
ОГЭ Информатика Тест задание 1 Количество информации в тексте
ОГЭ Информатика Тест задание 1 Количество информации в тексте| Правильно | Ошибки | Пустые ответы |
|---|---|---|
×

 Двоичная система счисления
Двоичная система счисленияПодготовка к ОГЭ по Информатике
Задания на тему «Количество информации в тексте».
 Категория вопросов:
Все категории задания Информационный объем текста
Категория вопросов:
Все категории задания Информационный объем текста1) Текст рассказа имеет информационный объём 15 Кбайт. Текст занимает 10 страниц, на каждой странице одинаковое количество строк, в каждой строке 64 символа. Все символы представлены в кодировке Unicode. В используемой версии Unicode каждый символ кодируется 2 байтами. Определите, сколько строк помещается на каждой странице.
48 строк
12 строк
32 строки
24 строки
2) Сколько различных символов можно закодировать с помощью 7-битной кодировки ASCII?
64 символа
128 символа
256 символа
512 символа
3)
Для получения годовой оценки по истории ученику требовалось написать доклад на 16 страниц. Выполняя это задание на компьютере, он набирал текст в кодировке Windows. Какой объём памяти (в Кбайтах) займет доклад, если в каждой строке по 64 символа, а на каждой странице помещается 64 строки? Каждый символ в кодировке Windows занимает 8 бит памяти.
Выполняя это задание на компьютере, он набирал текст в кодировке Windows. Какой объём памяти (в Кбайтах) займет доклад, если в каждой строке по 64 символа, а на каждой странице помещается 64 строки? Каждый символ в кодировке Windows занимает 8 бит памяти.
256 Кб
128 Кб
32 Кб
64 Кб
4) В кодировке Windows–1251 при кодировании одного символа используется 8 бит информации.Сколько различных символов можно закодировать с помощью Windows–1251?
64 символа
128 символа
256 символа
512 символа
5)
Автоматическое устройство осуществило перекодировку информационного сообщения, первоначально записанного в 7-битном коде ASCII, в 16-битную кодировку Unicode.
22 символов
12 символов
14 символов
8 символов
6) Главный редактор журнала отредактировал статью, и её объём уменьшился на 4 страницы. Каждая страница содержит 32 строки, в каждой строке 64 символа. Информационный объём статьи до редактирования был равен 1 Мбайт. Статья представлена в кодировке Unicode, в которой каждый символ кодируется 2 байтами. Определите информационный объём статьи в Кбайтах в этом варианте представления Unicode после редактирования.
1024 КБ
504 Кб
1008 Кб
248 Кб
7)
Автоматическое устройство осуществило перекодировку информационного сообщения длиной 48 символов, первоначально записанного в 7–битном коде ASCII, в 16–битную кодировку Unicode.
96 байт
48 байт
432 байт
54 байт
8) Статья, набранная в текстовом редакторе, содержит 64 страницы, на каждой странице 40 строк, в каждой строке 48 символов. Определите размер статьи в кодировке КОИ-8, в которой каждый символ кодируется 8 битами.
240 Кбайт
120 Кбайт
960 байт
1920 байт
9)
Информационное сообщение объёмом 1,5 Кбайта содержит 3072 символа.
4 бита
8 бит
16 бит
32 бита
10) Автоматическое устройство осуществило перекодировку информационного сообщения на русском языке, первоначально записанного в 16–битном коде Unicode, в 8–битную кодировку Windows–1251, при этом информационный объем сообщения составил 60 байт. Определите информационный объем сообщения до перекодировки.
960 бит
60 байт
120 бит
60 бит
11)
В кодировке Unicode на каждый символ отводится два байта. Определите информационный объем слова из двадцати четырех символов в этой кодировке.
Определите информационный объем слова из двадцати четырех символов в этой кодировке.
256 бит
48 бит
192 бита
384 бита
12) Автоматическое устройство осуществило перекодировку информационного сообщения на русском языке, первоначально записанного в 16-битном коде Unicode, в 8-битную кодировку КОИ-8. При этом информационное сообщение уменьшилось на 800 бит. Какова длина сообщения в символах?
100 символов
150 символов
50 символов
200 символов
13)
Информационный объем сообщения, содержащего 1024 символа, составляет 2 Кбайта.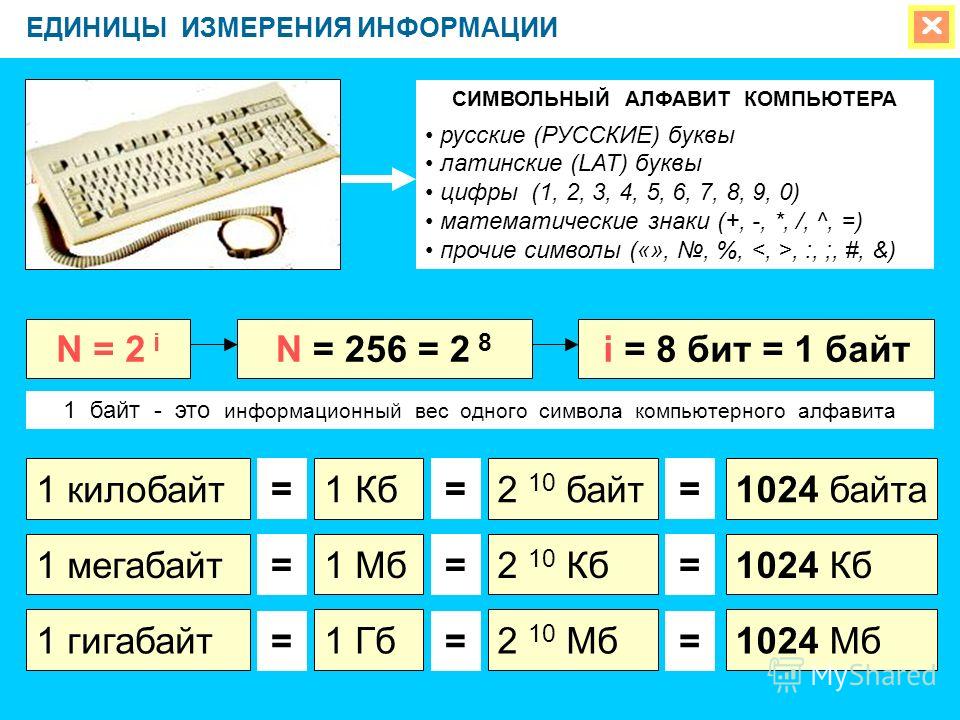 Каким количеством бит кодируется каждый символ этого сообщения?
Каким количеством бит кодируется каждый символ этого сообщения?
4 бита
8 бит
16 бит
32 бита
14) Текст рассказа имеет информационный объём 9 Кбайт. Текст занимает 6 страниц, на каждой странице одинаковое количество строк, в каждой строке 48 символов. Все символы представлены в кодировке КОИ-8, в которой каждый символ кодируется 8 битами. Определите, сколько строк помещается на каждой странице.
32 строки
48 строк
24 строки
12 строк
15)
Статья, набранная в текстовом редакторе, содержит 32 страницы, на каждой странице 32 строки, в каждой строке 25 символов. Определите информационный объём статьи в кодировке Windows-1251, в которой каждый символ кодируется 8 битами.
Определите информационный объём статьи в кодировке Windows-1251, в которой каждый символ кодируется 8 битами.
200 байт
25 Кбайт
400 байт
20 Кбайт
16) Главный редактор журнала отредактировал статью, и её объём уменьшился на 2 страницы. Каждая страница содержит 32 строки, в каждой строке 64 символа. Информационный объём статьи до редактирования был равен 2 Мбайт. Статья представлена в кодировке Unicode, в которой каждый символ кодируется 2 байтами. Определите информационный объём статьи в Кбайтах в этом варианте представления Unicode после редактирования.
1024 Кб
2048 Кб
1016 Кб
2040 Кб
17)
В одной из кодировок Unicode каждый символ кодируется 16 битами. Определите размер следующего предложения в данной кодировке. Я к вам пишу – чего же боле? Что я могу ещё сказать?
Определите размер следующего предложения в данной кодировке. Я к вам пишу – чего же боле? Что я могу ещё сказать?
416 байт
52 байт
832 бит
104 бит
18) Статья, набранная на компьютере, содержит 16 страниц, на каждой странице 40 строк, в каждой строке 40 символов. В одном из представлений Unicode каждый символ кодируется 16 битами. Определите информационный объём статьи в этом варианте представления Unicode.
30 Кбайт
40 Байт
50 Кбайт
60 Байт
19)
В одной из кодировок Unicode каждый символ кодируется 16 битами. Определите размер следующего предложения в данной кодировке: Не рой другому яму — сам в неё попадёшь
Определите размер следующего предложения в данной кодировке: Не рой другому яму — сам в неё попадёшь
37 байт
624 бита
74 байт
78 бит
§ 1.6. Измерение информации
§ 1.6. Измерение информации
Информатика. 7 класса. Босова Л.Л. Оглавление
Ключевые слова:
- бит
- информационный вес символа
- информационный объём сообщения
- единицы измерения информации
Одно и то же сообщение может нести много информации для одного человека и не нести её совсем для другого человека. При таком подходе количество информации определить однозначно затруднительно.
Алфавитный подход позволяет измерить информационный объём сообщения, представленного на некотором языке (естественном или формальном), независимо от его содержания.
Для количественного выражения любой величины необходима, прежде всего, единица измерения. Измерение осуществляется путём сопоставления измеряемой величины с единицей измерения. Сколько раз единица измерения «укладывается» в измеряемой величине, таков и результат измерения.
При алфавитном подходе считается, что каждый символ некоторого сообщения имеет определённый информационный вес — несёт фиксированное количество информации. Все символы одного алфавита имеют один и тот же вес, зависящий от мощности алфавита. Информационный вес символа двоичного алфавита принят за минимальную единицу измерения информации и называется 1 бит.
Обратите внимание, что название единицы измерения информации «бит» (bit) происходит от английского словосочетания binary digit — «двоичная цифра».
За минимальную единицу измерения информации принят 1 бит. Считается, что таков информационный вес символа двоичного алфавита.
Ранее мы выяснили, что алфавит любого естественного или формального языка можно заменить двоичным алфавитом. При этом мощность исходного алфавита N связана с разрядностью двоичного кода i, требуемой для кодирования всех символов исходного алфавита, соотношением: N = 2i.
Разрядность двоичного кода принято считать информационным весом символа алфавита. Информационный вес символа алфавита выражается в битах.
Информационный вес символа алфавита i и мощность алфавита N связаны между собой соотношением: N = 2i.
Задача 1. Алфавит племени Пульти содержит 8 символов. Каков информационный вес символа этого алфавита?
Решение. Составим краткую запись условия задачи.
Известно соотношение, связывающее величины i и N : N = 2i.
С учётом исходных данных: 8 = 2i. Отсюда: i = 3.
Полная запись решения в тетради может выглядеть так:
1. 6.3. Информационный объём сообщения
6.3. Информационный объём сообщенияИнформационный объём сообщения (количество информации в сообщении), представленного символами естественного или формального языка, складывается из информационных весов составляющих его символов.
Информационный объём сообщения I равен произведению количества символов в сообщении К на информационный вес символа алфавита i;I = К • i.
Задача 2. Сообщение, записанное буквами 32-символьного алфавита, содержит 140 символов. Какое количество информации оно несёт?
Задача 3. Информационное сообщение объёмом 720 битов состоит из 180 символов. Какова мощность алфавита, с помощью которого записано это сообщение?
1.6.4. Единицы измерения информацииВ наше время подготовка текстов в основном осуществляется с помощью компьютеров. Можно говорить о «компьютерном алфавите», включающем следующие символы: строчные и прописные русские и латинские буквы, цифры, знаки препинания, знаки арифметических операций, скобки и др. Такой алфавит содержит 256 символов. Поскольку 256 = 28, информационный вес каждого символа этого алфавита равен 8 битам. Величина, равная восьми битам, называется байтом. 1 байт — информационный вес символа алфавита мощностью 256.
Такой алфавит содержит 256 символов. Поскольку 256 = 28, информационный вес каждого символа этого алфавита равен 8 битам. Величина, равная восьми битам, называется байтом. 1 байт — информационный вес символа алфавита мощностью 256.
1 байт = 8 битов
Бит и байт — «мелкие» единицы измерения. На практике для измерения информационных объёмов используются более крупные единицы:
1 килобайт = 1 Кб = 1024 байта = 210 байтов
1 мегабайт = 1 Мб = 1024 Кб = 210 Кб = 220 байтов
1 гигабайт = 1 Гб = 1024 Мб = 210 Мб = 220 Кб = 230 байтов
1 терабайт = 1 Тб = 1024 Гб = 210 Гб = 220 Мб = 230 Кб = 240 байтов
Задача 4. Информационное сообщение объёмом 4 Кбайта состоит из 4096 символов. Каков информационный вес символа используемого алфавита? Сколько символов содержит алфавит, с помощью которого записано это сообщение?
Ответ: 8 битов, 256 символов.
Задача 5. В велокроссе участвуют 128 спортсменов. Специальное устройство регистрирует прохождение каждым из участников промежуточного финиша, записывая его номер цепочкой из нулей и единиц минимальной длины, одинаковой для каждого спортсмена. Каков будет информационный объём сообщения, записанного устройством после того, как промежуточный финиш пройдут 80 велосипедистов?
Решение. Номера 128 участников кодируются с помощью двоичного алфавита. Требуемая разрядность двоичного кода (длина цепочки) равна 7, так как 128 = 27. Иначе говоря, зафиксированное устройством сообщение о том, что промежуточный финиш прошёл один велосипедист, несёт 7 битов информации. Когда промежуточный финиш пройдут 80 спортсменов, устройство запишет 80 • 7 = 560 битов, или 70 байтов информации.
Ответ: 70 байтов.
Самое главное.
При алфавитном подходе считается, что каждый символ некоторого сообщения имеет опредёленный информационный вес — несёт фиксированное количество информации.
1 бит — минимальная единица измерения информации.
Информационный вес символа алфавита i и мощность алфавита N связаны между собой соотношением: N = 2i.
Информационный объём сообщения I равен произведению количества символов в сообщении К на информационный вес символа алфавита i: I = K•i.
1 байт = 8 битов.
Байт, килобайт, мегабайт, гигабайт, терабайт — единицы измерения информации. Каждая следующая единица больше предыдущей в 1024 (210) раза.
Вопросы и задания.
1.Ознакомтесь с материалами презентации к параграфу, содержащейся в электронном приложении к учебнику. Используйте эти материалы при подготовке ответов на вопросы и выполнении заданий.
2. В чём суть алфавитного подхода к измерению информации?
3. Что принято за минимальную единицу измерения информации?
4. Что нужно знать для определения информационного веса символа алфавита некоторого естественного или формального языка?
5. Определите информационный вес i символа алфавита мощностью N, заполняя таблицу
6. Как определить информационный объём сообщения, представленного символами некоторого естественного или формального языка?
Как определить информационный объём сообщения, представленного символами некоторого естественного или формального языка?
7. Определите количество информации в сообщении из Ксимволов алфавита мощностью N, заполняя таблицу
8. Племя Мульти пишет письма, пользуясь 16-символьным алфавитом. Племя Пульти пользуется 32-символьным алфавитом. Вожди племён обменялись письмами. Письмо племени Мульти содержит 120 символов, — а письмо племени Пульти — 96. Сравните информационные объёмы сообщений, содержащихся в письмах
9. Информационное сообщение объёмом 650 битов состоит из 130 символов. Каков информационный вес каждого символа этого сообщения?
10. Выразите количество информации в различных единицах, заполняя таблицу
11. Информационное сообщение объёмом 375 байтов состоит из 500 символов. Каков информационный вес каждого символа этого сообщения? Какова мощность алфавита, с помощью которого было записано это сообщение?
12. Для записи текста использовался 64-символьный алфавит. Какое количество информации в байтах содержат 3 страницы текста, если на каждой странице расположено 40 строк по 60 символов в строке?
Какое количество информации в байтах содержат 3 страницы текста, если на каждой странице расположено 40 строк по 60 символов в строке?
13. Сообщение занимает 6 страниц по 40 строк, в каждой строке записано по 60 символов. Информационный объём всего сообщения равен 9000 байтам. Каков информационный вес одного символа? Сколько символов в алфавите языка, на котором записано это сообщение?
14. Метеорологическая станция ведёт наблюдение за влажностью воздуха. Результатом одного измерения является целое число от 0 до 100 процентов, которое записывается цепочкой из нулей и единиц минимальной длины, одинаковой для каждого измерения. Станция сделала 8192 измерения. Определите информационный объём результатов наблюдений.
15. Племя Пульти пользуется 32-символьным алфавитом. Свод основных законов племени хранится на 512 глиняных табличках, на каждую из которых нанесено ровно 256 символов. Какое количество информации содержится на каждом носителе? Какое количество информации заключено во всём своде законов?
Оглавление
§ 1. 5. Двоичное кодирование
5. Двоичное кодирование
§ 1.6. Измерение информации
Тестовые задания для самоконтроля
критических ресурсов и первые 14 КБ — обзор
Эта страница была создана и последний раз редактировалась .
Введение
Многие эксперты по веб-производительности рекомендуют размещать все важные ресурсы в первых 14 КБ веб-страницы. Это основано на некотором понимании TCP, которое лежит в основе каждого HTTP-соединения — по крайней мере, на данный момент, пока не появятся HTTP/3 и QUIC. Но так ли это на самом деле? В моей книге «HTTP/2 в действии» я предположил, что эта статистика в 14 КБ больше не актуальна в современном мире, если вообще когда-либо была актуальна, и меня попросили расширить это — отсюда и этот пост. Но позвольте мне оговориться, сказав, что веб-производительность чрезвычайно важна, и есть много, много, много вариантов использования, показывающих это, поэтому я не возражаю против этого, и люди должны это оптимизировать. Только не зацикливайтесь на этом 14-килобайтном номере.
Только не зацикливайтесь на этом 14-килобайтном номере.
Основы TCP и откуда взялось это число 14 КБ
TCP — это протокол гарантированной доставки, для достижения которого используется ряд методов. Сначала он подтверждает все TCP-пакеты и повторно отправляет любые неподтвержденные пакеты. Кроме того, он ведет себя довольно хорошо в сети и начинает медленно и набирает полную мощность в процессе, известном как TCP slow start , осторожно нащупывая свой путь и проверяя, не перегружает ли он что-либо и не приводит к потере (неподтвержденных) пакетов. Сочетание этих двух вещей означает, что при запуске TCP он позволяет отправить 10 пакетов TCP, прежде чем они должны быть подтверждены. Когда эти пакеты подтверждены, это позволяет отправлять больше пакетов, удваивая их, чтобы разрешить отправку 20 пакетов в следующий раз, затем 40, затем 80… и т. д. по мере того, как он постепенно нарастает до полной емкости, которую может выдержать сеть. Магическое число 14 КБ связано с тем, что каждый TCP-пакет может иметь размер до 1500 байт, но 40 из этих байтов предназначены для использования TCP (заголовки TCP и т. п.), оставляя 1460 байтов для фактических данных. 10 из этих пакетов означают, что вы можете доставить 14 600 байт или около 14 КБ (фактически 14,25 КБ).
п.), оставляя 1460 байтов для фактических данных. 10 из этих пакетов означают, что вы можете доставить 14 600 байт или около 14 КБ (фактически 14,25 КБ).
Теперь сети работают невероятно быстро — на самом деле почти со скоростью света — и обычно требуется всего 10 или 100 миллисекунд, чтобы эти ответы перемещались туда и обратно между сервером и клиентом. Однако одна из немногих вещей в известной вселенной быстрее скорости света — это нетерпение пользователей. Таким образом, отсрочка отправки дополнительных данных, пока вы ждете этих подтверждений, означает, что вы ждете по крайней мере один обмен данными между клиентом и сервером (известный как цикл туда и обратно 9).0016 ), и это создает нежелательное узкое место в производительности. Было бы намного лучше, если бы первая партия отправки могла содержать все важные данные для запуска браузера на пути к рисованию (или рендерингу ) веб-страницы.
Еще один момент, на который стоит обратить внимание, это то, что HTML на самом деле читается большинством браузеров как поток байтов, поэтому вам не нужно загружать весь HTML до того, как браузер начнет его обрабатывать. По сути, браузеры тоже довольно нетерпеливы — из-за этих нетерпеливых пользователей — и поэтому начнут смотреть на HTML, как только он начнет появляться. Он может увидеть ссылки на CSS, JavaScript и другие ресурсы и начать извлекать их, чтобы отобразить страницу как можно быстрее. Таким образом, даже если вы не можете отправить всю страницу в первые 14 КБ (хотя, пожалуйста, сделайте это, если можете!), наличие такого количества важных данных в этих первых 14 КБ позволит браузеру начать работу с этими данными раньше.
По сути, браузеры тоже довольно нетерпеливы — из-за этих нетерпеливых пользователей — и поэтому начнут смотреть на HTML, как только он начнет появляться. Он может увидеть ссылки на CSS, JavaScript и другие ресурсы и начать извлекать их, чтобы отобразить страницу как можно быстрее. Таким образом, даже если вы не можете отправить всю страницу в первые 14 КБ (хотя, пожалуйста, сделайте это, если можете!), наличие такого количества важных данных в этих первых 14 КБ позволит браузеру начать работу с этими данными раньше.
Хотя 14 КБ может показаться не таким уж большим в наши дни многомегабайтных страниц, помните, что вы не пытаетесь уместить всю страницу в этот предел в 14 КБ (хотя опять же, если можете!), а только пытаетесь оптимизировать то, что браузер видит в этом первом фрагменте данных. Предоставление всех ваших критических ресурсов в первых 14 КБ, таким образом, дает вам наилучшие шансы максимизировать первое чтение браузера и должно привести к более быстрой странице, поэтому эксперты по веб-производительности дают этот совет. В идеальном мире этого будет даже достаточно, чтобы начать рендеринг, если вы встроите критический CSS — что мне на самом деле не нравится, кстати! — но даже если вы не можете получить его за один круговой рендеринг, также поможет браузер начать загрузку всех необходимых ресурсов как можно быстрее.
В идеальном мире этого будет даже достаточно, чтобы начать рендеринг, если вы встроите критический CSS — что мне на самом деле не нравится, кстати! — но даже если вы не можете получить его за один круговой рендеринг, также поможет браузер начать загрузку всех необходимых ресурсов как можно быстрее.
14 КБ и современный Интернет
Однако этот совет может быть не совсем точным, и лично я думаю, что зацикливаться на этом волшебном числе 14 КБ не так уж и полезно. Он делает несколько предположений, которые на самом деле нереалистичны в сегодняшней сети, если они когда-либо были таковыми.
Во-первых, предполагается, что все эти 14 КБ будут использоваться для доставки HTML. Даже в старом мире HTTP с открытым текстом этого не было с кодами ответов HTTP ( 200 OK ) и заголовками ответов HTTP, занимающими часть этого. В частности, заголовки ответов HTTP могут быть огромными! Например, размер заголовка политики безопасности контента Twitter составляет примерно 5 КБ. Да, HTTP/2 позволяет сжимать заголовки ответов HTTP, но в основном это работает, сохраняя заголовки из предыдущих запросов и ссылаясь на них в последующих запросах. Это означает, что первый запрос — когда нас больше всего беспокоит это ограничение в 14 КБ — в значительной степени использует полноразмерные заголовки — хотя это не на 100% точно, поскольку HTTP/2 все еще может использовать исходную статическую таблицу для общих заголовков и использовать кодировку Хаффмана, а чем ASCII, для немного меньших заголовков, но это лишь частичная оптимизация, а большее преимущество заключается в повторном использовании для второго и последующих запросов. Поскольку я только что представил HTTP/2, возникает вторая проблема — HTTPS и HTTP/2. Оба они требуют обмена некоторыми дополнительными сообщениями для установления соединения.
Да, HTTP/2 позволяет сжимать заголовки ответов HTTP, но в основном это работает, сохраняя заголовки из предыдущих запросов и ссылаясь на них в последующих запросах. Это означает, что первый запрос — когда нас больше всего беспокоит это ограничение в 14 КБ — в значительной степени использует полноразмерные заголовки — хотя это не на 100% точно, поскольку HTTP/2 все еще может использовать исходную статическую таблицу для общих заголовков и использовать кодировку Хаффмана, а чем ASCII, для немного меньших заголовков, но это лишь частичная оптимизация, а большее преимущество заключается в повторном использовании для второго и последующих запросов. Поскольку я только что представил HTTP/2, возникает вторая проблема — HTTPS и HTTP/2. Оба они требуют обмена некоторыми дополнительными сообщениями для установления соединения.
HTTPS требует двух циклов для установки соединения TLS, при условии, что наиболее часто используется TLSv1.2 и нет возобновления сеанса, как показано на следующей диаграмме рукопожатия:
Так вот как минимум 2 из 10 ваших TCP пакетов на отправку израсходованы как минимум. TLSv1.3 допускает 1 передачу туда и обратно (1-RTT) или даже 0 передач туда и обратно (0-RTT) в определенных сценариях, что является одним из его больших преимуществ. Однако я не думаю, что это слишком сильно меняет аргумент, который я собираюсь привести, потому что, кроме того, сертификаты TLS могут быть довольно большими, что легко требует отправки нескольких пакетов TCP. Таким образом, использование 2 TCP-пакетов, вероятно, является вашим 9-м.0039 лучший случай даже для TLSv1.3 и уж точно для TLSv1.2.
TLSv1.3 допускает 1 передачу туда и обратно (1-RTT) или даже 0 передач туда и обратно (0-RTT) в определенных сценариях, что является одним из его больших преимуществ. Однако я не думаю, что это слишком сильно меняет аргумент, который я собираюсь привести, потому что, кроме того, сертификаты TLS могут быть довольно большими, что легко требует отправки нескольких пакетов TCP. Таким образом, использование 2 TCP-пакетов, вероятно, является вашим 9-м.0039 лучший случай даже для TLSv1.3 и уж точно для TLSv1.2.
Тогда давайте предположим, что вы используете HTTP/2, как сейчас используют многие популярные сайты, особенно те, которые заботятся о производительности. HTTP/2 доступен только через HTTPS (по крайней мере, для браузеров) и требует обмена еще несколькими сообщениями для установки соединения HTTP/2. Для начала клиент должен сначала отправить предисловие к соединению HTTP/2, затем каждая сторона ДОЛЖНА отправить кадр SETTINGS, и часто в начале соединения также отправляется один или несколько кадров WINDOWS_UPDATE. Только после этого клиент может отправить HTTP-запрос. Это правда, что эти кадры HTTP/2 не обязательно должны быть отдельными TCP-пакетами, а также не нуждаются в подтверждении до того, как клиентские запросы могут быть сделаны, но они действительно съедают этот первоначальный начальный предел в 10 TCP-пакетов. Кроме того, хотя это вряд ли стоит упоминать, поскольку он такой маленький, но каждому кадру HTTP/2 также предшествует заголовок, состоящий как минимум из 9 символов.байтов, в зависимости от точного типа фрейма, который дальше на восток от этого предела в 14,25 КБ — если мы собираемся считать накладные расходы пакетов TCP, то кажется справедливым сделать то же самое для накладных расходов пакетов HTTP/2!
Только после этого клиент может отправить HTTP-запрос. Это правда, что эти кадры HTTP/2 не обязательно должны быть отдельными TCP-пакетами, а также не нуждаются в подтверждении до того, как клиентские запросы могут быть сделаны, но они действительно съедают этот первоначальный начальный предел в 10 TCP-пакетов. Кроме того, хотя это вряд ли стоит упоминать, поскольку он такой маленький, но каждому кадру HTTP/2 также предшествует заголовок, состоящий как минимум из 9 символов.байтов, в зависимости от точного типа фрейма, который дальше на восток от этого предела в 14,25 КБ — если мы собираемся считать накладные расходы пакетов TCP, то кажется справедливым сделать то же самое для накладных расходов пакетов HTTP/2!
Таким образом, если эта статистика 10 пакетов / 14 КБ была точной, то мы сократили бы как минимум половину этого (2 пакета для рукопожатия TLS, 2 для ответов на установку соединения HTTP/2 и 1 для ответа HTTP-заголовка, оставив 5 пакеты), что звучит намного хуже! Однако, с положительной стороны, некоторые из этих сообщений взад и вперед приведут к TCP ACK, что означает, что у нас будет больше , чем 14 КБ, когда мы приходим к отправке обратно HTML не меньше . Например, TLS требует, чтобы клиенты отвечали во время рукопожатия, что, как мы вскоре увидим, означает, что они также могут одновременно подтверждать некоторые из этих ранее отправленных TCP-пакетов, увеличивая размер окна перегрузки, поэтому мы уже вышли за пределы что предел 10 пакетов.
Также предполагается, что можно отправить только 10 TCP-пакетов. Хотя это верно для большинства современных операционных систем, это относительно новое изменение, и ранее в качестве этого ограничения использовались 1, 2, а затем 4 пакета. Можно с уверенностью предположить, если вы не работаете на устаревшем оборудовании (и давайте предположим, что те, кто достаточно беспокоится о производительности, чтобы смотреть на это ограничение в 14 КБ, не так), то это как минимум 14 КБ, однако некоторые CDN даже начали увеличиваться. чем 10. До сих пор я не видел никаких предложений увеличить это значение для серверов в целом, но опять же те, кто заинтересован в производительности, вполне могут использовать CDN.
Кроме того, как упоминалось ранее, это число в 14 КБ всегда основывалось на несколько ошибочном предположении, что использование TCP является таким точным и чистым протоколом. Можно сказать, что стеки TCP могут отправлять до 10 пакетов без подтверждения, и что каждое подтверждение всех пакетов в пути удваивает размер окна перегрузки, что означает, что после этих первоначальных 10 пакетов можно отправить 20 пакетов, затем 40 пакетов, 80 пакетов. пакеты… и т.д. Однако жизнь редко бывает такой клинической. Реальность такова, что TCP будет постоянно подтверждать пакеты в зависимости от стека TCP и задействованных таймингов. Ограничение на 10 пакетов составляет всего максимум неподтвержденный предел, но довольно часто подтверждение может быть отправлено после, скажем, 5 пакетов. Или даже после 1. Это особенно верно, когда клиент все равно должен отправлять данные (например, как часть рукопожатия TLS или как часть настройки соединения HTTP/2), так что реальность такова, что часто (всегда?) окно перегрузки будет больше 10 КБ к тому времени, когда вы все равно отправите HTML.
Наконец, следует также помнить, что HTML должен доставляться сжатым (сжатым с помощью gzip или с использованием нового сжатия brotli), поэтому 10 КБ легко могут быть 50 КБ, если это принять во внимание, поскольку текст (HTML, CSS и JavaScript) сжимается очень хорошо.
Пример из реальной жизни
Поскольку одним из моих замечаний выше является то, что 14 КБ основаны на теории, а не на фактическом использовании, давайте рассмотрим пример из реальной жизни. Далее следует только один пример, а не окончательное исследование или исчерпывающий анализ X лучших сайтов, но, по крайней мере, он покажет, говорю ли я полную чепуху или есть что-то в этих бессвязных словах. Выводы можно легко повторить, и если кто-то захочет, он может повторить это в большем масштабе. Во всяком случае, для этого примера я запустил Chrome с протоколированием ключей SSL, чтобы Wireshark мог перехватывать все запросы. Как это работает, для тех читателей, которые не знакомы с этим, выходит за рамки этого сообщения в блоге, но есть и другие, которые покажут вам путь. Эта настройка в основном означает, что Chrome работает в обычном режиме, но позволяет Wireshark перехватывать весь трафик туда и обратно, даже зашифрованный трафик HTTPS, поэтому мы можем точно видеть, что происходит на уровне пакетов TCP.
Эта настройка в основном означает, что Chrome работает в обычном режиме, но позволяет Wireshark перехватывать весь трафик туда и обратно, даже зашифрованный трафик HTTPS, поэтому мы можем точно видеть, что происходит на уровне пакетов TCP.
Затем я подключаюсь к известному веб-сайту (я выбрал https://www.amazon.com) и после проверки IP-адреса, к которому я подключился, в инструментах разработчика Chrome, я отфильтровал захват Wireshark только для этого трафика. – как показано на скриншоте ниже:
Для тех, кто не привык к Wireshark, это может немного сбить с толку, но в основном каждая строка представляет собой сообщение, отправляемое по сети. Там, где это возможно, Wireshark будет классифицировать тип сообщения на самом высоком уровне протокола (например, TCP, TLS или HTTP/2) для этого сообщения. Он также будет возвращаться к TCP для фрагментов сообщений (например, для сообщений TLS, которые охватывают несколько сообщений TCP, поэтому не могут быть распознаны как сообщение TLS до окончательного пакета TCP).
На приведенном выше снимке экрана вы можете видеть все сообщения, возвращающиеся от Amazon, и в первую очередь мы видим сообщение 1241, которое является серверной стороной TCP-рукопожатия (SYN, ACK), затем TCP ACK в сообщении 1250, затем мы видим Сообщение TLSv1.2 Server Hello (1252), за которым следуют 3 сообщения (1253, 1255 и 1257), необходимые для отправки следующей части рукопожатия TLS с сертификатом и данными обмена ключами (обратите внимание, что только последнее из них помечено как TLSv1.2, так как первые два являются просто фрагментами, поэтому помечены как TCP). Также в первых двух из них вы можете увидеть максимальный размер 1500 байт, который я обсуждал ранее. Пакеты TCP на самом деле имеют только этот максимальный размер, когда есть поток данных для отправки, подобный этому. После этого есть еще один случайный TCP ACK (1284), прежде чем мы закончим рукопожатие TCP (1285). Далее мы переходим к сообщениям настройки HTTP/2, описанным выше. К счастью, они маленькие и могут поместиться в один TCP-пакет. После этого у нас есть еще пара TCP ACK, прежде чем мы доберемся до первого настоящего HTTP-сообщения (1316), куда мы отправляем заголовки ответа (включая 9Код состояния 0033 200 показан на скриншоте). После этого у нас есть еще несколько ACK, прежде чем мы начнем отправлять HTML, который занимает 5 пакетов (1318, 1319, 1321, 1322 и 1324) для первого кадра DATA HTTP/2 (обратите внимание, я не показал все кадры DATA в этом скриншот для краткости). Теперь размер окна перегрузки не является чем-то, что фактически передается, поэтому мы можем только догадываться, каков размер к этому моменту, но я думаю, ясно показать, что обратно отправляется гораздо больше, чем просто тело HTML, поэтому предположение, что все эти 10 пакетов только для HTML, конечно, неправда.
После этого у нас есть еще пара TCP ACK, прежде чем мы доберемся до первого настоящего HTTP-сообщения (1316), куда мы отправляем заголовки ответа (включая 9Код состояния 0033 200 показан на скриншоте). После этого у нас есть еще несколько ACK, прежде чем мы начнем отправлять HTML, который занимает 5 пакетов (1318, 1319, 1321, 1322 и 1324) для первого кадра DATA HTTP/2 (обратите внимание, я не показал все кадры DATA в этом скриншот для краткости). Теперь размер окна перегрузки не является чем-то, что фактически передается, поэтому мы можем только догадываться, каков размер к этому моменту, но я думаю, ясно показать, что обратно отправляется гораздо больше, чем просто тело HTML, поэтому предположение, что все эти 10 пакетов только для HTML, конечно, неправда.
Теперь давайте посмотрим на клиентскую сторону, изменив фильтр вверху, чтобы посмотреть на ip.dst вместо этого:
Здесь мы видим аналогичную историю с настройкой TCP, сообщениями TLS, сообщениями HTTP/2, и все это еще до того, как мы запросим домашнюю страницу. Каждый из этих TCP-пакетов по 66 байтов — это просто TCP ACK и ничего более, поэтому это показывает, что TCP ACK происходят все время, даже если не отправляется никакой другой трафик. Однако, когда отправляется другой трафик (например, сообщения TLS или сообщения HTTP/2), существует по-прежнему TCP ACK, также происходящих как часть этих сообщений. Всего 14 сообщений, все с TCP ACK, отправляются на сервер после начального рукопожатия TCP еще до того, как будет отправлен первоначальный запрос
Каждый из этих TCP-пакетов по 66 байтов — это просто TCP ACK и ничего более, поэтому это показывает, что TCP ACK происходят все время, даже если не отправляется никакой другой трафик. Однако, когда отправляется другой трафик (например, сообщения TLS или сообщения HTTP/2), существует по-прежнему TCP ACK, также происходящих как часть этих сообщений. Всего 14 сообщений, все с TCP ACK, отправляются на сервер после начального рукопожатия TCP еще до того, как будет отправлен первоначальный запрос GET (и этот запрос также включает ACK, поэтому мы можем получить до 15 пакетов). И, вероятно, еще несколько ACK будут отправлены до того, как HTML начнет доставляться, и даже больше во время его доставки. На самом деле давайте посмотрим на обе стороны сразу (что поначалу может сбивать с толку, поэтому я сначала показал каждую сторону):
Здесь мы видим, что больше ACK было отправлено от клиента к серверу в пакетах 1286, 1289, 1317, 1320, 1323 до того, как сервер вернул первый кадр DATA, что означает, что мы получили ACK как минимум 20 пакетов, когда HTML начинает течь, так что мы где-то между 28 КБ и 57 КБ, которые могут быть отправлены без подтверждения. Кроме того, как я уже говорил выше, в потоке данных HTML принимается больше ACK, что можно увидеть в сообщении 1325 и других сообщениях за пределами экрана. Трудно сказать, блокировался ли HTML когда-либо в ожидании подтверждения TCP, но я подозреваю, что нет. Домашняя страница Amazon не маленькая (113 КБ в сжатом виде или 502 КБ в несжатом виде), но из-за экспоненциального роста медленного запуска TCP нам нужно всего 3 или 4 подтверждения, чтобы потенциально добраться до точки, где это может быть отправлено. за один раз, как мы уже показали, соединения HTTPS и HTTP/2 будут иметь несколько циклов.
Кроме того, как я уже говорил выше, в потоке данных HTML принимается больше ACK, что можно увидеть в сообщении 1325 и других сообщениях за пределами экрана. Трудно сказать, блокировался ли HTML когда-либо в ожидании подтверждения TCP, но я подозреваю, что нет. Домашняя страница Amazon не маленькая (113 КБ в сжатом виде или 502 КБ в несжатом виде), но из-за экспоненциального роста медленного запуска TCP нам нужно всего 3 или 4 подтверждения, чтобы потенциально добраться до точки, где это может быть отправлено. за один раз, как мы уже показали, соединения HTTPS и HTTP/2 будут иметь несколько циклов.
Глядя только на сообщения HTTP/2, мы видим устойчивый поток кадров DATA без заметной задержки между ними, что было бы показательным или ожиданием подтверждений TCP, что, кажется, подтверждает мои подозрения об отсутствии задержки:
Я буду честен здесь, и с временем прохождения туда и обратно 20 мс (которое я измерил с помощью ping ), в любом случае было бы трудно увидеть такую задержку. Худшее соединение может показать большее влияние. Также следует отметить, что использование дросселирования сети Chrome Dev Tools здесь не поможет, поскольку это искусственное дросселирование внутри Chrome, а не что-либо на сетевом уровне. Я повторил тест с веб-сайтом туда и обратно за 300 мс и увидел то же самое, но это все еще очень анекдотично, поскольку я тестирую здесь отдельные сайты, а не провожу обширные полевые исследования.
Худшее соединение может показать большее влияние. Также следует отметить, что использование дросселирования сети Chrome Dev Tools здесь не поможет, поскольку это искусственное дросселирование внутри Chrome, а не что-либо на сетевом уровне. Я повторил тест с веб-сайтом туда и обратно за 300 мс и увидел то же самое, но это все еще очень анекдотично, поскольку я тестирую здесь отдельные сайты, а не провожу обширные полевые исследования.
Тем не менее, суть остается в том, что существует множество TCP-сообщений туда и обратно, так что число 10 TCP / 14 КБ было показано как теоретическое, а не как то, что вы могли бы увидеть в реальном мире, особенно при HTTPS-соединении (и даже больше). так при соединении HTTP/2 через HTTPS).
Резюме
Надеюсь, этот пост объяснил, почему я думаю, что число 14 КБ не является абсолютным числом или что-то, чего веб-разработчики должны придерживаться слишком жестко («О нет, я дошел до 15 КБ, должен сбрить еще 1 КБ или мы не могу запустить!»). Я уверен, что многие энтузиасты веб-производительности, продвигавшие это число, не хотели, чтобы люди восприняли его так буквально, но проблема с таким жестким числом, особенно если оно подкреплено небольшим количеством научных данных, заключается в том, что люди будут воспринимать это как таковое, когда они не должны.
Я уверен, что многие энтузиасты веб-производительности, продвигавшие это число, не хотели, чтобы люди восприняли его так буквально, но проблема с таким жестким числом, особенно если оно подкреплено небольшим количеством научных данных, заключается в том, что люди будут воспринимать это как таковое, когда они не должны.
Этот пост также не означает, что размер страницы не важен — он чрезвычайно важен, и я большой поклонник оптимизации веб-производительности! Однако я предостерегаю от абсолютизма. Реальный мир намного сложнее этого. Общий совет остается в силе: размещайте важные ресурсы в верхней части страницы, чтобы браузер мог их увидеть как можно скорее и начать с ними работать, и в идеале сделать вашу страницу как можно меньше, чтобы обеспечить быструю загрузку. Но не стоит слишком париться из-за этого волшебного числа в 14 КБ.
Вы согласны или не согласны? У вас есть еще данные на этот счет, чтобы подтвердить или опровергнуть то, о чем я говорил выше? Дайте мне знать ниже ваши мысли ниже. И если этот пост вас заинтересует, ознакомьтесь с моей книгой — HTTP/2 в действии. Код скидки
И если этот пост вас заинтересует, ознакомьтесь с моей книгой — HTTP/2 в действии. Код скидки 39pollard даже даст вам скидку 39% при покупке напрямую у Мэннинга.
Хотите узнать больше?
Дополнительные ресурсы по этой теме
- HTTP/2 в действии — моя книга, в которой подробно рассматриваются HTTP и TCP.
- High Performance Browser Networking от Ильи Григорика, который предлагает массу фактов и информации о сетях низкого уровня.
- Потрясающий доклад Патрика Минана о том, как браузеры загружают и отображают ресурсы, особенно в мире HTTP/2.
Эта страница была создана и последний раз редактировалась .
ТвитнутьНасколько полезной была эта страница?
— Спасибо за ваш отзыв!
14 июня 2022 г. — KB5014738 (ежемесячный накопительный пакет)
Резюме Узнайте больше об этом накопительном обновлении для системы безопасности, в том числе об улучшениях, известных проблемах и о том, как получить это обновление.
ВАЖНО 19 мая 2022 г. мы выпустили внеплановое обновление (OOB) для устранения проблемы, которая могла привести к сбоям проверки подлинности машинного сертификата на контроллерах домена. Если вы не установили 19 мая, 2022 или более поздних версий, то установка этого обновления от 14 июня 2022 г. также решит эту проблему. Дополнительные сведения см. в разделе Перед установкой этого обновления этой статьи.
ВАЖНО Основная поддержка Windows 8.1 и Windows Server 2012 R2 закончилась, и теперь они находятся в расширенной поддержке. Начиная с июля 2020 г. для этой операционной системы больше не будут выпускаться необязательные выпуски, не связанные с безопасностью (известные как выпуски «C»). Операционные системы с расширенной поддержкой имеют только накопительные ежемесячные обновления безопасности (известные как выпуск «B» или обновление во вторник).
Сведения о различных типах обновлений Windows, таких как критические обновления, обновления безопасности, драйверы, пакеты обновлений и т. д., см. в следующей статье. Чтобы просмотреть другие заметки и сообщения, посетите домашнюю страницу журнала обновлений Windows 8.1 и Windows Server 2012 R2.
д., см. в следующей статье. Чтобы просмотреть другие заметки и сообщения, посетите домашнюю страницу журнала обновлений Windows 8.1 и Windows Server 2012 R2.
Это накопительное обновление для системы безопасности включает улучшения, являющиеся частью обновления KB5014011 (выпущенного 10 мая 2022 г.), а также новые улучшения для следующей проблемы:
Печать на порт NUL из приложения процесса с низким уровнем целостности (LowIL) может привести к сбоям печати.
Устранена уязвимость повышения привилегий (EOP) в CVE-2022-30154 для службы агента теневого копирования Microsoft File Server. Чтобы обеспечить защиту и работоспособность, необходимо установить обновление Windows от 14 июня 2022 г.
 или более поздней версии как на сервере приложений, так и на файловом сервере. Сервер приложений запускает приложение, поддерживающее службу теневого копирования томов (VSS), которое хранит данные в удаленных общих ресурсах Server Message Block 3.0 (или выше) на файловом сервере. На файловом сервере размещаются файловые ресурсы. Если вы не установите обновление на обе роли машины, операции резервного копирования, выполняемые приложениями, которые ранее работали, могут завершиться ошибкой. Для таких сценариев отказа служба агента теневого копирования Microsoft File Server регистрирует событие FileShareShadowCopyAgent 1013 на файловом сервере. Дополнительные сведения см. в статье KB5015527.
или более поздней версии как на сервере приложений, так и на файловом сервере. Сервер приложений запускает приложение, поддерживающее службу теневого копирования томов (VSS), которое хранит данные в удаленных общих ресурсах Server Message Block 3.0 (или выше) на файловом сервере. На файловом сервере размещаются файловые ресурсы. Если вы не установите обновление на обе роли машины, операции резервного копирования, выполняемые приложениями, которые ранее работали, могут завершиться ошибкой. Для таких сценариев отказа служба агента теневого копирования Microsoft File Server регистрирует событие FileShareShadowCopyAgent 1013 на файловом сервере. Дополнительные сведения см. в статье KB5015527.
 или более поздней версии как на сервере приложений, так и на файловом сервере. Сервер приложений запускает приложение, поддерживающее службу теневого копирования томов (VSS), которое хранит данные в удаленных общих ресурсах Server Message Block 3.0 (или выше) на файловом сервере. На файловом сервере размещаются файловые ресурсы. Если вы не установите обновление на обе роли машины, операции резервного копирования, выполняемые приложениями, которые ранее работали, могут завершиться ошибкой. Для таких сценариев отказа служба агента теневого копирования Microsoft File Server регистрирует событие FileShareShadowCopyAgent 1013 на файловом сервере. Дополнительные сведения см. в статье KB5015527.
или более поздней версии как на сервере приложений, так и на файловом сервере. Сервер приложений запускает приложение, поддерживающее службу теневого копирования томов (VSS), которое хранит данные в удаленных общих ресурсах Server Message Block 3.0 (или выше) на файловом сервере. На файловом сервере размещаются файловые ресурсы. Если вы не установите обновление на обе роли машины, операции резервного копирования, выполняемые приложениями, которые ранее работали, могут завершиться ошибкой. Для таких сценариев отказа служба агента теневого копирования Microsoft File Server регистрирует событие FileShareShadowCopyAgent 1013 на файловом сервере. Дополнительные сведения см. в статье KB5015527.Дополнительную информацию об устраненных уязвимостях системы безопасности см. на веб-сайте Руководства по обновлениям безопасности и в обновлениях безопасности за июнь 2022 г.
Известные проблемы в этом обновленииСимптом | Следующий шаг |
Некоторые операции, такие как переименование , выполняемые с файлами или папками в общем томе кластера (CSV), могут завершаться с ошибкой «STATUS_BAD_IMPERSONATION_LEVEL (0xC00000A5)». | Выполните одно из следующих действий: Мы работаем над решением и представим обновление в следующем выпуске. |
После установки этого обновления устройства Windows могут не использовать функцию точки доступа Wi-Fi. При попытке использовать функцию точки доступа хост-устройство может потерять соединение с Интернетом после подключения клиентского устройства. | Эта проблема устранена в KB5015874. |
После установки этого обновления серверы Windows, использующие службу маршрутизации и удаленного доступа (RRAS), могут быть не в состоянии правильно направлять интернет-трафик. | Эта проблема устранена в KB5015874. |
 Это происходит, когда вы выполняете операцию на узле владельца CSV из процесса, у которого нет прав администратора.
Это происходит, когда вы выполняете операцию на узле владельца CSV из процесса, у которого нет прав администратора. Устройства, которые подключаются к серверу, могут не подключаться к Интернету, а серверы могут потерять подключение к Интернету после подключения клиентского устройства.
Устройства, которые подключаются к серверу, могут не подключаться к Интернету, а серверы могут потерять подключение к Интернету после подключения клиентского устройства.Перед установкой этого обновления
Для проверки подлинности сертификата компьютера выполните одно из следующих действий:
|
Мы настоятельно рекомендуем установить последнее обновление стека обслуживания (SSU) для вашей операционной системы, прежде чем устанавливать последний накопительный пакет. Если вы используете Центр обновления Windows, вам автоматически будет предложена последняя версия SSU (KB5014025). Чтобы получить автономный пакет последней версии SSU, найдите его в каталоге Центра обновления Майкрософт. |
 Затем установите это обновление на все компьютеры с ролью DC.
Затем установите это обновление на все компьютеры с ролью DC. SSU повышают надежность процесса обновления, устраняя потенциальные проблемы при установке накопительного пакета и применении исправлений безопасности Майкрософт. Общие сведения о SSU см. в разделах Обновления стека обслуживания и Обновления стека обслуживания (SSU): часто задаваемые вопросы.
SSU повышают надежность процесса обновления, устраняя потенциальные проблемы при установке накопительного пакета и применении исправлений безопасности Майкрософт. Общие сведения о SSU см. в разделах Обновления стека обслуживания и Обновления стека обслуживания (SSU): часто задаваемые вопросы.Установить это обновление
 Это обновление будет загружено и установлено автоматически из Центра обновления Windows.
Это обновление будет загружено и установлено автоматически из Центра обновления Windows.
Leave A Comment