
Урок информатики в 8-м классе по теме «Количество информации»
Цель урока:
- Иметь представление об алфавитном подходе к определению количества информации;
- Знать формулу для определения количества информационных сообщений,количества информации в сообщений;
- Уметь решать задачи на определение количества информационных сообщений и количества информации, которое несет полученное сообщение.
Ход урока
1. Актуализация знаний:
— Ребята давайте понаблюдаем за тем , что мы
видим за окном. Что вы можете сказать о природе? (Наступила
зима.)
— Но почему вы решили, что наступила зима? (Холодно
, идет снег.)
— Но ведь нигде не написано, что это признаки зимы.
(Но мы знаем, что все это означает: наступила
зима.)
Поэтому и получается, что , то знание, которое мы
извлекаем из окружающей действительности и есть  (слайд 1)
(слайд 1)
Разминка.
Заполнить таблицу и стрелочками показать соответствия.
| Носители информации | Их использование | |
| Дискета | Написать письмо | |
| Бумага | Записать компьютерную игру | |
| Сделать фотоизображение | ||
| Фотопленка | Записать исполнение песни | |
| Видеокассета | Записать ноты песни |
— Можно ли измерить количество информации и как это сделать? (Да)
Оказывается, информацию также можно измерять и
находить ее количество.
Существуют два подхода к измерению информации. С одним из них мы сегодня познакомимся. (Смотри приложение слайд 2)
2. Изучение нового материала.
Каким образом можно найти количество информации?
Рассмотрим пример.
У нас есть небольшой текст, написанный на русском языке. Он состоит из букв русского алфавита, цифр, знаков препинания. Для простоты будем считать, что символы в тексте присутствуют с одинаковой вероятностью.
Множество используемых в тексте символов называется алфавитом.
В информатике под алфавитом понимают не только буквы, но и цифры, и знаки препинания, и другие специальные знаки.
У алфавита есть размер (полное количество символов), который называется мощностью алфавита.

Обозначим мощность алфавита через N.
Найдем зависимость между информационным весом
символа (i) и мощностью алфавита (N). Самый
наименьший алфавит содержит 2 символа, которые
обозначаются “0” и “1”. Информационный вес
символа двоичного алфавита принят за единицу
информации и называется 1 бит. (Cмотри
приложение
| N | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 256 |
| i | 1бит | 2бит | 3бит | 4бит | 5бит | 6бит | 7бит | 8бит |
N= 2i
В компьютере также используется свой алфавит,
который можно назвать компьютерным. Количество
символов, которое в него входит, равно 256
символов. Это мощность компьютерного алфавита.
Количество
символов, которое в него входит, равно 256
символов. Это мощность компьютерного алфавита.
Также мы выяснили, что закодировать 256 разных символов можно показать с помощью 8 битов.
8 бит является настолько характерной величиной, что ей присвоили свое название – байт.
1байт = 8 битам
Используя этот факт: можно быстро подсчитать количество информации, содержащееся в компьютерном тексте, т.е.в тексте набранном с помощью компьютера, учитывая, что большинство статей, книг, публикаций и т.д. написаны с помощью текстовых редакторов, то таким способом можно найти информационный объем любого сообщения, созданного подобным образом.
Правило для измерения информации с точки зрения алфавитного подхода посмотрим на слайде. (Cмотри приложение слайд 4)
Пример:
Найти информационный объем страницы компьютерного текста.
Решение:
Используем правило.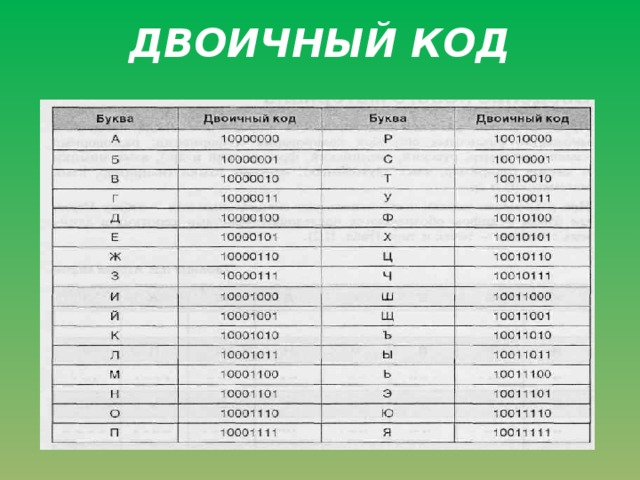
1. Найдем мощность: N=256
2. Найдем информационный объем одного символа :
3. Найдем количество символов на странице. Примерно.
(Найти количество символов в строке и умножить на количество строк)
Пояснение:
Пусть дети выберут произвольную строку и подсчитают количество символов в ней, учитывая все знаки препинания и пробелы.
40 символов * 50 строк = 2000символов.
4. Найдем информационный объем всей страницы: 2000 * 1 = 2000 байтам
Согласитесь, что байт – маленькая единица
измерения информации. Для измерения больших
объемов информации используют следующие единицы
3. Закрепление изученного материала.
На доске:
Заполнить пропуски числами и проверить правильность.
1 Кбайт = ___ байт = ______бит,
2 Кбайт = _____ байт =______бит,
24576 бит =_____байт =_____Кбайт,
512 Кбайт = ___ байт =_____бит.
Предлагается ученикам задачи:
1) Сообщение записано с помощью алфавита, содержащего 8 символов. Какое количество информации несет одна буква этого алфавита?
Решение: N=8 , то i= 3 битам
2) Сообщение , записанное буквами из 128-символьного алфавита, содержит 30 символов. Какой объем информации оно несет?
Решение:
1. N= 128 , K=30
2. N= 2i i= 7 битам (объем одного символа)
3. I = 30*7 = 210бит (объем всего сообщения)
4. Творческая работа.
Наберите на компьютере текст, информационный объем которого равен 240 байт.
5. Итоги урока.
— Что нового сегодня мы узнали на уроке?
— Как определяется количество информации с
алфавитной точки зрения?
— Как найти мощность алфавита?
— Чему равен 1байт?
6. Домашнее задание (Cмотри
приложение 
Выучить правило для измерения информации с точки зрения алфавитного подхода.
Выучить единицы измерения информации.
Решить задачу:
1) Мощность некоторого алфавита равна 64
символам. Каким будет объем информации в тексте,
состоящем из 100символов.
2) Информационный объем сообщения равен 4096 бит.
Оно содержит 1024 символа. Какова мощность
алфавита, с помощью которого составлено это
сообщение?
Задача №10. Измерение количества информации. Основы комбинаторики.
Автор материалов — Лада Борисовна Есакова.
При работе с вычислительной техникой, информационным объемом сообщения называют количество двоичных символов, которое используют для кодирования этого сообщения.
Чтобы найти информационный объем сообщения I, нужно количество символов этого сообщения N умножить на количество бит, выделяемых для кодирования одного символа
K : I = N * K.
Количество символов в некотором алфавите называется мощностью алфавита.
Несложно понять, что количество слов длиной N, составленных из символов (букв) алфавита мощностью M равно MN.
При компьютерном кодировании мощность алфавита равна 2, значит количество слов длиной N равно 2
Подсчет количества буквенных цепочек
Пример 1.
Все 5-буквенные слова, составленные из букв А, О, У, записаны в алфавитном порядке. Вот начало списка:
1. ААААА
2. ААААО
3. ААААУ
4. АААОА
……
Запишите слово, которое стоит на 210-м месте от начала списка.
Решение:
Заменим буквы А, О, У на 0, 1, 2 и выпишем начало списка:
1. 00000
2. 00001
3. 00002
4. 00010
…
Полученная запись есть числа, записанные в троичной системе счисления в порядке возрастания. Тогда на 210 месте будет стоять число 209 (т.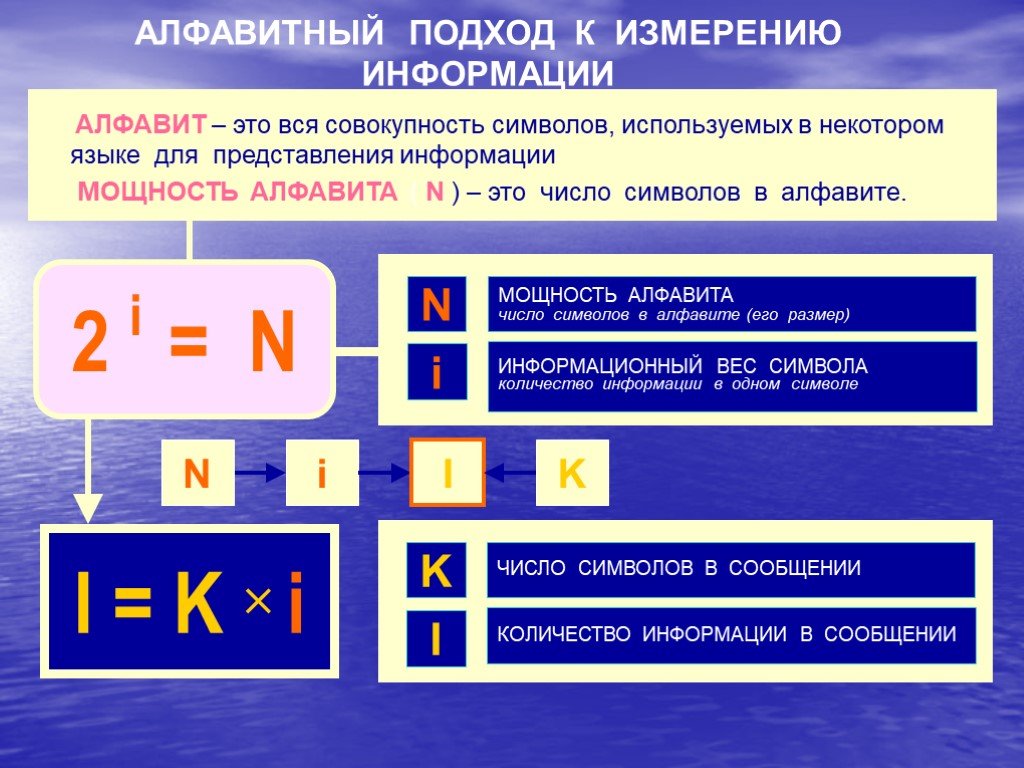 к. первое число 0). Переведём число 209 в троичную систему: 20910 = 212023
к. первое число 0). Переведём число 209 в троичную систему: 20910 = 212023
Заменим обратно цифры на буквы и получим УОУАУ.
Ответ: УОУАУ
Пример 2.
Сколько слов длины 6, начинающихся с согласной буквы, можно составить из букв Г, О, Д? Каждая буква может входить в слово несколько раз. Слова не обязательно должны быть осмысленными словами русского языка.
Решение:
На первом месте может стоять две буквы: Г или Д, на остальных — три буквы.
Слов, начинающихся на Г, 35. Слов, начинающихся на Д, тоже 35.Таким образом, можно составить 2 · 35 = 486 слов.
Ответ: 486
Пример 3.
Вася составляет 5-буквенные слова, в которых есть только буквы С, Л, О, Н, причём буква С используется в каждом слове ровно 1 раз. Каждая из других допустимых букв может встречаться в слове любое количество раз или не встречаться совсем. Словом считается любая допустимая последовательность букв, не обязательно осмысленная. Сколько существует таких слов, которые может написать Вася?
Словом считается любая допустимая последовательность букв, не обязательно осмысленная. Сколько существует таких слов, которые может написать Вася?
Решение:
Пусть С стоит в слове на первом месте. Тогда на каждое из оставшихся 4 мест можно поставить независимо одну из 3 букв. То есть всего 3*3*3*3 = 81 вариант. Таким образом, С можно по очереди поставить на все 5 мест, в каждом случае получая 81 вариант. Итого получается 81 * 5 = 405 слов.
Ответ: 405
Количество информации при двоичном (компьютерном) кодировании
Пример 4.
Объем сообщения – 7,5 Кбайт. Известно, что данное сообщение содержит 7680 символов. Какова мощность алфавита?
Решение:
Объем сообщения I, написанного в исходном алфавите мощности M, содержащего N символов, равен: I = log2M * N
I = 7680 * log2M
Log2M = (7,5 * 213 бит) / 7680 =(7,5 * 213) /(15 * 29) = 8
M = 28 = 256
Ответ: 256
Количество информации при различных (не компьютерных) способах кодирования
Пример 5.
Азбука Морзе позволяет кодировать символы для сообщений по радиосвязи, задавая комбинацию точек и тире. Сколько различных символов (цифр, букв, знаков пунктуации и т. д.) можно закодировать, используя код азбуки Морзе длиной не менее четырёх и не более пяти сигналов (точек и тире)?
Решение:
Мы имеем алфавит из двух букв: точка и тире. Из двух букв можно составить 24 четырёхбуквенных слова и 25 пятибуквенных слов.
Значит, всего можно закодировать 16 + 32 = 48 различных символов.
Ответ: 48
Пример 6.
Световое табло состоит из лампочек. Каждая лампочка может находиться в одном из трех состояний («включено», «выключено» или «мигает»). Какое наименьшее количество лампочек должно находиться на табло, чтобы с его помощью можно было передать 18 различных сигналов?
Решение:
Мощность алфавита M =3 («включено», «выключено» или «мигает»).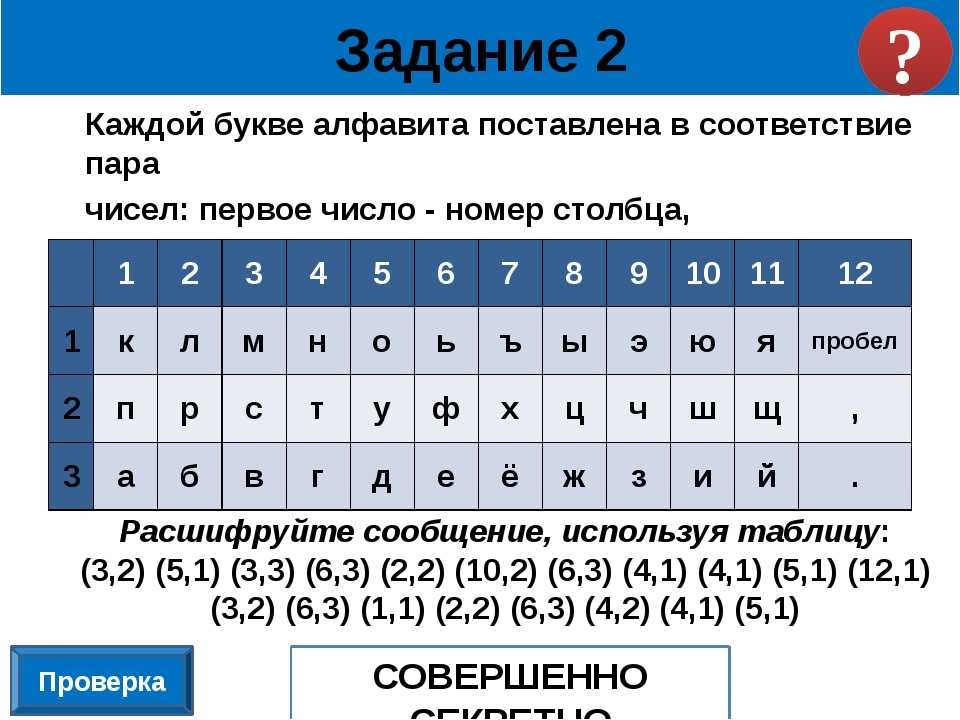
Количество различных сигналов 18 <= MN= 3N. (Поскольку равенство не выполняется, N берем с избытком, иначе не сможем закодировать все сигналы). N = 3.
Ответ: 3
Благодарим за то, что пользуйтесь нашими публикациями. Информация на странице «Задача №10. Измерение количества информации. Основы комбинаторики.» подготовлена нашими авторами специально, чтобы помочь вам в освоении предмета и подготовке к экзаменам. Чтобы успешно сдать нужные и поступить в ВУЗ или техникум нужно использовать все инструменты: учеба, контрольные, олимпиады, онлайн-лекции, видеоуроки, сборники заданий. Также вы можете воспользоваться другими материалами из данного раздела.
Публикация обновлена: 09.03.2023
Текст — Представление данных — Полевое руководство по информатике
Существует несколько различных способов, которыми компьютеры используют биты для хранения текста.
В этом разделе мы рассмотрим некоторые распространенные, а затем рассмотрим плюсы и минусы каждого представления.
5.4.1.
ASCII
Ранее мы видели, что с помощью 6 точек шрифта Брайля можно создать 64 уникальных шаблона. Точка соответствует биту, потому что и точки, и биты имеют 2 разных возможных значения.
Подсчитайте, сколько различных символов вы можете ввести в текстовом редакторе с помощью клавиатуры. (Не забудьте подсчитать оба символа, которые используются совместно с цифровыми клавишами, и символы, расположенные сбоку от знаков препинания!)
Персонажи Жаргон БастерОбщее название для прописных и строчных букв, цифр и символов — это символы, например, a, D, 1, h, 6, *, ] и ~ — все символы. Важно отметить, что пробел также является символом.
Если вы сосчитали правильно, вы должны обнаружить, что было больше 64 символов, и вы могли найти около 95.
Поскольку 6 бит могут представлять только 64 символа, нам потребуется больше 6 бит; получается, что нам нужно как минимум 7 бит для представления всех этих символов, так как это дает 128 возможных шаблонов. Это именно то, что делает ASCII-представление текста.
Это именно то, что делает ASCII-представление текста.
В предыдущем разделе мы объяснили, что происходит, когда количество точек увеличивается на 1 (помните, что точка в шрифте Брайля фактически равна биту). Можете ли вы объяснить, откуда мы узнали, что если 6 бит достаточно для представления 64 символов, то 7 бит должно быть достаточно для представления 128 символов?
Каждый шаблон в ASCII обычно хранится в 8 битах с одним потерянным битом, а не в 7 битах. Однако крайний левый бит в каждом 8-битном шаблоне равен 0, что означает, что существует только 128 возможных шаблонов. Там, где это возможно, мы предпочитаем иметь дело с полными байтами (8 битами) на компьютере, поэтому в ASCII есть лишний потерянный бит.
Вот таблица, в которой показаны шаблоны битов, которые ASCII использует для каждого из символов.
| Двоичный | Символ | Двоичный | Символ | Двоичный | Символ |
|---|---|---|---|---|---|
| 0100000 | Пробел | 1000000 | @ | 1100000 | ` |
| 0100001 | ! | 1000001 | А | 1100001 | и |
| 0100010 | » | 1000010 | Б | 1100010 | б |
| 0100011 | # | 1000011 | С | 1100011 | в |
| 0100100 | $ | 1000100 | Д | 1100100 | д |
| 0100101 | % | 1000101 | Е | 1100101 | и |
| 0100110 | и | 1000110 | Ф | 1100110 | ф |
| 0100111 | ‘ | 1000111 | Г | 1100111 | г |
| 0101000 | ( | 1001000 | Х | 1101000 | ч |
| 0101001 | ) | 1001001 | я | 1101001 | и |
| 0101010 | * | 1001010 | Дж | 1101010 | и |
| 0101011 | + | 1001011 | К | 1101011 | к |
| 0101100 | , | 1001100 | л | 1101100 | л |
| 0101101 | — | 1001101 | М | 1101101 | м |
| 0101110 | . | 1001110 | Н | 1101110 | п |
| 0101111 | / | 1001111 | О | 1101111 | или |
| 0110000 | 0 | 1010000 | Р | 1110000 | р |
| 0110001 | 1 | 1010001 | В | 1110001 | к |
| 0110010 | 2 | 1010010 | Р | 1110010 | р |
| 0110011 | 3 | 1010011 | С | 1110011 | с |
| 0110100 | 4 | 1010100 | Т | 1110100 | т |
| 0110101 | 5 | 1010101 | У | 1110101 | и |
| 0110110 | 6 | 1010110 | В | 1110110 | против |
| 0110111 | 7 | 1010111 | Вт | 1110111 | с |
| 0111000 | 8 | 1011000 | х | 1111000 | х |
| 0111001 | 9 | 1011001 | Д | 1111001 | г |
| 0111010 | : | 1011010 | З | 1111010 | из |
| 0111011 | ; | 1011011 | [ | 1111011 | { |
| 0111100 | < | 1011100 | \ | 1111100 | | |
| 0111101 | = | 91111110 | ~ | ||
| 0111111 | ? | 1011111 | _ | 1111111 | Удалить |
Например, буква «c» (нижний регистр) в таблице имеет шаблон «01100011» (0 в начале — это просто дополнительное дополнение, чтобы увеличить ее до 8 бит).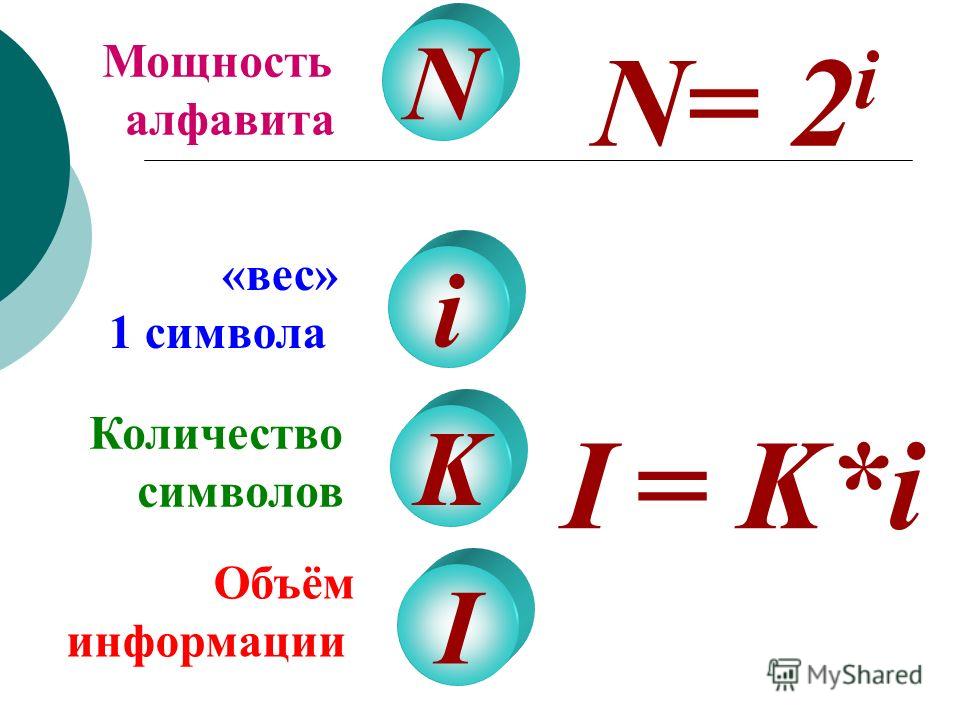 Буква «о» имеет узор «01101111».
Вы можете написать слово, используя этот код, и если вы дадите его кому-то другому, он сможет точно его расшифровать.
Буква «о» имеет узор «01101111».
Вы можете написать слово, используя этот код, и если вы дадите его кому-то другому, он сможет точно его расшифровать.
Компьютеры могут представлять фрагменты текста последовательностями этих шаблонов, как это делает Брайль. Например, слово «компьютеры» (все в нижнем регистре) будет 01100011 01101111 01101101 01110000 01110101 01110100 01100101 01110010 01110011. Это потому, что «c» — это «01100011», «o» — это «01101111» и так далее. Взгляните на приведенную выше таблицу ASCII, чтобы проверить, правы ли мы!
Что означает ASCII? Любопытство Название «ASCII» означает «Американский стандартный код для обмена информацией», который представлял собой особый способ присвоения битовых комбинаций символам на клавиатуре.
Система ASCII даже включает «символы» для звонка в колокол (полезно для привлечения внимания к старым телеграфным системам), удаления предыдущего символа (своего рода ранняя «отмена») и «конец передачи» (чтобы получатель знал, что сообщение было закончено). В наши дни эти символы редко используются, но коды для них все еще существуют (это отсутствующие шаблоны в таблице выше).
В настоящее время ASCII был вытеснен кодом под названием «UTF-8», который оказывается таким же, как ASCII, если дополнительный левый бит равен 0, но открывает огромный диапазон символов, если левый бит равен 0. 1.
В наши дни эти символы редко используются, но коды для них все еще существуют (это отсутствующие шаблоны в таблице выше).
В настоящее время ASCII был вытеснен кодом под названием «UTF-8», который оказывается таким же, как ASCII, если дополнительный левый бит равен 0, но открывает огромный диапазон символов, если левый бит равен 0. 1.
Попробуйте выполнить следующие упражнения в ASCII:
- Как бы вы представили слово «наука» в ASCII? (игнорируйте знаки
") - Как бы вы представили «Wellington» в ASCII? (обратите внимание, что оно начинается с заглавной буквы «W»)
- Как бы вы представили «358» в ASCII? (это три символа , даже если это выглядит как число)
- Как бы вы представили «Привет, как дела?» в ASCII? (ищите запятую, вопросительный знак и символы пробела в таблице ASCII)
Обязательно попробуйте их все, прежде чем проверять ответ!
Ответы на вопросы выше Спойлер! Вот ответы.
- «science» = 01110011 01100011 01101001 01100101 01101110 01100011 01100101
- «Wellington» = 01010111 01100101 01101100 01101100 01101001 01101110 01100111 01110100 01101111 01101110
- «358» = 00110011 00110101 00111000
- «Hello, how are you?» = 1001000 1100101 1101100 1101100 1101111 0101100 0100000 1101000 1101111 1110111 0100000 1100001 1110010 1100101 0100000 1111001 1101111 1110101 0111111
Обратите внимание, что текст «358» обрабатывается как 3 символа в ASCII, что может сбивать с толку, поскольку текст «358» отличается от числа 358!
Вы могли столкнуться с этим различием в электронной таблице, например. если ячейка начинается с кавычки в Excel, она обрабатывается как текст, а не число.
Одно место, где это происходит, — это телефонные номера; если вы введете 027555555 в электронную таблицу как число, оно появится как 27555555, но в виде текста может отображаться 0.
На самом деле телефонные номера — это не просто цифры, потому что начальный ноль может быть важен, так как они могут содержать другие символы — например, +64 3 555 1234 доб. 1234.
1234.
Использование ASCII на практике
ASCII впервые был использован в коммерческих целях в 1963 году, и, несмотря на большие изменения в компьютерах с тех пор, он по-прежнему является основой для хранения английского текста на компьютерах. ASCII присвоил каждому из символов разные комбинации битов, а также несколько других «управляющих» символов, таких как удаление или возврат.
Английский текст можно легко представить с помощью ASCII, но как насчет таких языков, как китайский, где тысячи разных символов? Неудивительно, что 128 шаблонов недостаточно для представления таких языков. Из-за этого ASCII не так полезен на практике и больше не используется широко. В следующих разделах мы рассмотрим Unicode и его представления. Это решает проблему невозможности представления неанглийских символов.
Что было до ASCII? Любопытство Есть несколько других кодов, которые были популярны до ASCII, включая код Бодо и EBCDIC. Широко используемым вариантом кода Бодо был «код Мюррея», названный в честь новозеландского изобретателя Дональда Мюррея).
Одним из значительных улучшений Мюррея было введение идеи «управляющих символов», таких как возврат каретки (новая строка).
Клавиша «управление» все еще существует на современных клавиатурах.
Широко используемым вариантом кода Бодо был «код Мюррея», названный в честь новозеландского изобретателя Дональда Мюррея).
Одним из значительных улучшений Мюррея было введение идеи «управляющих символов», таких как возврат каретки (новая строка).
Клавиша «управление» все еще существует на современных клавиатурах.
5.4.2.
Введение в Юникод
На практике нам нужно иметь возможность представлять не только английские символы. Чтобы решить эту проблему, мы используем стандарт под названием unicode. Unicode — это набор из символов , содержащий около 120 000 различных символов на многих разных языках, современных и исторических. Каждому персонажу присвоен уникальный номер, что упрощает его идентификацию.
Юникод сам по себе не представление — это набор символов.
Чтобы представить символы Unicode в виде битов, Unicode используется схема кодирования .
Схема кодирования Unicode говорит нам, как каждое число (которое соответствует символу Unicode) должно быть представлено с помощью шаблона битов.
Следующий интерактив позволит вам изучить набор символов Unicode. Введите число в поле слева, чтобы увидеть, какой символ Unicode ему соответствует, или введите символ справа, чтобы узнать, какой у него номер Unicode (вы можете вставить его с веб-страницы на иностранном языке, чтобы увидеть, что происходит с не -английские символы).
Символы Unicode
Десятичный
Нет соответствующего символа
Символ
Наиболее широко используемые схемы кодирования Unicode называются UTF-8, UTF-16 и UTF-32;
вы могли видеть эти имена в заголовках электронных писем или описаниях текстовых файлов.
Некоторые из схем кодирования Unicode имеют фиксированную длину , а некоторые — переменной длины . Фиксированная длина означает, что каждый символ представлен с использованием одинакового количества битов. Переменная длина означает, что некоторые символы представлены меньшим количеством битов, чем другие. Лучше иметь переменную длину , так как это гарантирует, что наиболее часто используемые символы будут представлены меньшим количеством битов, чем редко используемые символы.
Конечно, то, что может быть наиболее часто используемым иероглифом в английском языке, не обязательно является наиболее часто используемым иероглифом в японском языке.
Вам может быть интересно, зачем нам так много схем кодирования для Unicode.
Оказывается, некоторые лучше подходят для текста на английском языке, а некоторые — для текста на азиатском языке.
Лучше иметь переменную длину , так как это гарантирует, что наиболее часто используемые символы будут представлены меньшим количеством битов, чем редко используемые символы.
Конечно, то, что может быть наиболее часто используемым иероглифом в английском языке, не обязательно является наиболее часто используемым иероглифом в японском языке.
Вам может быть интересно, зачем нам так много схем кодирования для Unicode.
Оказывается, некоторые лучше подходят для текста на английском языке, а некоторые — для текста на азиатском языке.
В оставшейся части раздела представления текста будут рассмотрены некоторые из этих схем кодирования Unicode, чтобы вы поняли, как их использовать и почему некоторые из них лучше других в определенных ситуациях.
5.4.3.
UTF-32
UTF-32 — это схема кодирования Unicode с фиксированной длиной .
Представление каждого символа — это просто его число, преобразованное в 32-битное двоичное число.
Ведущие нули используются, если битов недостаточно (точно так же, как вы можете представить 254 как 4-значное десятичное число — 0254). 32 бита — это хорошее круглое число на компьютере, которое часто называют словом (что немного сбивает с толку, поскольку мы можем использовать символы UTF-32 для представления английских слов!)
32 бита — это хорошее круглое число на компьютере, которое часто называют словом (что немного сбивает с толку, поскольку мы можем использовать символы UTF-32 для представления английских слов!)
Например, символ H в UTF-32 будет выглядеть так:
00000000 00000000 00000000 01001000
Символ $ в UTF-32 будет следующим:
00000000 00000000 00000000 00100100
И символ 犬 (собака по-китайски) в UTF-32 будет:
00000000 00000000 01110010 10101100
Следующий интерактивный файл позволит вам преобразовать символ Unicode в его представление UTF-32. Также отображается номер символа Unicode. Биты — это просто двоичная форма числа символов.
Представьте свое имя с помощью UTF-32 Проект- Представляйте каждый символ своего имени в кодировке UTF-32.
- Проверьте, сколько битов требуется для вашего представления, и объясните, почему в нем так много (помните, что для каждого символа требуется 32 бита)
- Объясните, как вы узнали, как представлять каждый символ.
 Даже если вы использовали интерактив, вы все равно должны быть в состоянии объяснить его с точки зрения двоичных чисел.
Даже если вы использовали интерактив, вы все равно должны быть в состоянии объяснить его с точки зрения двоичных чисел.
 Даже если вы использовали интерактив, вы все равно должны быть в состоянии объяснить его с точки зрения двоичных чисел.
Даже если вы использовали интерактив, вы все равно должны быть в состоянии объяснить его с точки зрения двоичных чисел.ASCII фактически использовал тот же подход. Каждый символ ASCII имеет число от 0 до 255, а представление символа — число, преобразованное в 8-битное двоичное число. ASCII также является схемой кодирования с фиксированной длиной — каждый символ в ASCII представлен 8 битами.
На практике UTF-32 используется редко — вы можете видеть, что это занимает много места. UTF-8 и UTF-16 являются очень широко используемыми схемами кодирования переменной длины. Мы рассмотрим их далее.
Насколько велики 32 бита? ИспытаниеКакое наибольшее число может быть представлено 32 битами? (как в десятичном, так и в двоичном формате).
Наибольшее число в Юникоде, которому назначен символ, на самом деле не является самым большим возможным 32-битным числом — это 00000000 00010000 11111111 11111111.
Что это за десятичное число?Большинство чисел, которые могут быть составлены с использованием 32 бит, не имеют прикрепленных к ним символов Unicode — много свободного места. Для этого есть веские причины, но если бы у вас было более короткое число, которое могло бы представлять любой символ, какое минимальное количество битов вам потребовалось бы, учитывая, что в настоящее время существует около 120 000 символов Unicode?
 Что это за десятичное число?
Что это за десятичное число?Наибольшее число, которое можно представить с помощью 32 бит, равно 4,29.4 967 295 (около 4,3 миллиарда). Возможно, вы уже видели это число раньше — это самое большое целое число без знака, которое 32-битный компьютер может легко представить в таких языках программирования, как C.
Десятичное число для самого большого символа — 1 114 111.
Вы можете представить все текущие символы с помощью 17 бит.
Максимальное число, которое вы можете представить с помощью 16 бит, равно 65 536, что недостаточно.
Если мы дойдем до 17 бит, это даст 131 072, что больше 120 000.
Следовательно, нам нужно 17 бит.
 Максимальное число, которое вы можете представить с помощью 16 бит, равно 65 536, что недостаточно.
Если мы дойдем до 17 бит, это даст 131 072, что больше 120 000.
Следовательно, нам нужно 17 бит.
Максимальное число, которое вы можете представить с помощью 16 бит, равно 65 536, что недостаточно.
Если мы дойдем до 17 бит, это даст 131 072, что больше 120 000.
Следовательно, нам нужно 17 бит.5.4.4.
UTF-8
UTF-8 — это схема кодирования переменной длины для Unicode. Для представления символов с более низким номером Unicode требуется меньше битов, чем для символов с более высоким номером Unicode. Представления UTF-8 содержат 8, 16, 24 или 32 бита. Помня, что байт — это 8 бит, это 1, 2, 3 и 4 байта.
Например, символ H в UTF-8 будет выглядеть так:
01001000
Символ ǿ в UTF-8 будет следующим:
11000111 10111111
И символ 犬 (собака по-китайски) в UTF-8 будет:
11100111 10001010 10101100
Следующий интерактивный файл позволит вам преобразовать символ Unicode в его представление UTF-8. Также отображается номер символа Unicode.
Также отображается номер символа Unicode.
Как работает UTF-8?
Так как же на самом деле работает UTF-8? Используйте следующий процесс, чтобы сделать то, что делает интерактив, и самостоятельно преобразовать символы в UTF-8.
Шаг 1. Найдите номер Unicode вашего персонажа.
Шаг 2. Преобразуйте число Unicode в двоичное число, используя как несколько битов по мере необходимости. Вернитесь к разделу о двоичных числах, если вы не можете вспомнить, как преобразовать число в двоичное.
Шаг 3. Подсчитайте количество битов в двоичном числе и выберите правильный шаблон для использования, исходя из количества битов. Шаг 4 объяснит, как использовать шаблон.
7 или меньше битов: 0xxxxxxx 11 или меньше бит: 110xxxxx 10xxxxxx 16 или меньше бит: 1110xxxx 10xxxxxx 10xxxxxx 21 бит или меньше: 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
Шаг 4. Замените крестики в шаблоне битами двоичного числа, которое вы преобразовали на шаге 2. Если иксов больше, чем битов, замените крайние слева лишние иксы на 0.
Если иксов больше, чем битов, замените крайние слева лишние иксы на 0.
Например, если вы хотите узнать представление для 貓 (кошка на китайском языке), вы должны предпринять следующие шаги.
Шаг 1. Определите, что номер Unicode для 貓 равен 35987 .
Шаг 2. Преобразовать 35987 в двоичный код, получив 10001100 10010011 .
Шаг 3. Подсчитайте, что имеется 16 бит, поэтому следует использовать третий шаблон 1110xxxx 10xxxxxx 10xxxxxx .
Шаг 4. Подставьте биты в шаблон, чтобы заменить крестики – 11101000 10110010 10010011 .
Таким образом, представление для 貓 будет 11101000 10110010 10010011 с использованием UTF-8.
5.4.5.
UTF-16
Как и UTF-8, UTF-16 представляет собой схему кодирования переменной длины для Unicode. Поскольку он намного сложнее, чем UTF-8, мы не будем здесь объяснять, как он работает.
Поскольку он намного сложнее, чем UTF-8, мы не будем здесь объяснять, как он работает.
Однако следующий интерактив позволит вам представить текст с помощью UTF-16. Попробуйте поместить в него текст на английском и текст на японском. Сравните представления с тем, что вы получаете с UTF-8.
5.4.6.
Сравнение текстовых представлений
Мы рассмотрели ASCII, UTF-32, UTF-8 и UTF-16.
Следующая таблица суммирует все, что мы говорили до сих пор о каждом представлении.
| Представительство | Переменная или фиксированная | бит на символ | Использование в реальном мире |
|---|---|---|---|
| ASCII | Фиксированная длина | 8 бит | Больше не используется |
| UTF-8 | Переменная длина | 8, 16, 24 или 32 бита | Очень широко используется |
| UTF-16 | Переменная длина | 16 или 32 бита | Широко используемый |
| UTF-32 | Фиксированная длина | 32 бита | Редко используется |
Чтобы сравнить и оценить их, нам нужно решить, что значит для представления быть «хорошим». Два полезных критерия:
Два полезных критерия:
- Может представлять все символы независимо от языка.
- Представляет фрагмент текста, используя как можно меньше битов.
Мы знаем, что UTF-8, UTF-16 и UTF-32 могут представлять все символы, а ASCII может представлять только английский язык. Следовательно, ASCII не соответствует первому критерию. А вот со вторым критерием все не так просто.
Следующий интерактив позволит вам узнать длину фрагментов текста, используя UTF-8, UTF-16 или UTF-32. Найдите несколько образцов текста на английском и азиатском языках (хорошее место для поиска — форумы или переводческий сайт) и посмотрите, насколько длинными будут ваши различные образцы, закодированные с каждым из трех представлений. Скопируйте и вставьте или введите текст в поле.
Unicode Encoding Size
Enter text for length calculation:
Encoding lengths:
UTF-8: 0 bits
UTF-16: 0 bits
UTF-32: 0 bits
Как правило, UTF-8 лучше подходит для английского текста, а UTF-16 лучше для азиатского текста.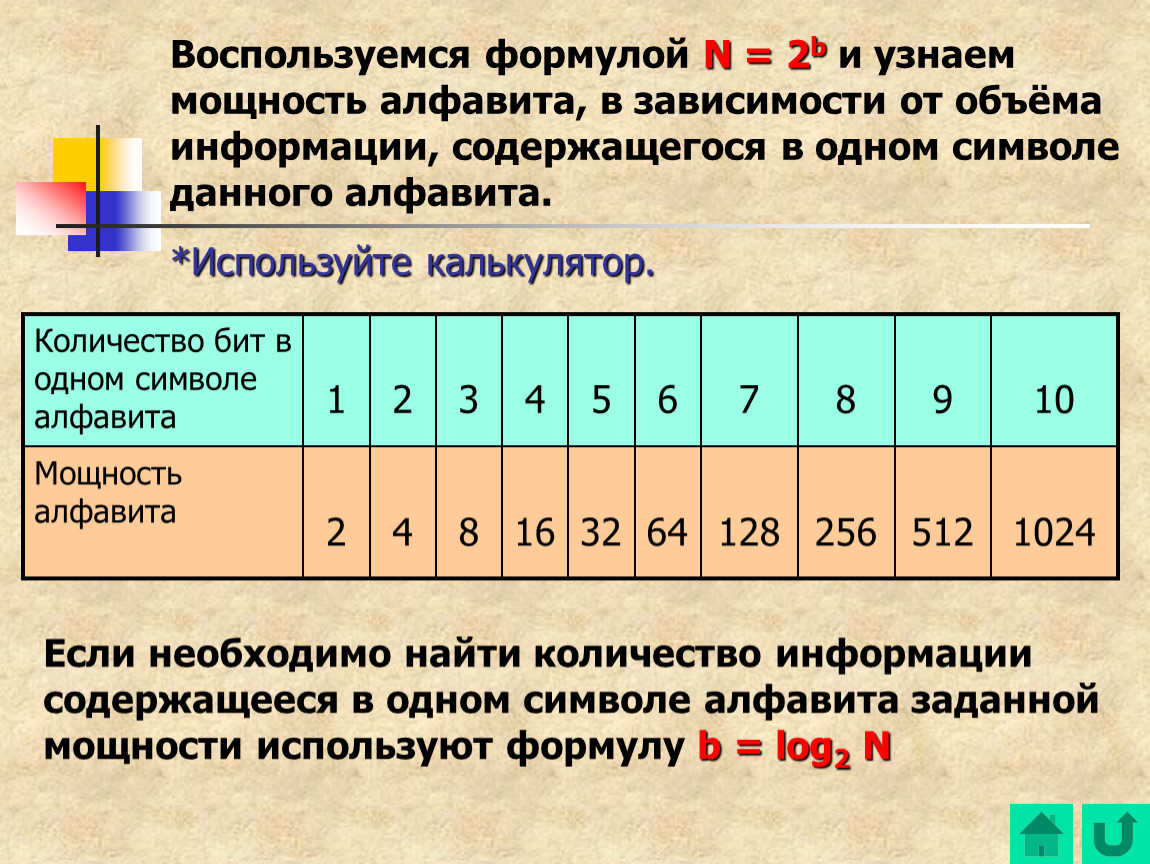 UTF-32 всегда требует 32 бита для каждого символа, поэтому на практике он непопулярен.
UTF-32 всегда требует 32 бита для каждого символа, поэтому на практике он непопулярен.
Эти милые маленькие символы, которые вы можете использовать в своих статусах, текстах и т. д. в социальных сетях, называются «эмоджи», и каждый из них имеет собственное значение Unicode.
Японские мобильные операторы были первыми, кто использовал эмодзи, но их недавняя популярность привела к тому, что многие из них стали частью стандарта Unicode, и сегодня в него включено более 1000 различных эмодзи.
Актуальный их список можно увидеть здесь.
Интересно отметить, что один и тот же смайлик будет выглядеть по-разному на разных платформах, т. е. 😆 («улыбающееся лицо с открытым ртом и плотно закрытыми глазами») в моем твите будет выглядеть совсем иначе, чем на вашем iPhone. .
Это связано с тем, что Консорциум Unicode предоставляет только коды символов для каждого смайлика, а конечные поставщики определяют, как будет выглядеть этот смайлик, например. для устройств Apple используется шрифт «Apple Color Emoji» (для этого существуют правила, обеспечивающие единообразие в каждой системе).
для устройств Apple используется шрифт «Apple Color Emoji» (для этого существуют правила, обеспечивающие единообразие в каждой системе).
5.4.7.
Проект: Послания, скрытые в музыке
В этом видео есть сообщения, скрытые в 5-битном представлении. Посмотрим, сможешь ли ты их найти! Начните с чтения объяснения ниже, чтобы убедиться, что вы понимаете, что мы подразумеваем под 5-битным представлением.
Если вы только хотите представить 26 букв алфавита и не беспокоитесь о верхнем или нижнем регистре, вы можете обойтись всего 5 битами, что позволяет использовать до 32 различных шаблонов.
Возможно, вы обменялись нотами, в которых 1 вместо «а», 2 вместо «б», 3 вместо «в», вплоть до 26 вместо «z».
Мы можем преобразовать эти числа в 5-значные двоичные числа.
На самом деле, вы также получите те же 5 бит для каждой буквы, просмотрев последние 5 бит для нее в таблице ASCII (и не имеет значения, смотрите ли вы на прописную или строчную букву).
Представьте слово «вода» с помощью битов, используя эту систему. Проверьте панель ниже, как только вы решите, что она у вас есть.
Представительство по воде Спойлер!Вт: 10111 а: 00001 т: 10100 е: 00101 р: 10010
А теперь попробуйте расшифровать музыкальное видео!
Предыдущий:
Числа Следующий:
Изображения и цвета
404: Страница не найдена
Страница, которую вы пытались открыть по этому адресу, похоже, не существует. Обычно это результат плохой или устаревшей ссылки. Мы извиняемся за любые неудобства.
Что я могу сделать сейчас?
Если вы впервые посещаете TechTarget, добро пожаловать! Извините за обстоятельства, при которых мы встречаемся. Вот куда вы можете пойти отсюда:
Поиск- Свяжитесь с нами, чтобы сообщить об отсутствующей странице, или используйте поле выше, чтобы продолжить поиск
- Наша страница «О нас» содержит дополнительную информацию о сайте, на котором вы находитесь, WhatIs. com.
- Посетите нашу домашнюю страницу и просмотрите наши технические темы
 com.
com.Поиск по категории
Сеть
- полоса (полоса частот)
В телекоммуникациях полоса частот, иногда называемая полосой частот, относится к определенному диапазону частот в …
- HAProxy
HAProxy — это высокопроизводительный балансировщик нагрузки с открытым исходным кодом и обратный прокси-сервер для приложений TCP и HTTP.
- ACK (подтверждение)
В некоторых протоколах цифровой связи ACK — сокращение от «подтверждение» — относится к сигналу, который устройство отправляет, чтобы указать…
Безопасность
- постквантовая криптография
Постквантовая криптография, также известная как квантовое шифрование, представляет собой разработку криптографических систем для классических компьютеров.
.. - деинициализация
Деинициализация — это часть жизненного цикла сотрудника, в ходе которой лишаются прав доступа к программному обеспечению и сетевым службам.
- Требования PCI DSS 12
Требования PCI DSS 12 представляют собой набор мер безопасности, которые предприятия должны внедрить для защиты данных кредитных карт и соблюдения …
 ..
..ИТ-директор
- Agile-манифест
The Agile Manifesto — это документ, определяющий четыре ключевые ценности и 12 принципов, в которые его авторы верят разработчики программного обеспечения…
- Общее управление качеством (TQM)
Total Quality Management (TQM) — это система управления, основанная на вере в то, что организация может добиться долгосрочного успеха, …
- системное мышление
Системное мышление — это целостный подход к анализу, который фокусируется на том, как взаимодействуют составные части системы и как.
..
 ..
..HRSoftware
- вовлечения сотрудников
Вовлеченность сотрудников — это эмоциональная и профессиональная связь, которую сотрудник испытывает к своей организации, коллегам и работе.
- кадровый резерв
Кадровый резерв — это база данных кандидатов на работу, которые могут удовлетворить немедленные и долгосрочные потребности организации.
- разнообразие, равенство и инклюзивность (DEI)
Разнообразие, равенство и инклюзивность — термин, используемый для описания политики и программ, которые способствуют представительству и …
Отдел обслуживания клиентов
- требующий оценки
Оценка потребностей — это систематический процесс, в ходе которого изучается, какие критерии должны быть соблюдены для достижения желаемого результата.
- точка взаимодействия с клиентом
Точка соприкосновения с покупателем — это любой прямой или косвенный контакт покупателя с брендом.

Leave A Comment