисы;
- Визуализация аналитических данных — анимированные модели или графики, созданные на основе больших данных.
 Например, оператор лотерей «Столото» сделал большие данные основой своей стратегии в рамках Data-driven Organization. С помощью Big Data и искусственного интеллекта компания анализирует клиентский опыт и предлагает персонифицированные продукты и сервисы;
Например, оператор лотерей «Столото» сделал большие данные основой своей стратегии в рамках Data-driven Organization. С помощью Big Data и искусственного интеллекта компания анализирует клиентский опыт и предлагает персонифицированные продукты и сервисы;Примеры визуализации данных (data-driven animation)
Как отметил в подкасте РБК Трендов менеджер по развитию IoT «Яндекс.Облака» Александр Сурков, разработчики придерживаются двух критериев сбора информации:
- Обезличивание данных делает персональную информацию пользователей в какой-то степени недоступной;
- Агрегированность данных позволяет оперировать лишь со средними показателями.
Чтобы обрабатывать большие массивы данных в режиме онлайн используют суперкомпьютеры: их мощность и вычислительные возможности многократно превосходят обычные.
Big Data и Data Science — в чем разница?
Data Science или наука о данных — это сфера деятельности, которая подразумевает сбор, обработку и анализ данных, — структурированных и неструктурированных, не только больших. В ней используют методы математического и статистического анализа, а также программные решения. Data Science работает, в том числе, и с Big Data, но ее главная цель — найти в данных что-то ценное, чтобы использовать это для конкретных задач.
5
В каких отраслях уже используют Big Data?
«IoT-решение из области так называемого точного земледелия — это когда специальные метеостанции, которые стоят в полях, с помощью сенсоров собирают данные (температура, влажность) и с помощью передающих радио-GSM-модулей отправляют их на IoT-платформу. На ней посредством алгоритмов big data происходит обработка собранной с сенсоров информации и строится высокоточный почасовой прогноз погоды.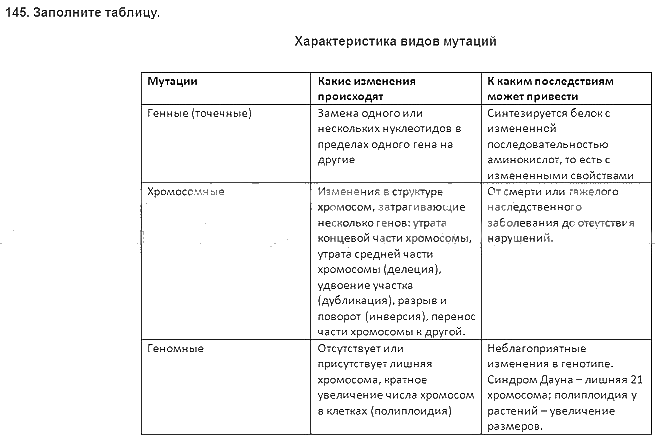 Клиент видит его в интерфейсе на компьютере, планшете или смартфоне и может оперативно принимать решения», — прокомментировали в «МегаФоне».
Клиент видит его в интерфейсе на компьютере, планшете или смартфоне и может оперативно принимать решения», — прокомментировали в «МегаФоне».
Подробнее — в материале «Умные» комбайны и дроны-геологи: как цифровизация меняет экономику».
6
Big Data в России и мире
По данным компании IBS [8], в 2012 году объем хранящихся в мире цифровых данных вырос на 50%: с 1,8 до 2,7 Збайт (2,7 трлн Гбайт). В 2015-м в мире каждые десять минут генерировалось столько же данных, сколько за весь 2003 год.
По данным компании NetApp, к 2003 году в мире накопилось 5 Эбайтов данных (1 Эбайт = 1 млрд Гбайт). В 2015-м — более 6,5 Збайта, причем тогда большие данные использовали лишь 17% компаний по всему миру [9]. Большую часть данных будут генерировать сами компании, а не их клиенты. При этом обычный пользователь будет коммуницировать с различными устройствами, которые генерируют данные, около 4 800 раз в день.
Первыми Big Data еще пять лет назад начали использовать в ИТ, телекоме и банках. Именно в этих сферах скапливается большой объем данных о транзакциях, геолокации, поисковых запросах и профилях в Сети. В 2019 году прибыль от использования больших данных оценивались в $189 млрд [10] — на 12% больше, чем в 2018-м, при этом к 2022 году она ежегодно будет удваиваться.
Именно в этих сферах скапливается большой объем данных о транзакциях, геолокации, поисковых запросах и профилях в Сети. В 2019 году прибыль от использования больших данных оценивались в $189 млрд [10] — на 12% больше, чем в 2018-м, при этом к 2022 году она ежегодно будет удваиваться.
Сейчас в США с большими данными работает более 55% компаний [11], в Европе и Азии — около 53%. Только за последние пять лет распространение Big Data в бизнесе выросло в три раза.
Как большие данные помогают онлайн-кинотеатрам подбирать персональные рекомендации
Мировыми лидерами по сбору и анализу больших данных являются США и Китай. Так, в США еще при Бараке Обаме правительство запустило шесть федеральных программ по развитию больших данных на общую сумму $200 млн. Главными потребителями Big Data считаются крупные корпорации, однако их деятельность по сбору данных ограничена в некоторых штатах — например, в Калифорнии.
В Китае действует более 200 законов и правил, касающихся защиты личной информации. С 2019 года все популярные приложения для смартфонов начали проверять и блокировать, если они собирают данные о пользователях вопреки законам. В итоге данные через местные сервисы собирает государство, и многие из них недоступны извне.
С 2019 года все популярные приложения для смартфонов начали проверять и блокировать, если они собирают данные о пользователях вопреки законам. В итоге данные через местные сервисы собирает государство, и многие из них недоступны извне.
С 2018 года в Евросоюзе действует GDPR — Всеобщий регламент по защите данных. Он регулирует все, что касается сбора, хранения и использования данных онлайн-пользователей. Когда закон вступил в силу год назад, он считался самой жесткой в мире системой защиты конфиденциальности людей в Интернете.
Подробнее — в материале «Цифровые войны: как искусственный интеллект и большие данные правят миром».
В России рынок больших данных только зарождается. К примеру, сотовые операторы делятся с банками информацией о потенциальных заемщиках [12]. Среди корпораций, которые собирают и анализируют данные — «Яндекс», «Сбер», Mail.ru. Появились специальные инструменты, которые помогают бизнесу собирать и анализировать Big Data — такие, как российский сервис Ctrl2GO.
7
Big Data в бизнесе
Большие данные полезны для бизнеса в трех главных направлениях:
- Запуск продуктов и сервисов, которые точнее всего «выстрелят» по потребностям целевой аудитории;
- Анализ клиентского опыта в отношении продукта или услуги, чтобы улучшить их;
- Привлечение и удержание клиентов с помощью аналитики.
Большие данные помогают MasterCard предотвращать мошеннические операции со счетами клиентов на сумму более $3 млрд в год [13]. Они позволяют рекламодателям эффективнее распределять бюджеты и размещать рекламу, которая нацелена на самых разных потребителей.
Крупные компании — такие, как Netflix, Procter & Gamble или Coca-Cola — с помощью больших данных прогнозируют потребительский спрос. 70% решений в бизнесе и госуправлении принимается на основе геоданных. Подробнее — в материале о том, как бизнес извлекает прибыль из Big Data.
8
Каковы проблемы и перспективы Big Data?
Главные проблемы:
- Большие данные неоднородны, поэтому их сложно обрабатывать для статистических выводов. Чем больше требуется параметров для прогнозирования, тем больше ошибок накапливается при анализе;
- Для работы с большими массивами данных онлайн нужны огромные вычислительные мощности. Такие ресурсы обходятся очень дорого, и пока что доступны только большим корпорациям;
- Хранение и обработка Big Data связаны с повышенной уязвимостью для кибератак и всевозможных утечек. Яркий пример — скандалы с профилями Facebook;
- Сбор больших данных часто связан с проблемой приватности: не все хотят, чтобы каждое их действие отслеживали и передавали третьим лицам. Герои подкаста «Что изменилось» объясняют, почему конфиденциальности в Сети больше нет, и технологическим гигантам известно о нас все;
- Большие данные используют в своих целях не только корпорации, но и политики: например, чтобы повлиять на выборы.
 Чем больше требуется параметров для прогнозирования, тем больше ошибок накапливается при анализе;
Чем больше требуется параметров для прогнозирования, тем больше ошибок накапливается при анализе;Плюсы и перспективы:
- Большие данные помогают решать глобальные проблемы — например, бороться с пандемией, находить лекарства от рака и предотвращать экологический кризис;
- Big Data — хороший инструмент для создания умных городов и решения проблемы транспорта;
- Большие данные помогают экономить средства даже на государственном уровне: например, в Германии вернули в бюджет около €15 млрд [14], обнаружив, что часть граждан получают пособие по безработице без всяких оснований. Их вычислили с помощью транзакций.
 Их вычислили с помощью транзакций.
Их вычислили с помощью транзакций.Как Big Data и ИИ меняют наше представление о справедливости
В ближайшем будущем большие данные станут главным инструментом для принятия решений — начиная с сетевых бизнесов и заканчивая целыми государствами и международными организациями [15].
Изменчивость культуры и объяснения
Культурная изменчивость и объяснения
Культурная изменчивость относится к
разнообразие культурных и социальных сфер. Так как разные компании имеют разные
культуры. Разнообразие человеческой культуры поразительно. Ценности и обычаи
В разных культурах поведение часто радикально отличается друг от друга (метла и
Слезнки, 1973). Например, евреи едят свинину, а индусы едят свинину, но избегают
говядина. Культурное разнообразие или различия как между обществами, так и внутри них
общество. Если мы возьмем две авиакомпании,
Культурное разнообразие или различия как между обществами, так и внутри них
общество. Если мы возьмем две авиакомпании,
и
Индия, с большими, резкими культурными различиями между двумя общинами. На С другой стороны, одно и то же общество отличается культурной изменчивостью. Культурный изменчивость между обществом может привести к различным состояниям здоровья и заболеваниям. Таким образом, различия в диетических привычках, тесно связанные с этими типами болезни. Распространение ленточных червей у людей, употребляющих сырое мясо, может быть хорошим пример.
Мы используем понятие субкультуры, чтобы выявить изменчивость культур внутри конкретного общества. Субкультура это культура, разделяемая группой внутри общества (Stockard, 1997). Мы называем эти субкультурные группы (и их субкультуры) существуют внутри и как меньшие частью более крупной доминирующей культуры. Примером субкультуры является культура студенты университетов, беспризорники и проститутки в
Аддис-Абебе Абаба, культура медицинских работников,
и т. д.
д.
Почему культура отличается от компании к компания? Социологи, антропологи, культурные географы и другие социальные ученые для изучения причин культурных различий (между) общества. Много аргументов приводилось разнообразие, в том числе географические факторы, раса детерминация, демографические факторы охватывают интересы и чисто исторические возможность. Те, кто разделял его мнение о том, что культурные различия генетическая расовая детерминация. К географическим факторам относятся: климат, высота над уровнем моря, и др. Наряду с демографическими факторами происходят изменения в структуре население, рост населения и т. д., в то время как перенапряжение важной цели культуры варьируется от человека к человеку заинтересованная жизнь также меняется. Культурное разнообразие благодаря почти исторической возможности; определенная группа людей может развивать культуры при воздействии определенных исторических событий и возможностей.
Однако объяснения недостаточно для
сам; антропологи сейчас отвергают весьма детерминистские объяснения, такие как
основанные на расе; а не культурные различия объясняются более
целостное заявление.
Центральная тенденция и изменчивость — Социология 3112 — Факультет социологии
Цели обучения
- Понять и рассчитать три способа определения центра распределения
- Понять и рассчитать четырьмя способами величину дисперсии или изменчивости в распределении можно определить
- Понять, как перекос и уровень измерения могут помочь определить, какие меры центральная тенденция и изменчивость наиболее подходят для данного распределения
Ключевые термины
Показатели центральной тенденции: категории или оценки, описывающие, что является «средним» или «типичным» для данного распределения. К ним относятся мода, медиана и среднее значение.
К ним относятся мода, медиана и среднее значение.
Процентиль: показатель, ниже которого падает определенный процент данного распределения.
Распределение с положительной асимметрией: распределение с несколькими очень большими значениями.
Распределение с отрицательной асимметрией: — дистрибутив с несколькими чрезвычайно низкими значениями.
Показатели изменчивости: числа, описывающие разнообразие или дисперсию в распределении данного
переменная.
Блочная диаграмма: графическое представление размаха, межквартильного размаха и медианы заданного
переменная.
Мода
Мода — категория с наибольшей частотой (или процентом). Это не
сама частота. Другими словами, если кто-то спросит вас о режиме раздачи
показано ниже, ответом будет кокосовый орех, а НЕ 22. Возможно иметь более
один режим в распределении. Такие распределения считаются бимодальными (если
два режима) или мультимодальный (если режимов больше двух). Дистрибутивы без
четкая мода называется однородной. Режим не особо полезный, но он есть
единственная мера центральной тенденции, которую мы можем использовать с номинальными переменными. Ты найдешь
почему это единственная подходящая мера для номинальных переменных, когда мы узнаем о
медиана и среднее значение рядом.
Возможно иметь более
один режим в распределении. Такие распределения считаются бимодальными (если
два режима) или мультимодальный (если режимов больше двух). Дистрибутивы без
четкая мода называется однородной. Режим не особо полезный, но он есть
единственная мера центральной тенденции, которую мы можем использовать с номинальными переменными. Ты найдешь
почему это единственная подходящая мера для номинальных переменных, когда мы узнаем о
медиана и среднее значение рядом.
Любимые вкусы мороженого:
Кокос = 22
Шоколад = 15
Ваниль = 7
Клубника = 9
Медиана
Медиана — это самое среднее число. Другими словами, это число, которое делит
распределение ровно пополам, так что половина случаев выше медианы, и
половина ниже. Он также известен как 50-й процентиль, и его можно рассчитать для
порядковые переменные и переменные интервала/отношения. Концептуально найти медиану довольно просто.
и влечет за собой только упорядочивание всех ваших наблюдений от наименьшего к наибольшему.
а затем найти любое число, попадающее в середину. Обратите внимание, что нахождение медианы
требует сначала упорядочить все наблюдения от меньшего к большему. Вот почему
медиана не является подходящей мерой центральной тенденции для номинальных переменных,
поскольку номинальные переменные не имеют внутреннего порядка. (На практике нахождение медианы может
быть немного более вовлеченным, особенно если у вас есть большое количество наблюдений — см.
ваш учебник для объяснения того, как найти медиану в таких ситуациях).
Он также известен как 50-й процентиль, и его можно рассчитать для
порядковые переменные и переменные интервала/отношения. Концептуально найти медиану довольно просто.
и влечет за собой только упорядочивание всех ваших наблюдений от наименьшего к наибольшему.
а затем найти любое число, попадающее в середину. Обратите внимание, что нахождение медианы
требует сначала упорядочить все наблюдения от меньшего к большему. Вот почему
медиана не является подходящей мерой центральной тенденции для номинальных переменных,
поскольку номинальные переменные не имеют внутреннего порядка. (На практике нахождение медианы может
быть немного более вовлеченным, особенно если у вас есть большое количество наблюдений — см.
ваш учебник для объяснения того, как найти медиану в таких ситуациях).
Некоторые из вас, вероятно, уже задаются вопросом: «Что произойдет, если у вас есть четное число
случаев? Тогда среднего числа не будет, верно?» Это очень проницательное замечание,
и я рад, что вы спросили. Если в вашем наборе данных четное количество случаев, медиана равна
среднее из двух средних чисел. Например, для чисел 18, 14, 12,
8, 6 и 4 медиана равна 10 (12 + 8 = 20; 20/2 = 10).
Если в вашем наборе данных четное количество случаев, медиана равна
среднее из двух средних чисел. Например, для чисел 18, 14, 12,
8, 6 и 4 медиана равна 10 (12 + 8 = 20; 20/2 = 10).
Одним из преимуществ медианы является то, что она не чувствительна к выбросам. Выброс это наблюдение, которое находится на аномальном расстоянии от других значений в выборке. Наблюдения которые значительно больше или меньше других в выборке, могут повлиять на некоторые статистические показатели таким образом, что они вводят в заблуждение, но медиана невосприимчив к ним. Другими словами, не имеет значения, является ли самое большое число 20 или 20 000; он по-прежнему считается только одним числом. Рассмотрим следующее:
Распределение 1: 1, 3, 5, 7, 20
Распределение 2: 1, 3, 5, 7, 20 000
Эти два распределения имеют одинаковые медианы, хотя распределение 2 имеет очень
большой выброс, что в конечном итоге приведет к довольно значительному искажению среднего значения, как мы
увидеть через мгновение.
Среднее
Среднее — это то, что люди обычно называют «средним». это высшая мера центральной тенденции, под которой я подразумеваю, что он доступен для использования только с интервалом/соотношением переменные. Среднее значение учитывает ценность каждого наблюдения и, таким образом, обеспечивает самая информативная из всех мер центральной тенденции. Однако, в отличие от медианы, среднее значение чувствительно к выбросам. Другими словами, один чрезвычайно высокий (или низкий) значение в вашем наборе данных может значительно повысить (или понизить) среднее значение. Среднее, часто отображается как переменная x или y с линией над ней (произносится как «x-bar» или «y-bar»), это сумма всех баллов, деленная на общее количество баллов. В статистическом обозначение, мы бы записали его следующим образом:
В этом уравнении — среднее значение, X — значение каждого наблюдения, а N — общее значение. количество дел. Сигма (Σ) просто говорит нам сложить все оценки вместе.
Тот факт, что вычисление среднего требует сложения и деления, является той самой причиной.
его нельзя использовать ни с номинальными, ни с порядковыми переменными. Мы не можем вычислить среднее
для расы (белый + белый + черный/3 = ?) не больше, чем мы можем вычислить среднее значение за год
в школе (первокурсник + первокурсник + старший/3 = ?)
количество дел. Сигма (Σ) просто говорит нам сложить все оценки вместе.
Тот факт, что вычисление среднего требует сложения и деления, является той самой причиной.
его нельзя использовать ни с номинальными, ни с порядковыми переменными. Мы не можем вычислить среднее
для расы (белый + белый + черный/3 = ?) не больше, чем мы можем вычислить среднее значение за год
в школе (первокурсник + первокурсник + старший/3 = ?)
Процентили
Процентиль — это число, ниже которого падает определенный процент распределения.
Например, если вы набрали 90-й процентиль на тесте, 90 процентов учащихся
кто прошел тест набрал меньше вас. Если вы набрали 72-й процентиль на тесте,
72 процента учащихся, сдавших тест, набрали меньше, чем вы. Если забит в 5-м
процентиль на тесте, возможно, этот предмет не для вас. Медиана, как вы помните, падает
на 50-м процентиле. Пятьдесят процентов наблюдений попадают ниже него.
Медиана, как вы помните, падает
на 50-м процентиле. Пятьдесят процентов наблюдений попадают ниже него.
Симметричное и асимметричное распределения
Симметричное распределение – это распределение, в котором среднее значение, медиана и мода являются
такой же. С другой стороны, асимметричное распределение — это распределение с экстремальными значениями.
с той или иной стороны, которые заставляют медиану отклоняться от среднего в одном направлении
или другое. Если среднее значение больше медианы, говорят, что распределение
быть положительно перекошены. Другими словами, существует чрезвычайно большое значение, которое «тянет»
среднее к верхнему концу распределения. Если среднее значение меньше, чем
медиану, говорят, что распределение имеет отрицательную асимметрию. Другими словами, существует
чрезвычайно малое значение, которое «тянет» среднее значение к нижнему концу распределения.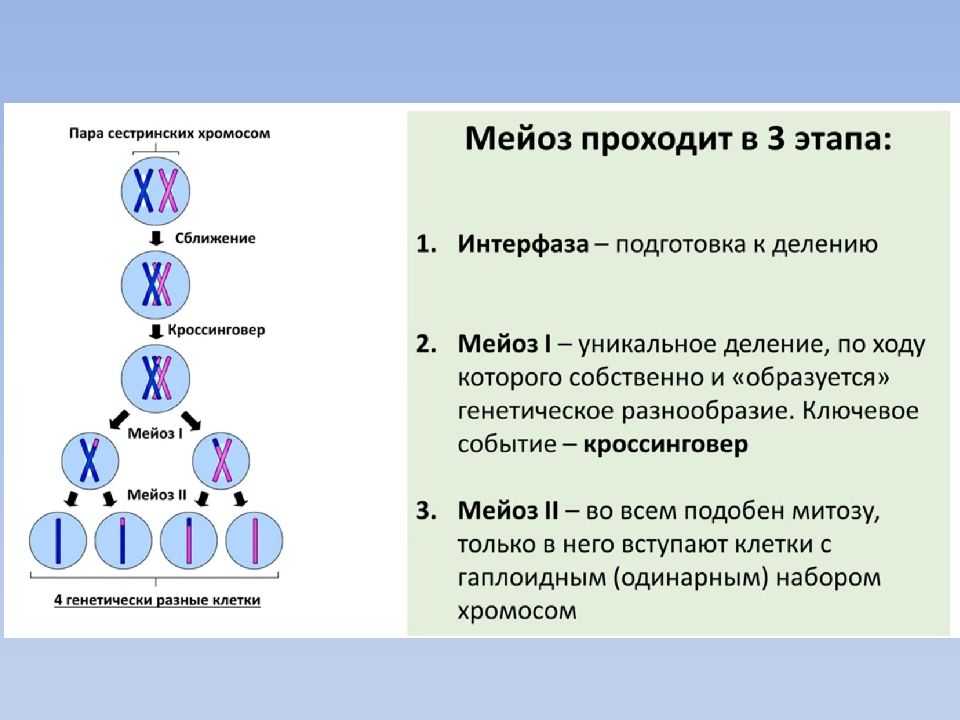 Распределение доходов обычно имеет положительную асимметрию из-за небольшого количества
люди, которые зарабатывают невероятные суммы денег. Рассмотрим (по общему признанию датированный) случай
Футболисты Высшей лиги как крайний пример. Средняя годовая зарплата MLS
игрок в 2010 году составлял примерно 138 000 долларов, но средняя годовая зарплата составляла всего около
53 000 долларов. Среднее значение было почти в три раза больше, чем медиана, в немалой степени благодаря
часть к тогдашней зарплате Дэвида Бекхэма в размере 12 миллионов долларов.
Распределение доходов обычно имеет положительную асимметрию из-за небольшого количества
люди, которые зарабатывают невероятные суммы денег. Рассмотрим (по общему признанию датированный) случай
Футболисты Высшей лиги как крайний пример. Средняя годовая зарплата MLS
игрок в 2010 году составлял примерно 138 000 долларов, но средняя годовая зарплата составляла всего около
53 000 долларов. Среднее значение было почти в три раза больше, чем медиана, в немалой степени благодаря
часть к тогдашней зарплате Дэвида Бекхэма в размере 12 миллионов долларов.
Пытаясь решить, какую меру центральной тенденции использовать, вы должны учитывать
как уровень измерения, так и перекос. Дело обстоит не так для именных и порядковых
переменные. Если переменная является номинальной, очевидно, что мода является единственной мерой центральной
склонность к употреблению. Если переменная порядковая, медиана, вероятно, ваш лучший выбор
потому что он предоставляет больше информации об образце, чем режим. Но если
переменная — интервал/отношение, вам нужно определить, является ли распределение симметричным
или перекошенный. Если распределение симметрично, то среднее является лучшей мерой центральной
тенденция. Если распределение асимметрично как в положительную, так и в отрицательную сторону, медиана
является более точным. В качестве примера того, почему среднее значение может быть не лучшим показателем центрального
тенденцию к асимметричному распределению, рассмотрите следующий отрывок из книги Чарльза Уилана.
Обнаженная статистика: избавление от страха из данных (2013):
Если переменная порядковая, медиана, вероятно, ваш лучший выбор
потому что он предоставляет больше информации об образце, чем режим. Но если
переменная — интервал/отношение, вам нужно определить, является ли распределение симметричным
или перекошенный. Если распределение симметрично, то среднее является лучшей мерой центральной
тенденция. Если распределение асимметрично как в положительную, так и в отрицательную сторону, медиана
является более точным. В качестве примера того, почему среднее значение может быть не лучшим показателем центрального
тенденцию к асимметричному распределению, рассмотрите следующий отрывок из книги Чарльза Уилана.
Обнаженная статистика: избавление от страха из данных (2013):
«Среднее, или среднее, оказывается, имеет некоторые проблемы, а именно, что оно склонно к
искажение «выбросами», которые являются наблюдениями, лежащими дальше от центра. Чтобы понять эту концепцию, представьте, что десять парней сидят на барных стульях.
в питейном заведении среднего класса в Сиэтле; каждый из этих парней зарабатывает 35 000 долларов
в год, что составляет средний годовой доход группы 35 000 долларов. Билл Гейтс ходит
в бар с говорящим попугаем на плече. (У попугая нет ничего
как пример, но это как бы оживляет ситуацию.) Давайте предположим, ради
Например, годовой доход Билла Гейтса составляет 1 миллиард долларов. Когда Билл сидит
сидя на одиннадцатом барном стуле, средний годовой доход посетителей бара возрастает до
около 9 долларов1 миллион. Очевидно, что никто из первых десяти пьющих не стал богаче (хотя
было бы разумно ожидать, что Билл Гейтс купит раунд или два). Если бы я описал
посетители этого бара имеют средний годовой доход в размере 91 миллиона долларов, говорится в заявлении.
Чтобы понять эту концепцию, представьте, что десять парней сидят на барных стульях.
в питейном заведении среднего класса в Сиэтле; каждый из этих парней зарабатывает 35 000 долларов
в год, что составляет средний годовой доход группы 35 000 долларов. Билл Гейтс ходит
в бар с говорящим попугаем на плече. (У попугая нет ничего
как пример, но это как бы оживляет ситуацию.) Давайте предположим, ради
Например, годовой доход Билла Гейтса составляет 1 миллиард долларов. Когда Билл сидит
сидя на одиннадцатом барном стуле, средний годовой доход посетителей бара возрастает до
около 9 долларов1 миллион. Очевидно, что никто из первых десяти пьющих не стал богаче (хотя
было бы разумно ожидать, что Билл Гейтс купит раунд или два). Если бы я описал
посетители этого бара имеют средний годовой доход в размере 91 миллиона долларов, говорится в заявлении. будет одновременно статистически правильным и вводит в заблуждение [Примечание: медиана будет
оставаться без изменений]. Это не бар, где тусуются мультимиллионеры; это бар, где
куча парней с относительно низким доходом сидит рядом с Биллом Гейтсом
и его говорящий попугай».
будет одновременно статистически правильным и вводит в заблуждение [Примечание: медиана будет
оставаться без изменений]. Это не бар, где тусуются мультимиллионеры; это бар, где
куча парней с относительно низким доходом сидит рядом с Биллом Гейтсом
и его говорящий попугай».
Показатели изменчивости
В дополнение к определению показателей центральной тенденции нам может понадобиться подвести итоги. количество изменчивости, которое мы имеем в нашем распределении. Другими словами, нам необходимо определить, имеют ли наблюдения тенденцию группироваться вместе или они имеют тенденцию к разбросу вне. Рассмотрим следующий пример:
Образец 1: {0, 0, 0, 0, 25}
Образец 2: {5, 5, 5, 5, 5}
Обе эти выборки имеют одинаковые средние значения (5) и одинаковое количество наблюдений
(n = 5), но степень вариации между двумя выборками значительно различается. Образец 2 не имеет изменчивости (все оценки одинаковы), тогда как образец 1 имеет
относительно больше (один случай существенно отличается от четырех других). В этом курсе
мы рассмотрим четыре показателя изменчивости: диапазон, межквартильный
диапазон (IQR), дисперсия и стандартное отклонение.
Образец 2 не имеет изменчивости (все оценки одинаковы), тогда как образец 1 имеет
относительно больше (один случай существенно отличается от четырех других). В этом курсе
мы рассмотрим четыре показателя изменчивости: диапазон, межквартильный
диапазон (IQR), дисперсия и стандартное отклонение.
Диапазон
Диапазон — это разница между самым высоким и самым низким баллами в наборе данных и является простейшей мерой распространения. Мы рассчитываем диапазон, вычитая наименьший значение от наибольшего значения. В качестве примера рассмотрим следующий набор данных:
23 | 56 | 45 | 65 | 69 | 55 | 62 | 54 | 85 | 25 |
Максимальное значение равно 85, а минимальное значение равно 23. Это дает нам диапазон 62 (85
– 23 = 62). Хотя использование диапазона в качестве меры изменчивости мало что нам говорит,
это дает нам некоторую информацию о том, как далеко друг от друга самые низкие и самые высокие оценки
являются.
Это дает нам диапазон 62 (85
– 23 = 62). Хотя использование диапазона в качестве меры изменчивости мало что нам говорит,
это дает нам некоторую информацию о том, как далеко друг от друга самые низкие и самые высокие оценки
являются.
Квартили и межквартильный диапазон
«Квартиль» — еще одно слово, которое знатоки статистики используют, чтобы почувствовать себя важными. В основном это означает «четверть» или «четверть». Футбольный матч имеет четыре квартили, как и Твикс королевского размера. Найти квартили распределения так же просто, как разбить на четверти. Каждая четвертая содержит 25 процентов от общего числа наблюдений.
Квартили делят ранжированный набор данных на четыре равные части. Ценности, которые разделяют
каждая часть называется первой, второй и третьей квартилями; и они обозначаются
на Q1, Q2 и Q3 соответственно.
Q1 — это «среднее» значение в первой половине ранжированного набора данных.
Q2 — среднее значение набора данных
Q3 — «среднее» значение второй половины ранжированного набора данных
Q4 технически было бы самым большим значением в наборе данных, но мы игнорируем его при расчете
IQR (мы уже имели дело с ним, когда рассчитывали диапазон).
Таким образом, межквартильный размах равен Q3 минус Q1 (или 75-й процентиль минус
25-й процентиль, если вы предпочитаете так думать). В качестве примера рассмотрим
следующие числа: 1, 3, 4, 5, 5, 6, 7, 11. Q1 — среднее значение в первой
половина набора данных. Поскольку в первой половине четное количество точек данных
набора данных среднее значение является средним из двух средних значений; то есть,
Q1 = (3 + 4)/2 или Q1 = 3,5. Q3 — среднее значение во второй половине данных.
набор. Опять же, поскольку вторая половина набора данных имеет четное количество наблюдений,
среднее значение является средним из двух средних значений; то есть Q3 = (6 + 7)/2
или Q3 = 6,5. Межквартильный размах равен Q3 минус Q1, поэтому IQR = 6,5 — 3,5 = 3.
Q3 — среднее значение во второй половине данных.
набор. Опять же, поскольку вторая половина набора данных имеет четное количество наблюдений,
среднее значение является средним из двух средних значений; то есть Q3 = (6 + 7)/2
или Q3 = 6,5. Межквартильный размах равен Q3 минус Q1, поэтому IQR = 6,5 — 3,5 = 3.
Ящичные диаграммы
Ящичная диаграмма (также известная как диаграмма с ячейками и усами) разбивает набор данных на квартили.
Тело боксплота состоит из «коробки» (отсюда и название), которая происходит от
от первого квартиля (Q1) до третьего квартиля (Q3). Внутри поля горизонтальная линия
рисуется в Q2, что обозначает медиану набора данных. Две вертикальные линии, известные
как усы, простираются от верхней и нижней части коробки. Нижний ус идет от
Q1 до наименьшего значения в наборе данных, а верхний ус идет от Q3 до
наибольшее значение. Ниже приведен пример коробчатой диаграммы с положительной асимметрией с различными
компоненты промаркированы.
Ниже приведен пример коробчатой диаграммы с положительной асимметрией с различными
компоненты промаркированы.
Выбросы – это экстремальные значения, которые по той или иной причине исключены из набора данных. Если набор данных включает один или несколько выбросов, они отображаются на графике. отдельно как точки на графике. На приведенной выше диаграмме есть несколько выбросов внизу.
Как интерпретировать прямоугольную диаграмму
Горизонтальная линия, проходящая через центр прямоугольника, указывает, где находится медиана
падает. Кроме того, ящичные диаграммы отображают две общие меры изменчивости или разброса.
в наборе данных: диапазон и IQR. Если вас интересует распространение всех
данные, он представлен на диаграмме вертикальным расстоянием между наименьшими
значение и наибольшее значение, включая любые выбросы. Средняя половина набора данных
попадает в межквартильный диапазон. На диаграмме представлен межквартильный диапазон
по ширине коробки (Q3 минус Q1).
Средняя половина набора данных
попадает в межквартильный диапазон. На диаграмме представлен межквартильный диапазон
по ширине коробки (Q3 минус Q1).
Дисперсия
Дисперсия — это мера изменчивости, которая показывает, насколько далеко каждое наблюдение падает из среднего распределения. Для этого примера мы будем использовать следующее пять цифр, которые представляют собой мои ежемесячные покупки комиксов за последний пять месяцев:
2, 3, 5, 6, 9
Формула расчета дисперсии обычно записывается так:
Это уравнение выглядит пугающе, но оно не так уж плохо, если разбить его на
его составные части. S2x — это обозначение, используемое для обозначения дисперсии выборки.
Эта гигантская сигма (Σ) является знаком суммирования; это просто означает, что мы собираемся добавлять вещи
вместе. X представляет каждое из наших наблюдений, а x с линией над ним
(часто называемый «x-bar») представляет собой среднее значение нашего распределения. Столица «N» на
внизу общее количество наблюдений. В принципе, эта формула говорит
нам вычесть среднее значение из каждого из наших наблюдений, возвести в квадрат разницу, добавить
их все вместе и разделить на N-1. Давайте сделаем пример, используя приведенные выше числа.
X представляет каждое из наших наблюдений, а x с линией над ним
(часто называемый «x-bar») представляет собой среднее значение нашего распределения. Столица «N» на
внизу общее количество наблюдений. В принципе, эта формула говорит
нам вычесть среднее значение из каждого из наших наблюдений, возвести в квадрат разницу, добавить
их все вместе и разделить на N-1. Давайте сделаем пример, используя приведенные выше числа.
1. Первым шагом в вычислении дисперсии является нахождение среднего значения распределения. В этом случае среднее значение равно 5 (2+3+5+6+9 = 25; 25/5 = 5).
2. Второй шаг – вычесть среднее значение (5) из каждого наблюдения:
2-5 = -3
3-5 = -2
5-5 = 0
6-5 = 1
9 -5 = 4
Обратите внимание: мы можем проверить нашу работу после этого шага, сложив все наши значения вместе. Если их сумма равна нулю, мы знаем, что мы на правильном пути. Если они добавляют к чему-то
помимо нуля, нам, вероятно, следует еще раз проверить нашу математику (-3+-2+0+1+4 = 0, мы золотые).
Если их сумма равна нулю, мы знаем, что мы на правильном пути. Если они добавляют к чему-то
помимо нуля, нам, вероятно, следует еще раз проверить нашу математику (-3+-2+0+1+4 = 0, мы золотые).
3. В-третьих, возводим каждый из этих ответов в квадрат, чтобы избавиться от отрицательных чисел:
(-3)2 = 9
(-2)2 = 4
(0)2 = 0
(1)2 = 1
(4)2 = 16
4. В-четвертых, складываем их все вместе:
9+4+0+1+16=30
5. Наконец, делим на N-1 (общее количество наблюдений равно 5, поэтому 5-1 =4)
30/4 = 7,5
После всех этих довольно утомительных вычислений у нас осталось одно число, которое
быстро и кратко суммирует количество изменчивости в нашем распределении.
чем больше число, тем больше изменчивость в нашем распределении. Пожалуйста, обрати внимание:
дисперсия никогда не может быть отрицательной. Если вы получите дисперсию меньше, чем
ноль, вы сделали что-то не так.
Если вы получите дисперсию меньше, чем
ноль, вы сделали что-то не так.
Стандартное отклонение
Однако существует одно ограничение на использование дисперсии в качестве единственной меры изменчивости. Когда мы возводим числа в квадрат, чтобы избавиться от минусов (шаг 3), мы также непреднамеренно квадрат наша единица измерения. Другими словами, если бы мы говорили о милях, мы случайно превратил нашу единицу измерения в квадратные мили. Если бы мы говорили про комиксы, мы случайно превратили нашу единицу измерения в комиксы в квадрате (что, разумеется, не всегда имеет большой смысл). Для того, чтобы решить эту проблему, мы вычисляем стандартное отклонение. Формула стандарта отклонение выглядит следующим образом:
Другими словами, рассчитать стандартное отклонение так же просто, как взять квадрат
корень из дисперсии, обращая в квадрат квадрат, который мы сделали при вычислении дисперсии. В нашем примере стандартное отклонение равно квадратному корню из 7,5 или 2,74.
Интерпретация не меняется; большое стандартное отклонение свидетельствует о большей
изменчивость, в то время как небольшое стандартное отклонение свидетельствует об относительно небольшой
количество изменчивости. Как и в случае с дисперсией, стандартное отклонение равно
всегда позитивный.
В нашем примере стандартное отклонение равно квадратному корню из 7,5 или 2,74.
Интерпретация не меняется; большое стандартное отклонение свидетельствует о большей
изменчивость, в то время как небольшое стандартное отклонение свидетельствует об относительно небольшой
количество изменчивости. Как и в случае с дисперсией, стандартное отклонение равно
всегда позитивный.
Помните: основное различие между дисперсией и стандартным отклонением заключается в единица измерения. Мы вычисляем стандартное отклонение, чтобы положить нашу переменную вернуться к исходной метрике. «Мили в квадрате» возвращаются к просто милям, и «Комиксы в квадрате» снова стали просто комиксами.
Основные моменты
- Показатели центральной тенденции говорят нам, что является общим или типичным в нашей переменной.
- Тремя мерами центральной тенденции являются мода, медиана и среднее значение.
- Режим используется почти исключительно с данными номинального уровня, так как это единственная мера центральной тенденции, доступной для таких переменных. Медиана используется с порядковым номером данных или когда переменная уровня интервала/отношения искажена (вспомните пример Билла Гейтса). Среднее значение можно использовать только с данными уровня интервала/отношения.
- Показатели изменчивости — это числа, описывающие степень изменчивости или разнообразия есть в раздаче.
- Четыре меры изменчивости — диапазон (разница между большим и
наименьшие наблюдения), межквартильный размах (разница между 75-м и
25-й процентиль) дисперсия и стандартное отклонение.
- Дисперсия и стандартное отклонение являются двумя тесно связанными показателями изменчивости. для переменных уровня интервала/отношения, которые увеличиваются или уменьшаются в зависимости от того, насколько близко наблюдения сгруппированы вокруг среднего значения.
- Показатели центральной тенденции и изменчивости в SPSS


Чтобы программа SPSS рассчитала для вас показатели центральной тенденции и изменчивости, щелкните
«Анализ», «Описательная статистика», затем «Частоты». Меры центральной тенденции
и изменчивость также можно рассчитать, нажав «Описание» или «Исследовать»,
но «Частоты» дает вам больше контроля и имеет наиболее полезные параметры для выбора
от. Открывшееся диалоговое окно должно быть вам уже знакомо. Как вы сделали
при расчете частотных таблиц переместите переменные, для которых вы хотите
рассчитать меры центральной тенденции и изменчивости в правой части
коробка. Вы можете снять флажок «Отображать частотные таблицы», если не хотите
видеть любые таблицы и предпочел бы видеть только статистику. Затем нажмите кнопку
справа с надписью «Статистика». В открывшемся диалоговом окне вы можете выбрать
любую статистику по вашему желанию (Примечание: SPSS использует термин «дисперсия», а не
«Изменчивость», но эти два слова являются синонимами). Также имейте в виду, что SPSS
вычислит статистику для любой переменной независимо от уровня измерения. Это
будет, например, вычислять среднее значение для расы или пола, даже если это не имеет смысла
что угодно. Мужчина + мужчина + женщина/3 = 0,66? Совершенно нелогично.
Как вы сделали
при расчете частотных таблиц переместите переменные, для которых вы хотите
рассчитать меры центральной тенденции и изменчивости в правой части
коробка. Вы можете снять флажок «Отображать частотные таблицы», если не хотите
видеть любые таблицы и предпочел бы видеть только статистику. Затем нажмите кнопку
справа с надписью «Статистика». В открывшемся диалоговом окне вы можете выбрать
любую статистику по вашему желанию (Примечание: SPSS использует термин «дисперсия», а не
«Изменчивость», но эти два слова являются синонимами). Также имейте в виду, что SPSS
вычислит статистику для любой переменной независимо от уровня измерения. Это
будет, например, вычислять среднее значение для расы или пола, даже если это не имеет смысла
что угодно. Мужчина + мужчина + женщина/3 = 0,66? Совершенно нелогично. Это один из многих
обстоятельства, в которых вам придется быть умнее, чем пакет анализа данных
ты используешь. То, что SPSS позволяет вам что-то делать, не обязательно означает
это хорошая идея.
Это один из многих
обстоятельства, в которых вам придется быть умнее, чем пакет анализа данных
ты используешь. То, что SPSS позволяет вам что-то делать, не обязательно означает
это хорошая идея.
При расчете показателей изменчивости иногда полезно включить квадрат
сюжет. Для этого нажмите «Графики», затем «Устаревшие диалоги» и выберите «Коробчатая диаграмма». Как
было в случае с графиками, которые вы создали в предыдущей главе, у вас будет несколько
варианты, из которых можно выбрать. Вообще говоря, вам понадобится по одной ящичковой диаграмме для каждого
переменной, поэтому выберите «Сводка отдельных переменных». Переместите переменные, которые вы
хотел бы, чтобы отображались в виде диаграмм в пустом поле справа, и нажмите «ОК».
Если вы хотите отредактировать свои боксплоты, вы можете сделать это почти так же, как вы это делали. графики в главе 2. Вот пошаговое видео:
графики в главе 2. Вот пошаговое видео:
Упражнения
- Выберите три переменные из любого из трех наборов данных (одну номинальную, одну порядковую и один интервал/отношение) и рассчитать все соответствующие меры центральной тенденции для каждый.
- Используя набор данных ADD Health, набор данных NIS и обзор мировых ценностей, рассчитайте
стандартное отклонение, дисперсия и диапазон для переменной «ВОЗРАСТ» в каждом из них. Какой опрос
имеет наибольшую вариацию по возрасту? Какое обследование имеет наименьшую вариацию по возрасту? (Примечание:
для этого вам потребуется открыть набор данных, рассчитать меры изменчивости и
затем откройте следующий набор данных.

Leave A Comment