
Кодирование таблиц данных — AggreGate Documentation
Любая таблица данных может кодироваться в или декодироваться из:
- Строки Юникода
- Байтового массива
Кодирование и декодирование строк часто используется для программного манипулирования таблицами данных, например, через Java SDK или .NET API. Строковое представление табличных форматов также часто используется для компактного и удобного для чтения отображения данных.
Кодирование и декодирование байтовых массивов используется для переноса таблиц данных по сети при помощи Коммуникационного протокола AggreGate или хранения их в базе данных AggreGate Server.
Кодирование байтовых массивов
Перекодирование таблицы данных в байтовый массив проходит в два этапа:
- Во-первых, таблица данных кодируется в строку Юникода
- Во-вторых, строка результата кодируется в байтовый массив при помощи кодировки UTF-8. См. документацию по UTF-8 (например, Статья в Wikipedia по UTF-8) для более подробного ознакомления.


Концепция кодирования строк
В целом, таблица данных и её различные части закодированы в строку как ряд элементов следующего формата:
<[element_name=]element_value>
Имя и значение могут включать любой символ, за исключением тех, которые использует протокол взаимодействия AggreGatel или тех, которые используются для кодирования самого элемента. Значение элемента может быть закодированным списком вложенных элементов.
Кодирование таблицы
Здесь представлен формат для закодированной таблицы данных:
<F=record_format>[<I=>][<R=record>][<R=record>]…
Имя элемента | Значение элемента |
| Дескриптор формата таблицы, определяющий имена и типы всех колонок в таблице данных или других свойств таблицы. О его кодировании говорится здесь. |
| ID формата таблицы. Более поробно см. раздел кэширование формата. |
| Элемент для проверки. Если данный элемент найден в таблице данных, вся таблица считается неверной. Когда AggreGate Server запрашивает значение переменной от агента, агент сначала подтверждает запрос, а затем начинает опрос записей с аппаратного устройства. В это время сервер «думает», что он получает полную и правильную таблицу. Если в этот момент возникает внезапный разрыв связи между агентом и устройством, и по какой-то причине агент не получает данные, которые он должен получать от аппаратного устройства, агент вставляет проверочный элемент в таблицу данных, отправляемую серверу. Этот элемент сообщает серверу, что он не может полностью получить все эти данные. После получения этого элемента сервер «знает», что операция не может быть полностью завершена. |
| Запись таблицы данных. |
| Временная метка таблицы данных. Обычно указывает на время создания/получения самой таблицы данных или выборки данных, которую она представляет. Временная метка кодируется в строку как количество миллисекунд с начала отсчета времени (1 января 1970 г.). |
| Качество таблицы. Оно объясняет, насколько надежна выборка данных, представленная таблицей данных. Качество является 32-битным подписанным целым значением, закодированным в строку. |

 Записи закодированы одна за другой. Формат закодированных записей описан ниже.
Записи закодированы одна за другой. Формат закодированных записей описан ниже.Пример: Этот пример показывает, что формат закодированной таблицы данных определяет одно поле строки, именуемое «IP», и что он содержит одну запись со значением «192. |
 168.1.88″. См. дополнительную информацию о записи и кодировке формата ниже.
168.1.88″. См. дополнительную информацию о записи и кодировке формата ниже.Кодировка формата таблицы
record_format включён в каждую таблицу данных, даже если она пустая. Кодировка выглядит следующим образом:
<field_format><field_format>…[<F=flags>][<V=table_validators>][<R=record_validators>][M=min_records][X=max_records][<B=bindings>][<N=naming_expression>]
Элементы без идентификаторов (как показано в примере ранее <field_format>) считаются дескрипторами закодированных форматов полей таблиц. Дескрипторы формата полей закодированы один за другим, начиная с самого первого поля.
Имя элемента | Значение элемента |
| Отсутствие или комбинация следующих флагов: “R” (Перемещаемый (Reorderable)) — указывает, что пользователи AggreGate могут перемещать во время редактирования ряды данной таблицы “U” (Неизменяемый (Unresizable)) — указывает, что пользователи не могут добавлять/удалять ряды во время редактирования таблицы. |
| Валидаторы таблиц, которые позволяют выполнять комплексное подтверждение всей таблицы. |
| Валидаторы записей, которые используются для подтверждения каждой записи. |
| Привязки таблиц. |
| Минимальное разрешённое количество записей в таблице. |
| Максимальное разрешённое количество записей в таблице. |
| Выражение имени таблицы. |
Пример: Этот формат, описывающий таблицу с одной ячейкой (одно поле, минимальное и максимальное количество записей тоже одно). Единственное имя таблицы — «date», и его тип — Дата. |
 См дополнительную информацию о кодировании формата ниже.
См дополнительную информацию о кодировании формата ниже.Пример: Этот формат описывает таблицу с двумя полями, которая может содержать от 0 до 255 записей. Первое поле строки называется «id», а его описание — «Card ID». У него есть валидатор, который ограничивает длину значения ровно до 10 знаков. Второе поле также представляет собой тип строки и называется «name». |
Кодирование формата поля
field_format — это строка, описывающая одно поле в таблице данных. Оно форматируется следующим образом:
<name><type>[<F=flags>][<A=default>][<D=description>][<H=help>][<S=selection_values>][<V=validators>][<E=editor>]
У первых двух элементов нет имен.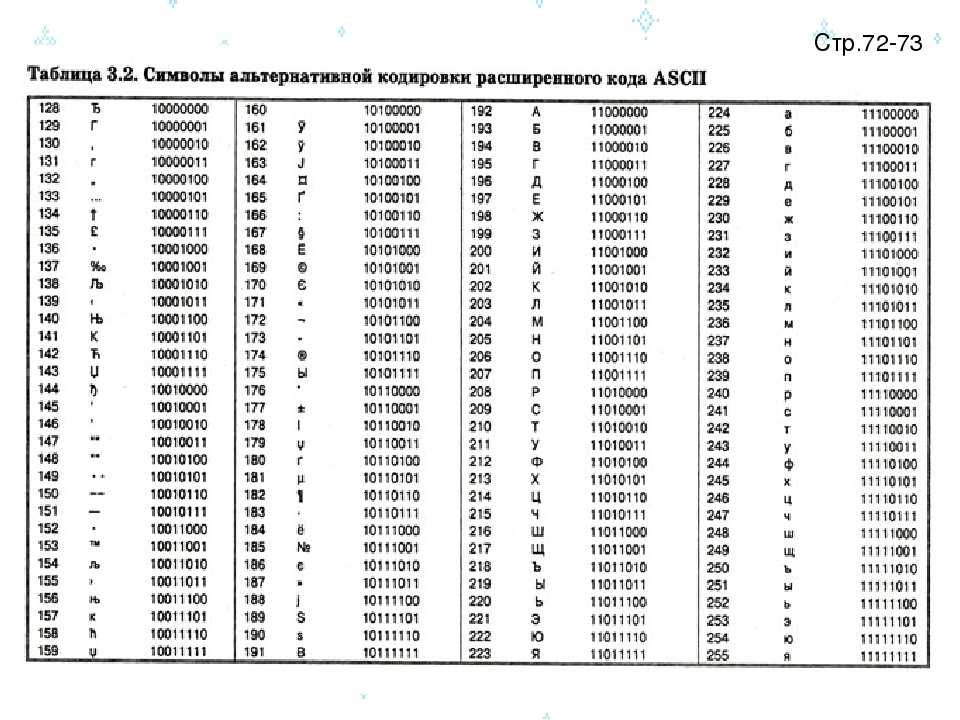 Первый элемент — имя поля, а второй содержит код типа поля (см таблицу ниже).
Первый элемент — имя поля, а второй содержит код типа поля (см таблицу ниже).
Имя элемента | Значение элемента |
| Отсутствие или комбинация следующих флагов: “ “ “ “ “ “ “ |
| Значение поля, по умолчанию закодированное в строку (см раздел кодирование значения ) |
| Описание поля |
| Подсказка поля (подробное описание). |
| Список значений выбора для поля. См. правила кодирования здесь. |
| Список валидаторов полей. См. правила кодирования здесь. |
| Код редактора/отрисовщика. Этот элемент активирует пользовательское визуальное представление значения поля. Поддерживаемые редакторы и отрисовщики представлены здесь. |
| Специфичные опции редактора. Опции, поддерживаемые каждым типом редактора/отрисовщика представлены здесь. Если опции редактора не определены, этот элемент должен быть опущен в определении формата таблицы. |
| Строковое ID иконки поля. |
| Группа полей. |
 Ключевые поля используются во время операции умное копирование таблицы данных. Кроме того используется валидатор ключевых полей, цель которого удостовериться, что таблица не содержит записей с равными комбинациями всех ключевых полей.
Ключевые поля используются во время операции умное копирование таблицы данных. Кроме того используется валидатор ключевых полей, цель которого удостовериться, что таблица не содержит записей с равными комбинациями всех ключевых полей.
Пример: Это самый простой из возможных дескрипторов формата полей, который определяет поле целых чисел, называемых «значениями». |
Пример: Этот дескриптор формата определяет длинное поле (64-битное целое число) со значением по умолчанию, равным 30000. |
 Описание поля — «Период проверки». У него есть валидатор ограничений, который ограничивает значения, диапазон которых составляет от 100 до 1000000. Тип редактора/отрисовщика инструктирует систему использовать редактора Периода времени для редактирования значения поля.
Описание поля — «Период проверки». У него есть валидатор ограничений, который ограничивает значения, диапазон которых составляет от 100 до 1000000. Тип редактора/отрисовщика инструктирует систему использовать редактора Периода времени для редактирования значения поля.Типы полей и кодирование значений
Код типа | Тип | Передача | Комментарии и правила кодирования значения | ||
| String | Да | Вставлено как есть | ||
| Integer | Преобразовано в строку, например | |||
| Long | Преобразовано в строку, например | |||
| Boolean | TRUE закодировано как строка «1«, а FALSE как строка «0« | |||
| Float | Преобразовано в строку в соответствии с ниже приведёнными правилами. Все упомянутые символы являются символами ASCII.
Сколько цифр нужно ввести для дробной части m или a? Должна быть хотя бы одна цифра, чтобы представить дробную часть, плюс ровно столько цифр, сколько нужно, чтобы различить значение аргумента среди соседних значений типа Float (или Double, если обрабатывается число типа Double). То есть, предположим, что x — это точное математическое значение, представленное десятичным представлением, произведенным этим способом для конечного ненулевого аргумента d. Затем d должен стать значением типа Double, наиболее близким к x; или если два значения Double одинаково близки x, тогда d должен быть одним из них, а наименьшей мантиссой из d должен быть 0. | |||
| Double | Правила, как для типа Float | |||
| Date | Преобразовано в строку в форме «yyyy-MM-dd HH:mm:ss. yyyy — год MM — месяц dd — день месяца HH — час (0-23) mm -минуты ss — секунды SSS -миллисекунды Конвертация должна использовать временную зону UTC. | |||
| Data Table | Да | Таблица с включенными данными закодирована в строку согласно правилам Кодирования таблиц данных | ||
| Color | Преобразовано в строку в форме «#RRGGBB«, где RR — значение красного цвета (0-255) — шестнадцатеричная форма GG — значение зеленого цвета (0-255) -шестнадцатеричная форма BB — значение синего цвета (0-255) — шестнадцатеричная форма | |||
| Data Block | Да | Конвертируется в строку в следующем виде: Version / ID / Name / Preview_length / Data_length / Preview Data Строка содержит несколько частей, разделенных символом
При перекодировании блока данных в строку байты Предпросмотра и Данных конвертируются в символы Юникода с кодами 0…255, т.е. символами ASCII. |


 SSS«, где
SSS«, где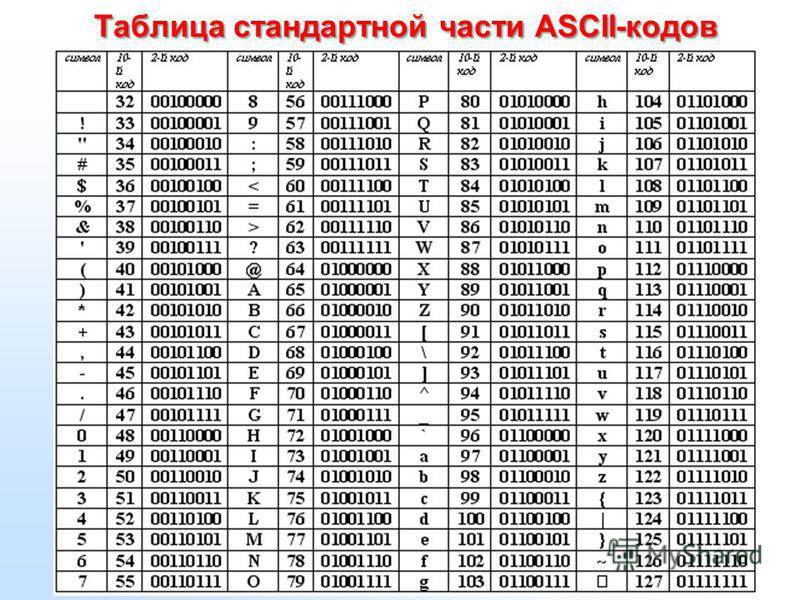 Это следующие части:
Это следующие части:
кодирование значений выбора
Значения для поля выбора кодируются как список элементов. Каждое имя элемента — это видимое описание значения выбора для пользователя (то, что пользователь увидит в окне списка). Значения элемента — это значение выбора, закодированное в строку, как описано в разделе кодирование значения.
Пример: список трёх значений выбора для поля с целым числом можно закодировать следующим образом: |
Кодирование валидаторов
Валидаторы полей закодированы как список элементов, по одному для каждого валидатора. Имя валидатора — Код типа валидатора, в то время как его значение содержит опции, специфичные для валидатора.
Валидаторы полей
Список поддерживаемых валидаторов поля:
Код типа | Описание | Подходящие типы полей | Опции, характерные для валидатора |
L | Валидатор ограничений. Проверяет, соответствует ли значение диапазону, заданному параметрами валидатора. | Строка, Целое, Длинное, Плавающее, Данные | Опции валидатора закодированы в строку как два целых числа, разделённые пробелом. Первое число обозначает минимальное значение диапазона, а второе число определяет максимальное. Эти числа имеют разное значение для разных типов полей: Для строковых полей эти параметры ограничивают минимальную и максимальную длину строки. Для целочисленных, длинных и плавающих полей они указывают минимальное и максимальное значение. Для полей с данными они ограничивают число байтов, которые могут содержаться в блоке данных. Границы включены для всех типов полей (т.е., ограничение «3» разрешило бы строке |
R | Валидатор регулярных выражений. Проверяет, соответствует ли значение строки регулярному выражению, заданному параметром валидатора. | Строка | Строка опций валидатора содержит регулярное выражение, которому значение поля должно соответствовать. Этот валидатор регулярных выражений проверяет, содержит ли поле правильный e-mail и отправляет сообщение об ошибке Invalid E-Mail, если адрес неправильный. За дополнительной информацией о регулярных выражениях обратитесь в раздел приложения Синтаксис регулярных выражений. |
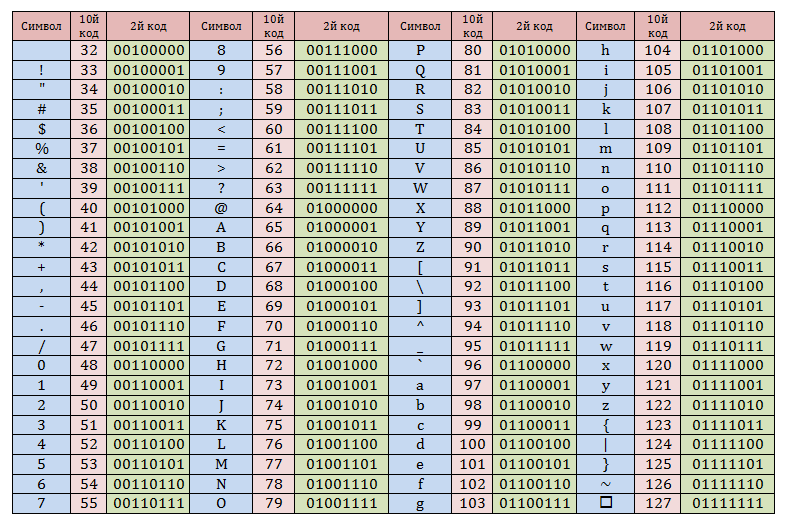
 , затем следует текст для сообщения об ошибке «Invalid E-Mail».
, затем следует текст для сообщения об ошибке «Invalid E-Mail».Валидаторы записей
Список поддерживаемых валидаторов записей:
Код типа | Описание | Опции, характерные для валидатора |
K | Ключевые поля. Проверяет, существует ли комбинация значений ключевых полей в таблице. Применяется во время добавления записи. | Отсутствуют — ключевые поля помечаются флажком Ключевое поле формата поля. |
Валидаторы таблиц
Список поддерживаемых валидаторов таблиц:
Код типа | Описание | Опции, характерные для валидатора |
K | Ключевые поля. | Отсутствуют — ключевые поля отмечены флажком Ключевое поле формата поля. |
E | Валидатор выражений. Оценивает выражение, имеющее данную таблицу как таблицу по умолчанию. Если выражение возвращает NULL, таблица считается верной, в ином случае вывод выражения конвертируется в строку и используется как текст сообщения об ошибке. | Текст выражения. |
 Проверяет, является ли комбинация значений ключевых полей уникальной для каждой записи.
Проверяет, является ли комбинация значений ключевых полей уникальной для каждой записи.Пример: Проверяет, больше ли одно поле другого. |
кодировка пустых значений
Пустое значение NULL («<Not set>») кодируется одним символом 0x1A (SUB).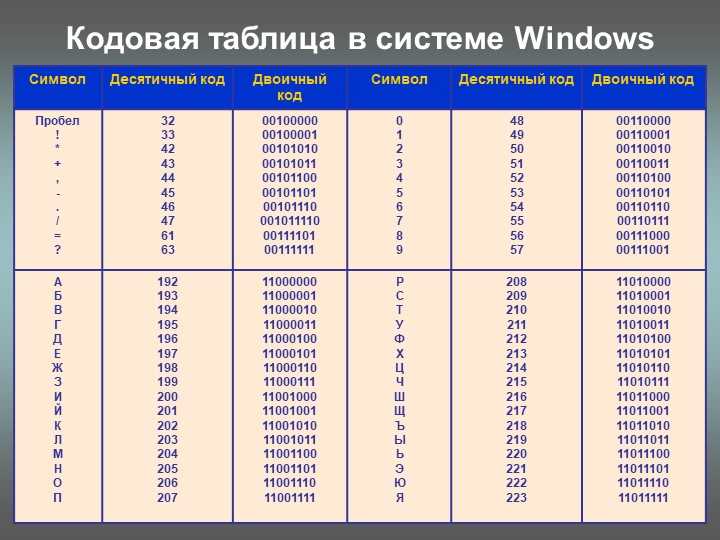
0x0D (CR)
%$
0x17 (ETB)
%/
0x1C (FS)
%<
0x1D (GS)
%>
0x1E (RS)
%=
Обратите внимание, что шаблоны в колонке «Заменяется на» являются символьными строками — это то, что Вы видите в таблице.
Кодирование записей данных
Каждая запись данных кодируется в строку согласно следующему формату:
[<I=record_ID>]<field_value><field_value>…
Элементы без имен — это значения поля. Значения полей кодируются одно за другим, в том же порядке, как они появляются в дескрипторе формата таблиц.
Имя элемента | Значение элемента |
| ID записи (Длинное число) |
Режимы кодирования строки
Каждую таблицу данных можно кодировать в двух режимах:
- используя видимые разделители
- используя невидимые разделители
Три специальных символа используются в качестве разделителей для кодирования:
Видимый разделитель | Невидимый разделитель (код) |
< | 0x1C |
> | 0x1D |
= | 0x1E |
В этом разделе во всех примерах используются видимые разделители. Единственное ограничение при кодировании таблицы с использованием видимых разделителей — это его разные элементы, когда они закодированы в строку, то не должны содержать данные разделители.
Единственное ограничение при кодировании таблицы с использованием видимых разделителей — это его разные элементы, когда они закодированы в строку, то не должны содержать данные разделители.
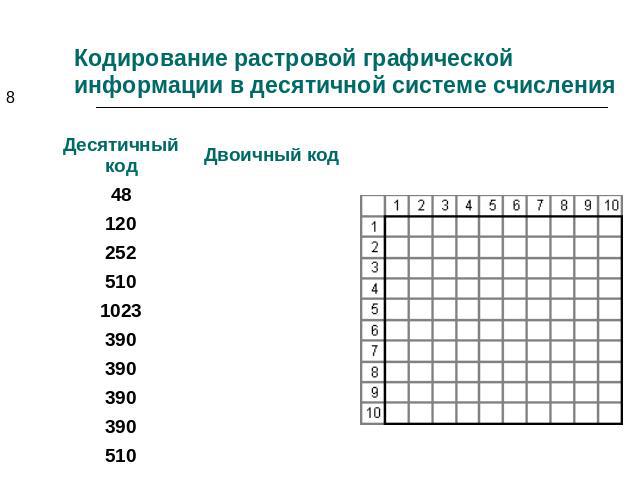
1.Дисциплины «Информатика»
Самостоятельная работа студентов
Перечень вопросов и заданий,
методические указания
Иркутск – 2010
Вопросы программы по информатике, которые должны быть подтверждены практическими навыками работы на компьютере (для зачета по информатике на I курсе)
1. Общие вопросы
1.1. Основные правила техники безопасности при работе на компьютере.
1.2. Включение и выключение компьютера.
2. Знакомство с Windows xp/nt
2.1.
Объекты WXP. Свойства
объектов. Использование контекстного
меню.
2.2. Ярлык объекта. Создание и использование ярлыков.
3. Настройка Windows xp/nt
3.1. Рабочий стол. Настройка рабочего стола. Кнопка «Пуск». Настройка панели задач.
3.2. Размещение ярлыков и объектов WXP на рабочем столе. Запуск программ.
3.4. Создание файлов и других объектов Windows.
3.3. Копирование и перемещение объектов. Буфер обмена. Обмен информацией между объектами Windows.
3.4. Настройки экрана: фон, рисунок, заставка, разрешение и др.
3.5. Установка и изменение драйвера видеокарты. Установка и изменение драйвера монитора. Установка и изменение драйверов других устройств.
3.6. Конфигурирование WXP при помощи конфигурирующих файлов DOS autoexec.bat и config.sys.
3.7. Основные конфигурационные файлы WXP. Использование программы sysedit для изменения конфигурации WXP.
3.8.
Восстановление реестра WXP
при отказе загрузки компьютера.
4. Стандартные программы wxp.
4.1. Проводник.
4.2. MS Paint. Создание рисунков. Захват изображений средствами WXP.
4.3. NotePad. Создание и сохранение текстовых документов.
4.6. WordPad. Создание и сохранение текстовых документов в различных форматах. Вставка рисунков и других объектов в текстовые документы. (На примере создания учебного реферата.)
4.8. Создание системного флоппи-диска.
Экзаменационные вопросы к программе курса «Информатика»
Информатика как наука. Происхождение информатики. Андре Мари Ампер. Норберт Винер. Что такое кибернетика? Определение информатики.
Виды информации. Непрерывная (аналоговая) и дискретная (цифровая) информация.
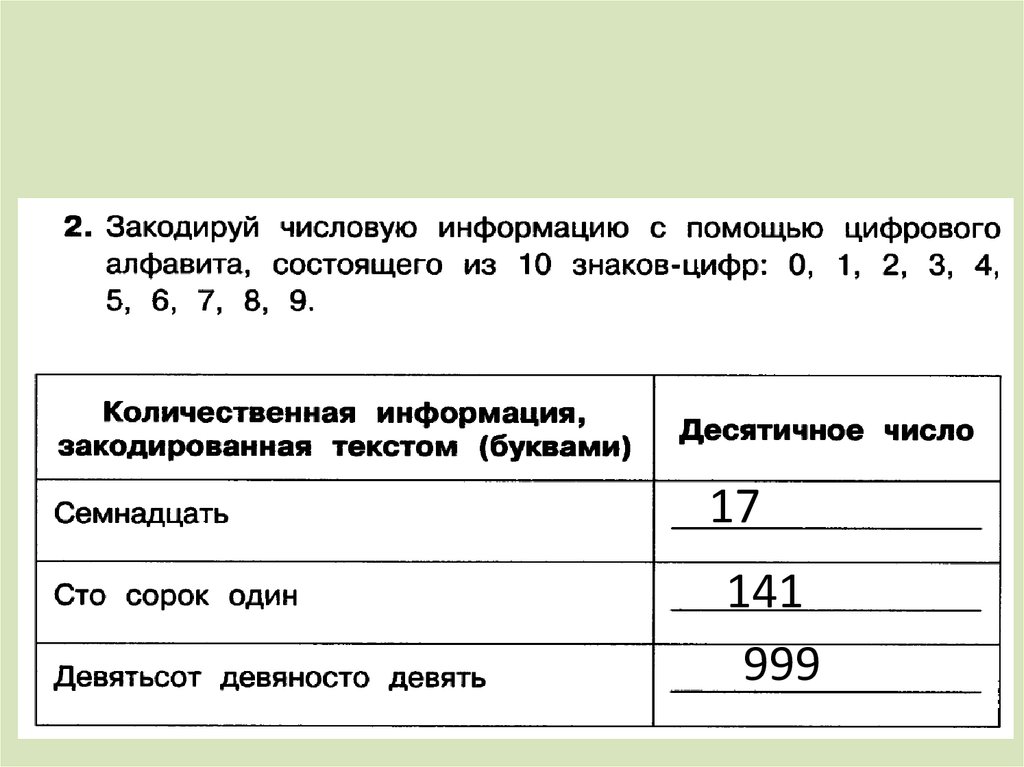
Кодирование информации.
АЦП. Погрешность оцифровки.Единица измерения информации. Бит. Системы счисления.
Переход от десятичной к двоичной системе счисления.
Сколько объектов можно закодировать n-битным двоичным числом (2n) ? Доказать.
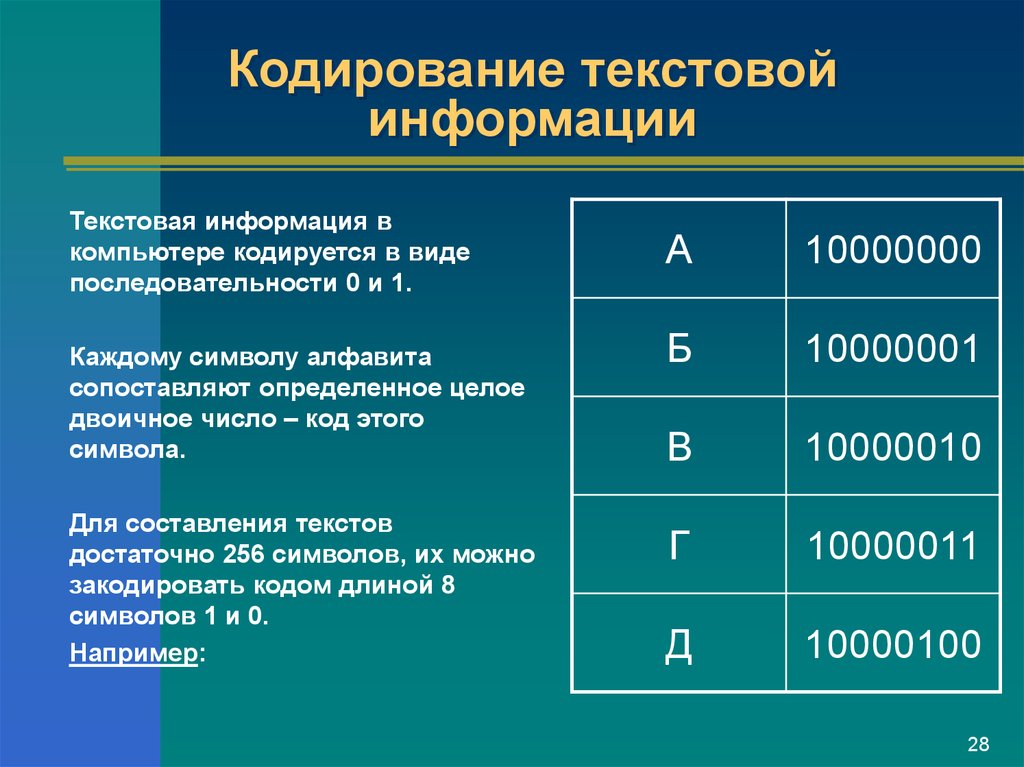
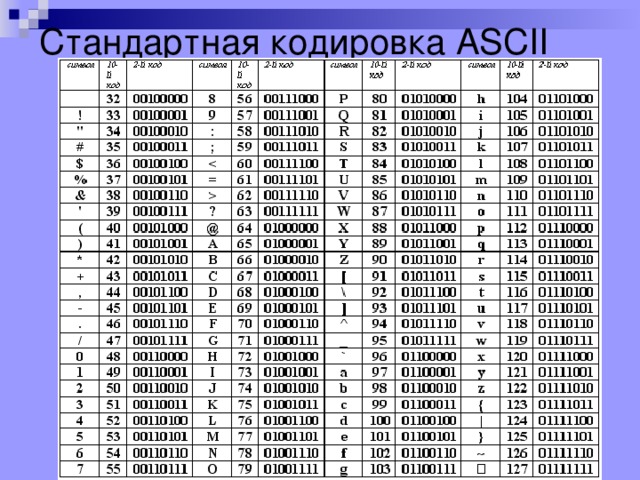
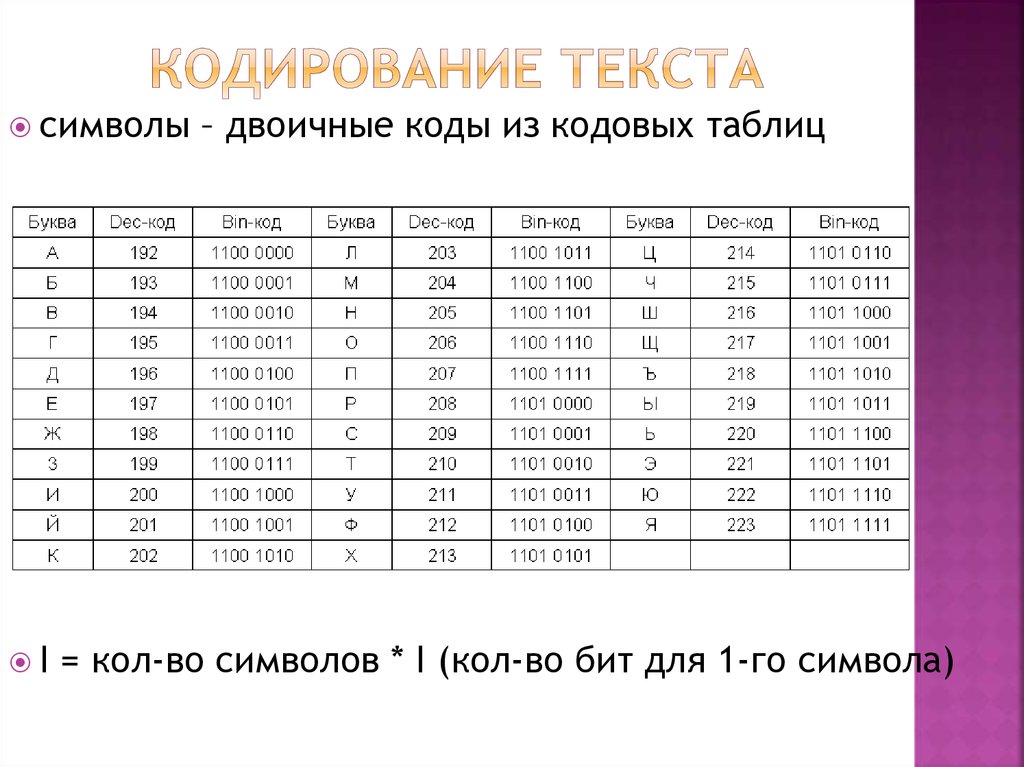
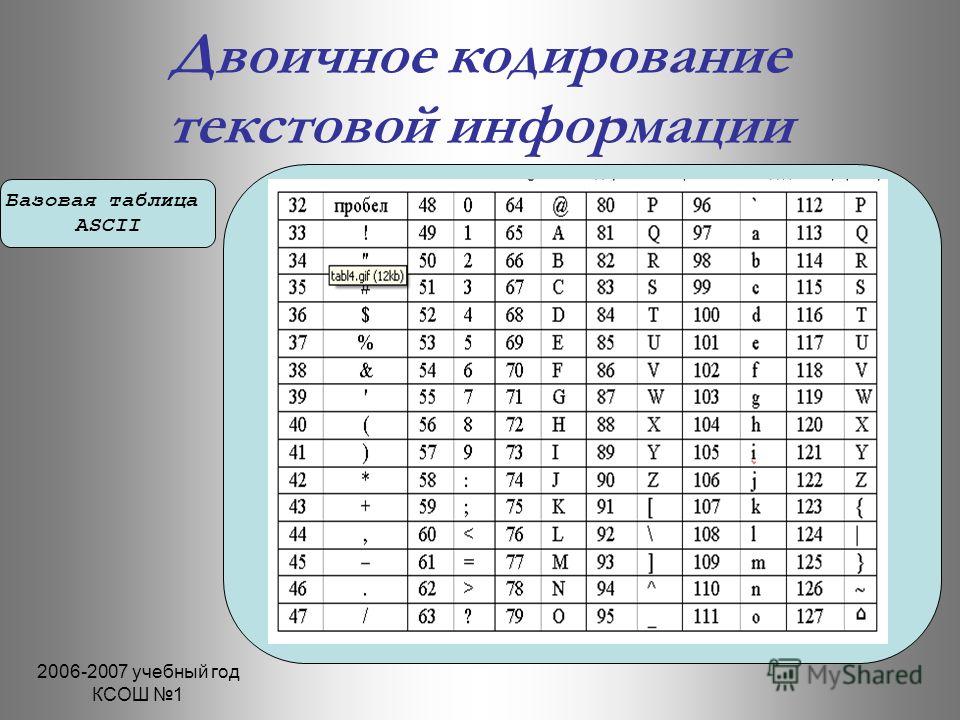
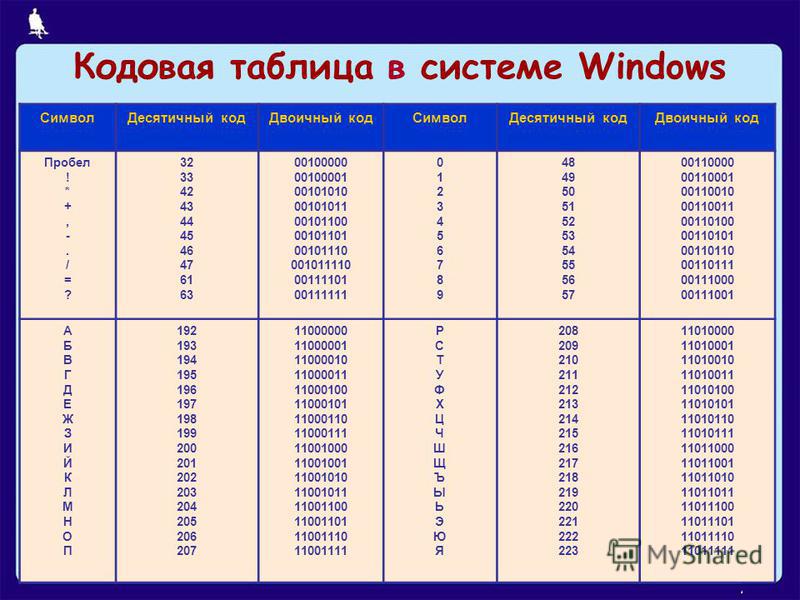
Байт. Кодирование текстовой информации. ASCII коды. Уникоды (unicode).
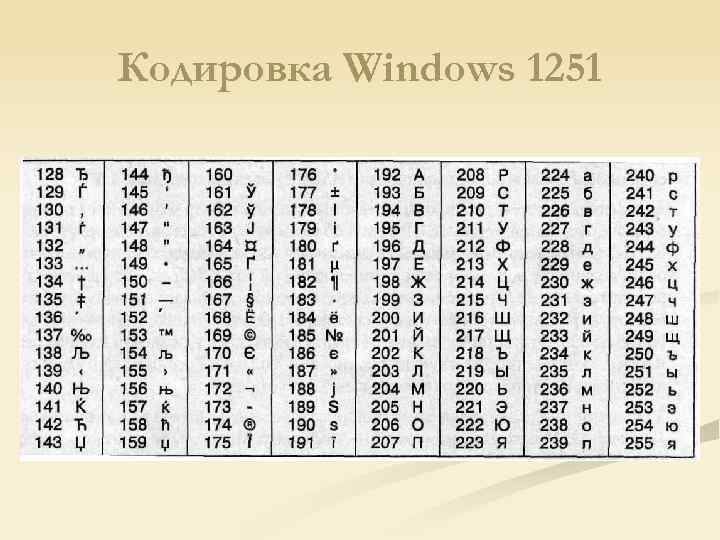
Кодировки кириллицы: ГОСТ и альтернативная (ОЕМ, СР-866, ДОС).
Кодировка Microsoft (СР-1251, Windows), ISO, КОИ-8.
Кодирование графической информации. Глубина цвета (разрешение): 8-, 16-, 24- и 32-битовые режимы.
Законы трехмерности, непрерывности и аддитивности Грассмана.
Аддитивная цветовая система (RGB).
Субстрактивная цветовая система (CMYK).
Цветовая модель HSB.
Регистрация информации. Файл. Имена и типы файлов. Форматы файлов.
Файловая структура.
Каталог.Персональный компьютер как инструмент переработки информации: устройства ввода информации, устройства вывода информации.
Состав компьютерной системы. Системный блок.
Процессор. Характеристики процессоров. Тактовая частота.
Модели процессоров (на примере процессоров фирмы Intel).
Процессоры Intel: Celeron, Pentium IV.
Системная шина. Стандарты системных шин.
Мониторы. Электронно-лучевые и жидкокристаллические экраны.
Техника безопасности при работе за дисплеем. Экранные фильтры.
Текстовый режим. Графический режим. Разрешающая способность, размер точки экрана и некоторые другие параметры монитора.
Видеокарта. Скорость работы и видеопамять. Качество изображения.
Клавиатура. Ввод заглавных и строчных букв. Кодовые наборы. Основная, альтернативная, koi8-r и некоторые другие кодировки кириллицы.
Уникоды.Специальные клавиши клавиатуры. Ввод символов, не предусмотренных для прямого ввода с клавиатуры.
Особые («горячие») комбинации клавиш.
Другие периферийные устройства. Принтеры. Ручные манипуляторы (координатные устройства). Мышь. Джойстик. Трэкобол. Флэш-карты. Устройства ввода изображений. Сканер.
Коммуникационное оборудование. Модемы. Аудиоплата.
Техника безопасности и некоторые другие правила работы на компьютере.
Программный и аппаратный интерфейсы.
Оперативная память ПК. Объем ОП. Регенерация ОП. Адрес.
Хранение информации на внешних носителях. Накопители на магнитной ленте — стриммеры. Накопители на гибких магнитных дисках (НГМД / FDD).
Структура данных на ГМД. Дорожка. Сектор. Кластер. Размер кластера.
Накопители на жестких магнитных дисках (НЖМД / HDD).
Размещение файлов на ЖМД (HD). Таблица размещения файлов (FAT).
Расчет размера кластера в FAT 16. FAT 32 для разных объемов ЖМД (HD). Файловая система NTFS.
Логические диски. Обозначения накопителей буквами латинского алфавита.
Лазерные компакт-диски (CD ROM). Накопители на CD ROM. Принцип действия CD-R и CD-RW.
Принцип записи на DVD. Новые стандарты цифрового видео и звука. Плотность записи. Многослойные диски. Основные отличия от записи на обычных CD-R.
Операционные системы. История развития операционных систем. MS DOS (версии MS DOS), Windows’9x/XP, OC/2, UNIX.
Основные компоненты операционной системы (на примере MS DOS).
Введение в Windows. Работа с Windows.
Управление внешними устройствами. Понятие драйвера. Драйверы стандартных устройств. Драйверы дополнительных устройств. Понятие о Plug & Play (подключи и работай).
Взаимодействие пользователя с операционной системой. Процессор командного языка.
Приглашение DOS. Командная строка. Ввод команд. Запуск и выполнение команд. Переадресация потоков информации.
Действия при зависании компьютера и при неправильной работе программ.
Удаление файлов. Копирование файлов. Поиск файла на диске. Вывод файла на экран (печать).
Вывод информации о дате/времени и установка даты/времени в компьютере средствами ДОС.
Конфигурирование системы. Файлы autoexec.bat, config.sys и их аналоги.
Обзор версий MS Windows. Основные отличия Windows 9x от Windows XP. Значение MS Windows. Преимущества и недостатки.
Шрифты Windows. Растровые шрифты. Масштабируемые шрифты. Моноширинные и пропорциональные шрифты.
Настройка Windows. Панель управления Windows. Запуск панели управления. Окно панели управления.
Объекты WindowsXP. Свойства объектов. Доступ к свойствам объектов через контекстное меню.
Требования к ПК, предъявляемые WindowsXP. Загрузка WindowsXP.
Изучение возможностей WindowsXP. Многозадачный режим и многопоточная обработка данных.
Файловая система. Длинные имена файлов. Совместимость с DOS. Стандартные программы WindowsXP.
Интерфейс WindowsXP. Использование мыши. Работа с окнами. Исследование составляющих частей окна. Перемещение окна. Изменение размеров окна. Использование меню. Использование панели инструментов.
Рабочий стол WindowsXP. Ярлыки объектов и их создание. Использование контекстного меню.
Изменение установок экрана. Установка фона и заставки. Установка цветовой гаммы и шрифтов рабочего стола. Изменение параметров дисплея.
Главное меню и панель задач. Настройка и редактирование главного меню.
Перемещение
панели задач.Изучение и использование проводника. Открытие, переименование, просмотр свойств объектов в окне проводника. Сканирование, дефрагментирование, форматирование и установка метки диска.
Открытие и использование папок. Управление папками. Создание новых папок. Копирование, перемещение и удаление объектов.
Панель управления. Инсталляция и деинсталляция программ. Установка даты, времени и некоторых других параметров.
Установка оборудования на примере установки монитора, видеокарты и принтера.
Стандартные программы, поставляемые в комплекте с Windows. Использование программы REGEDIT для получения текстовой копии реестра и его корректировки.
Графический редактор Paintbrush (MS Paint). Захват изображения с экрана и редактирование его в Paint.
Текстовый редактор WordPad. Назначение редактора WordPad. Вход в редактор WordPad.
Экран WordPad.
Ввод текста. Перемещение по тексту.
Простейшая коррекция. Поиск и замена
символов. Корректировка текста.Форматирование символов и абзацев. Меню WordPad. Установка шрифтов. Выделение фрагмента текста. Загрузка и запись текста в память. Включение в текст рисунка.
FAR-менеджер — дополнительные возможности для работы в Windows XP: поддержка длинных имен файлов, встроенный FTP-клиент.
Методы архивации RLE и Хаффмана. Необходимость архивации файлов. Сжатие дисков.
Архиваторы WinZip, WinRAR, 7Zip. Помещение файлов в архив. Извлечение файлов из архива. Архивация на дискеты. Многотомные архивы.
Самораспаковывающиеся архивы. Архивация конфиденциальной информации. Дополнительные возможности при архивации файлов. Методика архивации. Рекомендации по использованию программ архивации.
Основные методы защиты от компьютерных вирусов. Программы-детекторы и доктора.
Действия
при заражении вирусом. Профилактика
против заражения вирусом.Microsoft Office. MS Word. Многофункциональная оболочка MS Word. Строка заголовка. Строка меню. Диалоговое окно. Инструментальная панель. Окно документа. Полосы прокрутки документа. Строка состояния. Помощь. Настройка MS Word.
MS Word. Функции клавиатуры. Набор текста. Вставка символов. Автозамена. Автотекст.
Форматы файлов. Загрузка файлов различных форматов. Проверка орфографии и грамматики разноязычных документов. Тезаурус. Перенос. Редактирование текста. Сохранение документа в различных форматах.
Выделение фрагмента текста. Удаление, копирование и перемещение фрагментов текста. Просмотр буфера обмена. Поиск и замена цепочки символов.
Форматирование текста. Форматирование абзацев. Различные стили форматирования. Создание и изменение стиля форматирования. Создание и использование шаблонов. Верхние и нижние колонтитулы.
Сноски.MS Word. Работа с рисунками и таблицами. Вставка рисунков и других объектов в документ методами внедрения и связывания.
Создание таблиц. Использование таблиц для форматирования документа. Границы и заливка таблиц. Корректура. Отметка исправляемых мест. Принять или удалить исправления.
Создание оглавления, списка терминов. Перемещение по документу с помощью оглавления. Параметры печати. Предварительный просмотр страниц. Распечатка документа.
MS Word. MS Draw. MS Graph Equation. MS WordArt.
История развития электронных таблиц. Краткий обзор возможностей EXCEL.
EXCEL. Передвижение по таблице. Ввод данных. Выравнивание содержимого ячеек. Ширина колонки и высота строки. Выделение полей и областей. Заполнение, копирование и перенос. Форматы чисел. Построение и ввод формул. Операции в формулах.
EXCEL. Работа с графиками и диаграммами.
Компьютерные сети. Локальные сети.
Интернет. Создание удаленного соединения. Сетевое имя. Пароль.
Основные понятия World Wide Web. URL и IP адреса. Доменная структура. Сервер. HTTP, FTP и некоторые другие протоколы в интернет.
Работа с браузерами Internet Explorer, Opera, ThunderBird. Поиск информации в интернет. Создание указателей (закладок) на наиболее интересные сайты.
Копирование (закачка) информации из интернет. Загрузчик DownloadMaster.
Электронная почта в интернет. HTTP и текстовый форматы почтовых сообщений.
Web почта. Получение почтового ящика. РОР-почта. Подписка на получение новостей.
Почтовые программы на примере Outlook Express. Создание учетных записей и другие установки почты. Работа с адресной книгой.
Наиболее известные серверы, позволяющие получить бесплатный почтовый ящик и место для публикации Web-страниц.
 АЦП. Погрешность оцифровки.
АЦП. Погрешность оцифровки. Каталог.
Каталог. Уникоды.
Уникоды.


 Перемещение
панели задач.
Перемещение
панели задач. Экран WordPad.
Ввод текста. Перемещение по тексту.
Простейшая коррекция. Поиск и замена
символов. Корректировка текста.
Экран WordPad.
Ввод текста. Перемещение по тексту.
Простейшая коррекция. Поиск и замена
символов. Корректировка текста.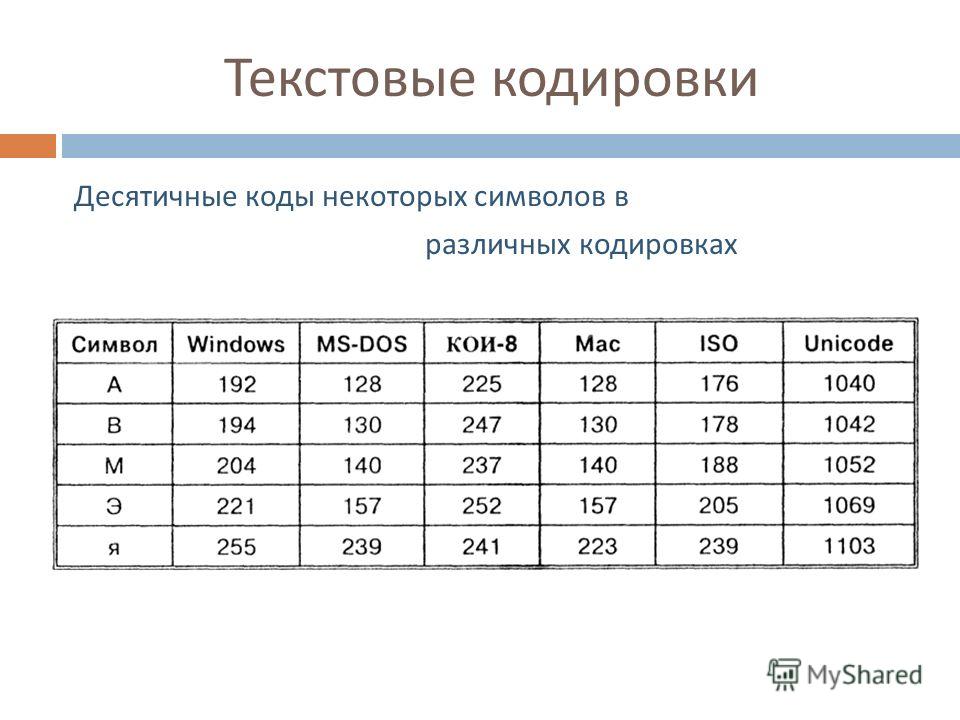 Действия
при заражении вирусом. Профилактика
против заражения вирусом.
Действия
при заражении вирусом. Профилактика
против заражения вирусом. Сноски.
Сноски.
swift-String возвращает неправильные значения. 33,48 становится 33,47999999999999488
Задавать вопрос
спросил
Изменено 1 год, 9 месяцев назад
Просмотрено 245 раз
Я пытаюсь создать хэш объекта give после преобразования его в строку в swift, но значения, закодированные в строке, отличаются.
печать (myObjectValues.v) // 33.48
пусть mydata = попробуйте JSONEncoder (). encode (myObjectValues)
пусть строка = строка (данные: mydata, кодировка: .utf8)!
печать (строка) // 33.47999999999999488
Здесь в myObjectValues содержится десятичное значение 33,48. Если я попытаюсь закодировать эти мои данные в строку, возвращаемое значение равно 33,479. 99999999999488. Я пытался округлить десятичное значение до 2 знаков, но в последней строке остается это число. Я пытался сохранить его в String, а затем обратно в Decimal, но значение, возвращаемое в закодированной строке, равно 33.479999999.
99999999999488. Я пытался округлить десятичное значение до 2 знаков, но в последней строке остается это число. Я пытался сохранить его в String, а затем обратно в Decimal, но значение, возвращаемое в закодированной строке, равно 33.479999999.
Я не могу использовать эту строку для расчета и сравнения хэша, так как хеш-значение, возвращаемое сервером, равно 33,48, что никогда не будет равно тому, что я получу на своем конце с этим длинным значением.
- свифт
- кодирование
- jsondecoder
- json-сериализация
7
Значения Decimal , созданные с базовыми значениями Double , всегда будут создавать эти проблемы.
Десятичные значения , созданные с базовыми значениями String , не будут создавать эти проблемы.
То, что вы можете попробовать сделать, это —
- Иметь частное значение
Stringв качестве резервного хранилища, предназначенного только для безопасного кодирования и декодирования этого десятичного значения. - Предоставьте другое вычисленное значение
Decimal, которое использует это базовое значениеString.
импортный фонд
Тест класса: кодируемый {
// Недоступно: только для кодирования и декодирования.
частная переменная decimalString: String = "33,48"
// Работайте с этим в своем приложении
переменная десятичная: десятичная {
получать {
Десятичный (строка: decimalString) ?? .нуль
}
набор {
десятичное = новое значение
десятичная строка = "\(новое значение)"
}
}
}
делать {
пусть закодировано = попробуйте JSONEncoder(). encode(Test())
печать (строка (данные: закодированы, кодировка: .utf8))
// Опционально("{\"decimalString\":\"33,48\"}")
let decoded = попробуйте JSONDecoder().decode(Test.self, from: encoded)
печать (декодированный.десятичный) // 33.48
print(decoded.decimal.nextUp) // 33.49print(decoded.decimal.nextDown) // 33. 47
} ловить {
распечатать (ошибка)
}
 47
} ловить {
распечатать (ошибка)
}
47
} ловить {
распечатать (ошибка)
}
2
Я пытаюсь создать хэш объекта give после преобразования его в строку в swift, но значения, закодированные в строке, отличаются.
Не делай этого. Просто не надо. Это неразумно.
Поясню по аналогии: представьте, что вы представляете числа с точностью до шести знаков после запятой. Вы должны использовать некоторую точность, верно?
Теперь 1/3 будет представлена как 0.333333 . Но 2/3 будет представлено 0,666667 . Так что теперь, если вы умножите 1/3 на два, вы не получите 2/3. И если вы прибавите 1/3 к 1/3 к 1/3, вы не получите 1.
Таким образом, хэш 1 будет отличаться в зависимости от того, как вы получили эту 1! Если вы добавите 1/3 к 1/3 к 1/3, вы получите другой хэш, чем если бы вы добавили 2/3 к 1/3.
Это просто неподходящий тип данных для хеширования. Не используйте двойники для этой цели.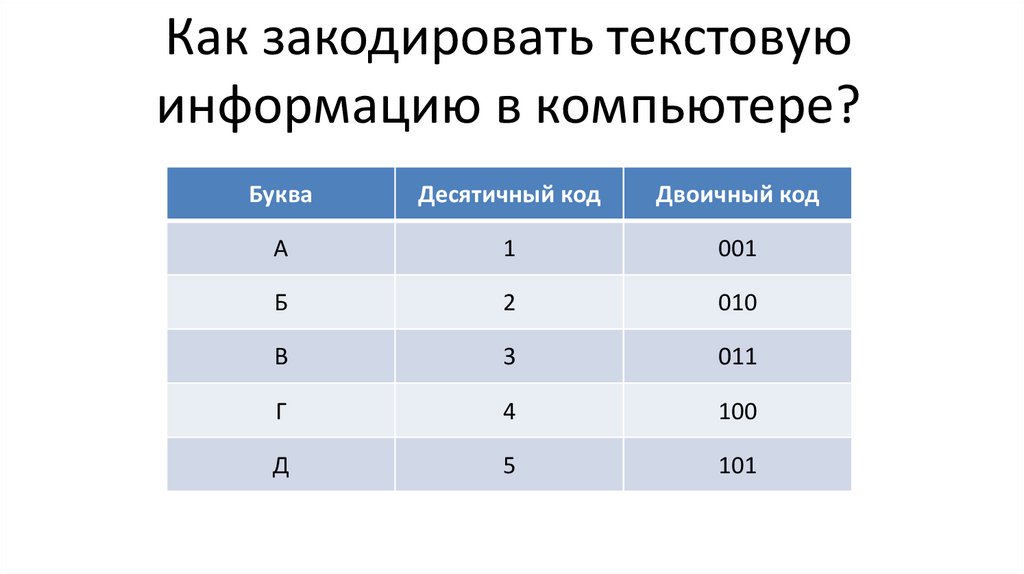 Округление будет работать, пока не перестанет.
Округление будет работать, пока не перестанет.
И вы используете 33 + 48/100 — значение, которое не может быть точно представлено в системе счисления два так же, как 1/3 не может быть точно представлено в системе счисления десять.
4
python — Проверить, является ли строка шестнадцатеричной
спросил
Изменено 1 год, 1 месяц назад
Просмотрено 142к раз
Я знаю, что проще всего использовать регулярное выражение, но мне интересно, есть ли другие способы сделать эту проверку.
Зачем мне это? Я пишу скрипт Python, который читает текстовые сообщения (SMS) с SIM-карты. В некоторых ситуациях приходят шестнадцатеричные сообщения, и мне нужно выполнить для них некоторую обработку, поэтому мне нужно проверить, является ли полученное сообщение шестнадцатеричным.
Когда я отправляю следующее SMS:
Привет, мир!
И мой скрипт получает
00480065006C006C006F00200077006F0072006C00640021
Но в некоторых ситуациях я получаю обычные текстовые сообщения (не шестнадцатеричные). Поэтому мне нужно сделать , если шестнадцатеричное управление .
Я использую Python 2.6.5.
ОБНОВЛЕНИЕ:
Причина этой проблемы в том, что (каким-то образом) сообщения, которые я отправил, принимаются как hex , а сообщения, отправленные оператором (информационные сообщения и объявления), принимаются как обычная строка. Поэтому я решил проверить и убедиться, что у меня есть сообщение в правильном формате строки.
Некоторые дополнительные сведения : Я использую 3G-модем Huawei и PyHumod для чтения данных с SIM-карты.
Возможное лучшее решение для моей ситуации:
Лучший способ обработки таких строк-это использование A2B_HEX (a.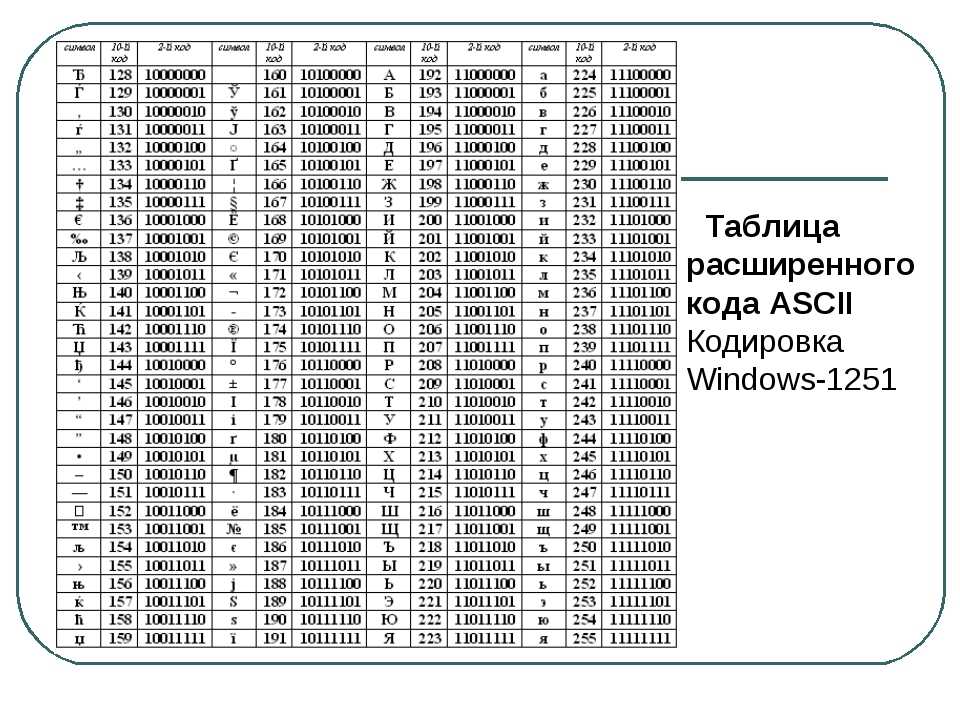 k.a.
k.a. Uncexlify ) и UTF-16-Endian Encoding (ASJJ-@JJ @Jj.
from binascii import unhexlify # unhexlify — это другое имя a2b_hex
mystr = "00480065006C006C006F00200077006F0072006C00640021"
unhexlify(mystr).encode("utf-16-be")
>> Привет, мир!
- питон
- шестнадцатеричный
4
(1) Использование int() отлично подходит для этого, и Python делает всю проверку за вас 🙂 6896377547970387516320582441726837832153446723333914657L
подойдет. В случае сбоя вы получите исключение ValueError .
Краткий пример:
интервал('аф', 16)
175
интервал('а', 16)
...
ValueError: неверный литерал для int() с основанием 16: 'ах'
(2) Альтернативой будет просмотр данных и проверка того, что все символы попадают в диапазон 0..9 и a-f/A-F . string. ( 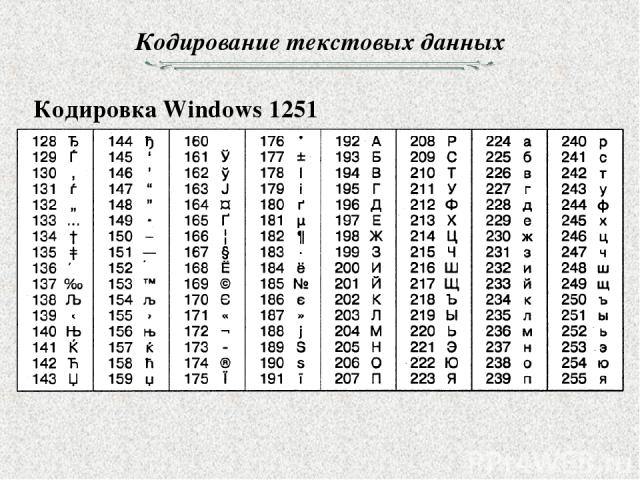 hexdigits
hexdigits '0123456789abcdefABCDEF' ) полезен для этого, поскольку он содержит как цифр в верхнем, так и в нижнем регистре.
строка импорта все (c в строке.hexdigits для c в s)
вернет либо True , либо False в зависимости от достоверности ваших данных в строке s .
Краткий пример:
s = 'af' все (c в строке.hexdigits для c в s) Истинный с = 'а' все (c в строке.hexdigits для c в s) ЛОЖЬ
Примечания :
Как правильно отмечает @ScottGriffiths в комментарии ниже, подход int() будет работать, если ваша строка содержит 0x в начале, в то время как посимвольная проверка не удастся с этим . Кроме того, проверка против набор символов быстрее, чем строка символов, но сомнительно, что это будет иметь значение с короткими строками SMS, если только вы не обработаете многие (многие!) из них последовательно, и в этом случае вы можете преобразовать stringhexditigs в набор с набор(строка. .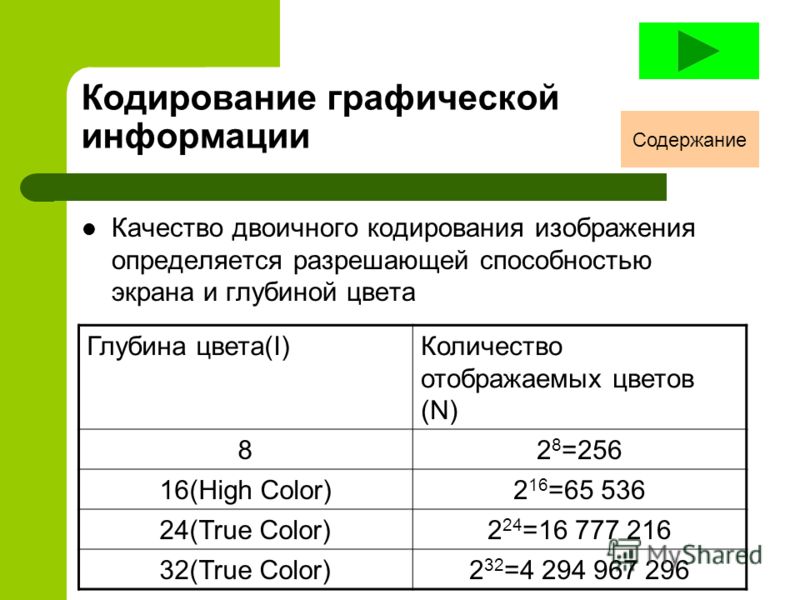 шестнадцатеричные цифры)
шестнадцатеричные цифры)
4
Вы можете:
- проверить, содержит ли строка только шестнадцатеричные цифры (0…9,A…F)
- попробуйте преобразовать строку в целое число и посмотрите, не получится ли.
Вот код:
строка импорта
определение is_hex(s):
hex_digits = набор (строка.hexdigits)
# если s длинное, то быстрее сверяться с набором
вернуть все (c в hex_digits для c в s)
определение is_hex(s):
пытаться:
интервал (ы, 16)
вернуть Истина
кроме ValueError:
вернуть ложь
12
Я знаю, что оператор упоминал регулярные выражения, но я хотел внести такое решение для полноты картины: 9[0-9a-fA-F]$», s или «») не равно None
Производительность
Чтобы оценить производительность различных предложенных здесь решений, я использовал модуль Python timeit.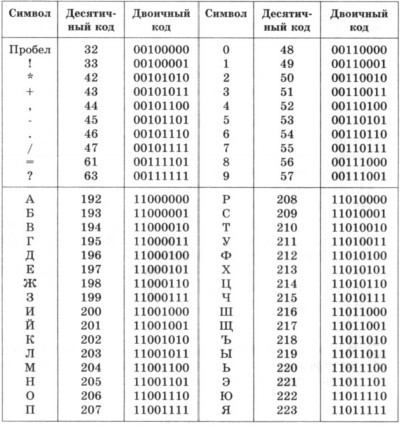 Входные строки генерируются случайным образом для трех разных длин:
Входные строки генерируются случайным образом для трех разных длин: 10 , 100 , 1000 :
s=''.join(random.choice('0123456789abcdef') for _ in range(10))
Решения Левона:
# int(s, 16) 10: 0,257451018987922 100: 0,4008169[0-9a-fA-F]$', s или '') 10: 0,725040541990893 100: 0,7184272820013575 1000: 0,7190397029917222
Таким образом, выбор правильного решения зависит от длины входной строки и возможности безопасной обработки исключений. Регулярное выражение, безусловно, обрабатывает большие строки намного быстрее (и не выдает ValueError при переполнении), но int() является победителем для более коротких строк.
3
Еще одно простое и короткое решение, основанное на преобразовании строки в множество и проверке подмножества (не проверяет префикс ‘0x’):
строка импорта
защита is_hex_str(s):
набор(ы) возврата. issubset(string.hexdigits)
 issubset(string.hexdigits)
issubset(string.hexdigits)
Подробнее здесь.
1
Другой вариант:
def is_hex(s):
hex_digits = набор ("0123456789abcdef")
для char в s:
если нет (char в hex_digits):
вернуть ложь
вернуть Истина
Большинство решений, предложенных выше, не учитывают, что любое десятичное целое число может быть также декодировано как шестнадцатеричное, потому что набор десятичных цифр является подмножеством набора шестнадцатеричных цифр. Так что Python с радостью возьмет 123 и предположим, что это 0123 hex:
>>> int('123',16)
291
Это может показаться очевидным, но в большинстве случаев вы будете искать что-то, что на самом деле было закодировано в шестнадцатеричном формате, например. хэш, а не что-то, что может быть шестнадцатерично декодировано. Поэтому, вероятно, более надежное решение должно также проверять четную длину шестнадцатеричной строки:
В [1]: def is_hex(s): .
 ..: пытаться:
...: целое (ы, 16)
...: кроме ValueError:
...: вернуть ложь
...: вернуть len(s) % 2 == 0
...:
В [2]: is_hex('123')
Выход[2]: Ложь
В [3]: is_hex('f123')
Выход[3]: Истина
..: пытаться:
...: целое (ы, 16)
...: кроме ValueError:
...: вернуть ложь
...: вернуть len(s) % 2 == 0
...:
В [2]: is_hex('123')
Выход[2]: Ложь
В [3]: is_hex('f123')
Выход[3]: Истина
Это относится к случаю, когда строка начинается с ‘0x’ или ‘0X’: [0x|0X][0-9a-fA-F]
d='0X12a' все (c в 'xX' + string.hexdigits для c в d) Истинный
1
В Python3 я пробовал:
def is_hex(s):
пытаться:
tmp=bytes.fromhex(hex_data).decode('utf-8')
return ''.join([i for i in tmp if i.isprintable()])
кроме ValueError:
возвращаться ''
Должно быть лучше так: int(x, 16)
1
Используя Python, вы хотите определить True или False, я бы использовал метод is_hex eumero, а не метод Levon one. Следующий код содержит ошибку…
if int(input_string, 16):
напечатать 'это шестнадцатеричный'
еще:
напечатать 'это не шестнадцатеричный'
Строка ’00’ ошибочно сообщается как , а не в шестнадцатеричном формате, поскольку ноль оценивается как False.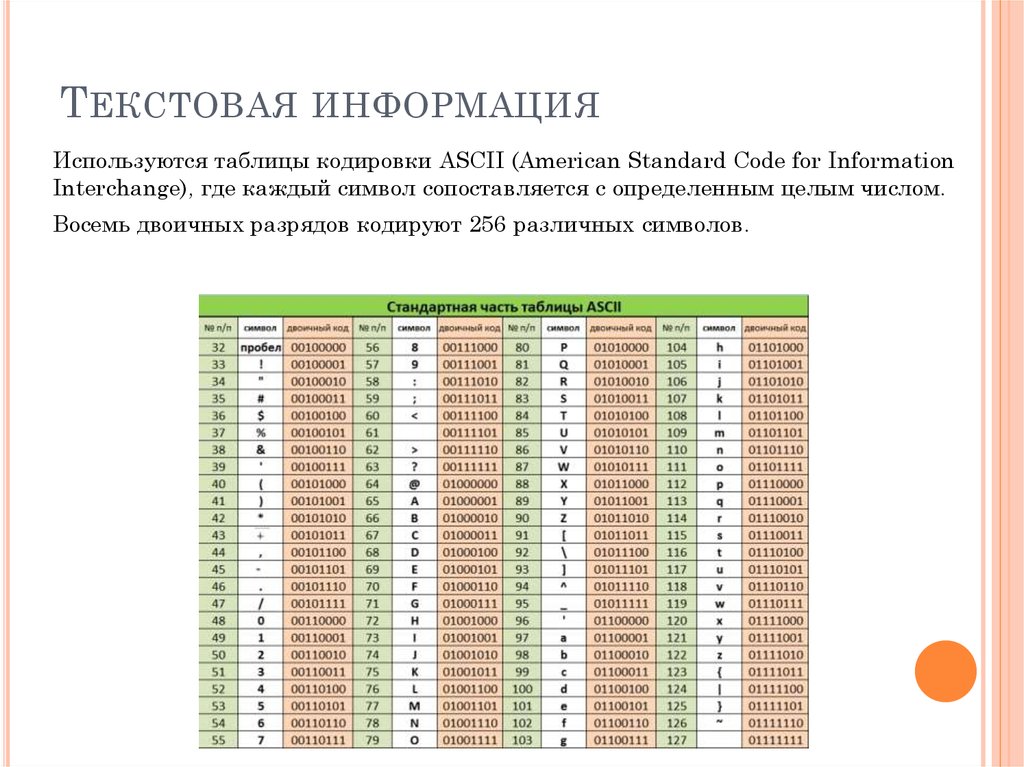
Поскольку все приведенные выше регулярные выражения заняли примерно одинаковое количество времени, я предполагаю, что большая часть времени была связана с преобразованием строки в регулярное выражение. Ниже приведены данные, которые я получил при предварительной компиляции регулярного выражения.
int_hex 0,000800 мс 10 0,001300 мс 100 0,008200 мс 1000 all_hex 0,003500 мс 10 0,015200 мс 100 0,112000 мс 1000 fullmatch_hex 0,001800 мс 10 0,001200 мс 100 0,005500 мс 1000
Простое решение, если вам нужен шаблон для проверки шестнадцатеричного или двоичного префикса вместе с десятичным числом
\b(0x[\da-fA-F]+|[\d]+|0b[01]+)\b
Образец: https://regex101.com/r/cN4yW7/14
Затем выполните int('0x00480065006C006C006F00200077006F0072006C00640021', 0) в питоне дает
6896377547970387516320582441726837832153446723333914657
Основание 0 вызывает угадывание префикса. Это избавило меня от многих хлопот. Надеюсь, поможет!
Большинство решений неправильно проверяют строку с префиксом 0x
>>> is_hex_string("0xaaa")
ЛОЖЬ
>>> is_hex_string("0x123")
ЛОЖЬ
>>> is_hex_string("0xfff")
ЛОЖЬ
>>> is_hex_string("fff")
Истинный
Вот мое решение:
по определению to_decimal(s): '''ввод должен быть int10 или hex''' isString = isinstance(s, str) если это строка: isHex = all (c в string.

Leave A Comment