
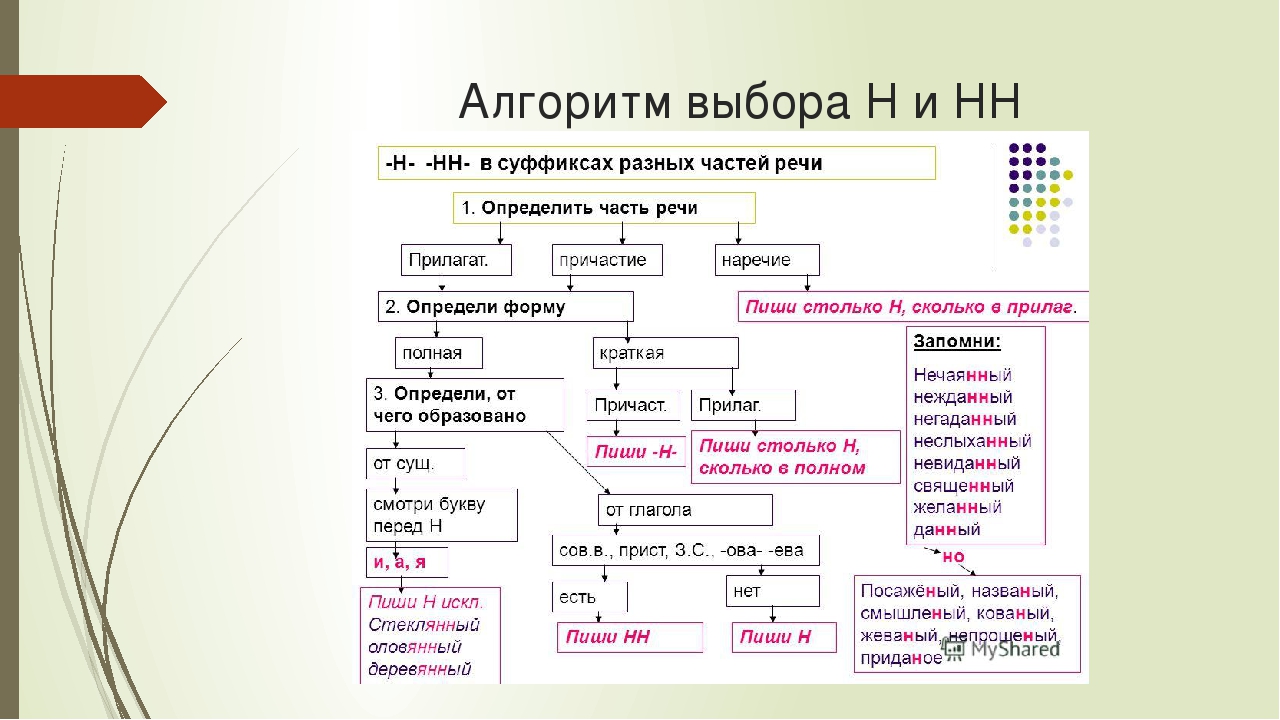
Упражнения по теме «Правописание Н и НН в разных частях речи»Упражнение 1. Запишите прилагательные, вставляя -н- или -нн-. Образуйте от них наречия. Составьте с наречиями словосочетания. Какие из образованных наречий можно употребить в переносном значении. Дисциплинирова…ый, ветре…ый, време…ный, тума…ый, открове…ый, дружелюб…ый, мужеств…ый, вниматель…ый, удивле…ый.
Упражнение 2. Образуйте от имен существительных прилагательные, расположите их в алфавитном порядке. Поставьте в словах ударения. Земля, трава, кость, ремесло, обед, топор, слюда, кожа, полотно, торжество, правительство, единство, государство, отечество, огонь, глина, солома, тыква, клюква, береста, вода, жесть, лед, лен, песок, дерево, рожь, серебро, шерсть, маневры.
Упражнение 3. От полных причастий образуйте краткие причастия мужского, женского, среднего родов. Подчеркните суффиксы причастий. Запакованный, устроенный, выкрашенный, построенный, закутанный, проложенный, выкроенный, отделенный, выделенный.
Упражнение 4. Н или НН? Спишите причастия и прилагательные, подбирая к ним подходящие по смыслу слова. Глаже…ая, разреза…ые, выглаже…ая, разреза…ые, ноше…ая, суше…ые, удлине…ая, сорва…ые, стира…ая, краше…ая, мороже…ые, вяза…ая.
Упражнение 5. Спишите, подчеркните и объясните правописание н или нн. Жареный гусь, поджаренная колбаса, жаренные в масле пирожки, писаный красавец, вписанный треугольник, писанный художником, организованная спонсорами ярмарка, тканая скатерть, тканная золотом скатерть, забракованные товары, военизированный отряд, воспитанный человек, дистиллированная вода, расклеенные афиши, дисквалифицированный спортсмен, незваный гость, связанный пленник, завербованный агент, сделанная надпись, варенный в мундире картофель, купленные в магазине вещи.
Упражнение 6. Перепишите, вставляя пропущенные буквы. Объясните правописание н и нн в причастиях и отглагольных прилагательных. Балова…ый ребенок, замаскирова…ый вход, плете…ая корзина, измуче…ый вид, груж…ая дровами машина, груже…ая машина, нагруже…ая машина, стреля…ая дичь, неслыха…ые обстоятельства, ране…ый в руку солдат, гаше…ая известь, негаше…ая известь, назва…ый брат, моще…ая дорога, писа…ые акварелью картины, ране…ый боец, переплавле…ый металл, асфальтирова…ая улица, посоле…ая закуска, ноше…ая шляпа, поноше…ые ботинки, оплете…ый плющом забор, взволнова…ый разговор, броше…ый камень, нечая…ая встреча, купле…ый товар, отправле…ое по факсу письмо, изыска…ые экономистами ресурсы, застрахова…ое имущество, непредвиде…ые обстоятельства, оказать вооруже…ое сопротивление, довере…ое лицо, дипломирова…ый специалист.
Упражнение 7. Спишите, вставляя пропущенные Н или НН ( 1 вариант). Составьте именные словосочетания. 1) Подоко_ик, избалова_ый, медле_ый, свяще_ый, масля_ый, сея_ый, задушев_ость, вселе_ая, покло_ик, мороже_ое, стреля_ый, трансляцио_ый, революцио_ый, ваго_ый, ши_ый, дарстве_ая, операцио_ая, чи_ый, райо_ый, миллио_ый, жарго_ый, осли_ый, соколи_ый, змеи_ый, лицензио_ый, слоё_ый, она вполне совреме_а. 2) Наив_ость, пода_ый, полуобразова_ый, жела_ый, нечая_ый, конопля_ый, вея_ый, ю_ый, апелляцио_ый, эволюцио_ый, коллекцио_ый, пого_ый, благочи_ый, рути_ый, суко_ый, сезо_ый, пятиалты_ый, фурго_ый, орли_ый, со_ик, пчели_ый, диверсио_ый, пода_ый, пенсио_ый, топлё_ый, подчине_ый, девочка избалова_а.
Упражнение 8. Дайте толкование подчеркнутых слов. Выпишите существительные, образованные путем перехода из одной части речи в другую. Превратите Н в НН при помощи приставок. Образец: жареная – пережаренная Точеный, крученый, моченый, толченый, гашеный, пареный, кошеный, вязаный, крашеный, тушеный, соленый, давленый, сушеный, золоченый, званый, печеный.
Упражнение 9. Превратите Н в НН при помощи зависимых слов. Образец: жареная рыба – жаренная на сковородке рыба Мощеная дорога, плетеная шляпа, мороженые ягоды, крашеные стены, беленый потолок, соленый огурец.
Упражнение 10. Спишите, вставляя Н или НН, распределяя их в две колонки. Разберите по составу выделенные причастия.
Освеще_ая площадка, рассея_ый ученик, приведе_ый пример, купле_ый товар, ране_ый боец, краше_ая блондинка, перекраше_ые стены, некраше_ый пол, организова_ая спонсорами, рва_ая куртка, оторва_ый рукав, лома_ая линия, слома_ая игрушка, встревожа_ый известием, исправле_ая ошибка, реза_ая рана, подреза_ые деревья. Рассортирова_ый, суше_ый, подсуше_ый, полирова_ый, туше_ый, оглуше_ый, точе_ый, подточе_ый, туше_ый в гусятнице, травмирова_ый, глаже_ый, фарширова_ый, посеребре_ый, кале_ый, раскроше_ый, реза_ый, размассирова_ый, маза_ый, крошеч_ый.
Упражнение 11. От полных причастий образуйте краткие причастия мужского, женского и среднего рода. Собранные улитки, затоптанный ковер, сожженные свечи, найденный капкан, закопанный клад, затопленная печь, освещенный? коридор, порабощенный народ, освобожденная страна, засушенный гербарий, выброшенные на ветер деньги, купленный билет, связанный свитер, разработанный план, украшенная елка?, оставленный замок, загнанные лошади.
Упражнение 12. Объясните различия в написании созвучных слов. 1) Девочка хорошо воспитана родителями. Девочка послушна и воспитанна. 2) Встреча выпускников нашей школы была организована и в этом году. 3) Грозовая туча была рассеяна ветром, и снова засверкало солнце. Ты вчера была рассеянна, когда говорила со мной.
Упражнение 13. Замените придаточные предложения причастными оборотами. Образец. Возьми в дорогу чемодан, который я принес тебе вчера. — Возьми в дорогу чемодан, принесенный мною тебе вчера. 1) Все заинтересовались докладом по нанотехнологии, который был сделан профессором. 2) На полях, которые были засеяны кукурузой, показались всходы. 3) В квартире, которая недавно освободилась, устроили ремонт. 4) Мы отдыхали в беседке, которую нашли в конце аллеи.
Упражнение 14. Перестройте словосочетания в предложения со сказуемым — кратким причастием или прилагательным. Перепишите и подчеркните н или нн. Образец: реш…ная задача — задача решена. Выращ…ные овощи, законч…ная дискуссия, утер…ная расписка, своеврем…ная помощь, прекрасно сыгр…ная роль, объявл…ные результаты соревнования, высуше…ное белье, слома…ная хулиганами скамья, заброш…ные на чердак лыжи, избалова…ная гастролерами публика, получ…ная вечером телеграмма, серьезные и озабоч…ные лица.
Упражнение 15. Вставьте пропущенные буквы. Выпишите примеры в два столбика: а) с краткими прилагательными; б) с краткими причастиями. 1) Игра актера была проникнове…а и взволнова…а. 2) Для рассмотрения жилищных вопросов образова…ы специальные комиссии из представителей заинтересованных ведомств. 3) Сыновья ее грубы и необразова…ы. 4) Сибиряки обычно всегда сдержа…ы. 5) Сюжеты некоторых произведений сложны и запута…ы. 6) Суд не усмотрел в данном деле состава преступления, и обвиняемые были оправда…ы. 7) Чрезвычайные меры в условиях шторма были необходимы и вполне оправда.
Упражнение 16. Вставьте Н или НН, укажите прилагательные, от которых образованы наречия. Как помогают они в написании Н и НН в наречиях. Испуга_о, отчая_о, организова_о, попар_о, надума_о, озор_о, несомне_о, звуч_о, бесшум_о, зауче_о, собра_о, притвор_о, тума_о, искаже_о, рассерже_о, убра_о, обдума_о, растеря_о, огорче_о, наполне_о. Какие два слова не являются наречиями? Какой частью они являются? Как это влияет на написание Н и НН?
Упражнение 17. Раскройте скобки и вставьте, где нужно Н или НН, а также другие пропущенные буквы. Девочка смуще_о улыбнулась.2) Танцовщица двигалась грациоз_о, медле_о, изящ_о. 3) Как только гости разошлись, сразу стало как(то) пусты_о. 4) Зрители стали хлопать преждевреме_о. 5) Мужчине плакать (не)прилич_о. 6) Любил я тай_о. 7) Хвалу приемли равнодуш_о. 8) Напрас_о пророка о тени он просит. 9) И медле_о жгли их до утра огнем. Тест по теме «Правописание н и нн в разных частях речи»
1. В каком слове пишется одна Н? 1) закопчен…ые стены 2) трава подстрижен…а 3) неждан…ый 4) слышан…ая мною история
2. В каком слове пишется одна Н? 1) свежезаморожен…ые овощи 2) швы отстрочен…ы 3) перевязан…ая рука 4) вязан…ые бабушкой носки
3. В каком слове пишется одна Н? 1) общепризнан. 2) сушен…ые в печи грибы 3) стилизован…ый интерьер 4) морожен…ая рыба
4. В каком слове пишется одна Н? 1) обоснован…ый вывод 2) избалован…ый ребенок 3) площадь оцеплен…а 4) асфальтирован…ая улица
5. В каком слове пишется НН? 1) ранен…ый боец 2) кожан…ое кресло 3) юн…ый возраст 4) воспитан…ый человек
6. В каком предложении содержится слово с двумя НН? 1) Работа выполнен…а безупречно. 2) Задача решен…а правильно. 3) Девушка хорошо воспитан…а родителями. 4) Учительница строга и сдержан…а
7. В каком предложении содержится слово с двумя НН? 1) Участки застроен…ы. 2) У работников предприятия ненормирован…ый рабочий день. 3) Во двор въехала гружен. 4) Поля засеян…ы пшеницей
8. В каком ряду есть «третье лишнее»? 1) куплен…ые книги, избалован…ый ребенок, сушен…ые на солнце яблоки 2) нехожен…ые тропы, незван…ые гости, трава скоше…а 3) подписан…ый договор, решен…ая задача, желан…ый ребенок 4) исключен…ый из школы, коротко стрижен…а, бешен…ая скорость
9. На месте каких цифр пишется НН? В конце 19 века Александром Паншиным были сконструирова(1)ы невида(2)ые, удлине(3)ые коньки, которые и позволили ему победить фи(4)ского и норвежского скороходов. а) 1,2; б) 2; в) 2,3; г) 3,4
10. На месте каких цифр пишется НН? Может быть, коньки назва(1)ы коньками именно потому, что в старину делали деревя(2)ые коньки, украше(3)ые завитком в виде лошади(4)ой головы. а) 1,2; б) 2,3; в) 1, 2, 3; г) 3, 4
Ответы: |



 Эта ученица дисциплинированна и организованна.
Эта ученица дисциплинированна и организованна.
 ..ы.
..ы.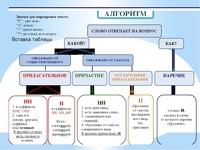 10) Он отнесся к нам благоскло_о. 11) И многие годы (не) слыша_о прошли.12) Она выглядит роскош_о.13) Все вокруг было очень таинстве_о. 14) Тоску изгнанья мы делили друж_о. 15) Но веч_о любить (не)возмо_о. 16) Есть речи – значенье тем_о иль ничтож_о, но им без волненья внимать (не)возмож_о. 17) Она смотрела на меня изумле_о. 18) Я заходил постоя_о в аптеку. 19) Нельзя рассказывать моното_о.
10) Он отнесся к нам благоскло_о. 11) И многие годы (не) слыша_о прошли.12) Она выглядит роскош_о.13) Все вокруг было очень таинстве_о. 14) Тоску изгнанья мы делили друж_о. 15) Но веч_о любить (не)возмо_о. 16) Есть речи – значенье тем_о иль ничтож_о, но им без волненья внимать (не)возмож_о. 17) Она смотрела на меня изумле_о. 18) Я заходил постоя_о в аптеку. 19) Нельзя рассказывать моното_о.  ..ое мнение
..ое мнение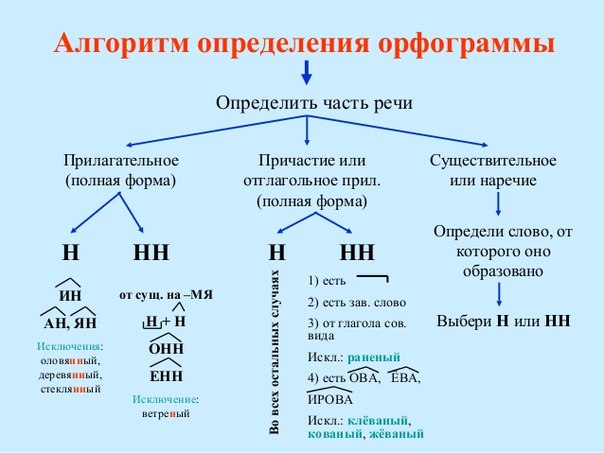
Тест “Н” и “нн” в разных частях речи” с ответами: самостоятельная работа
Сложность: знаток.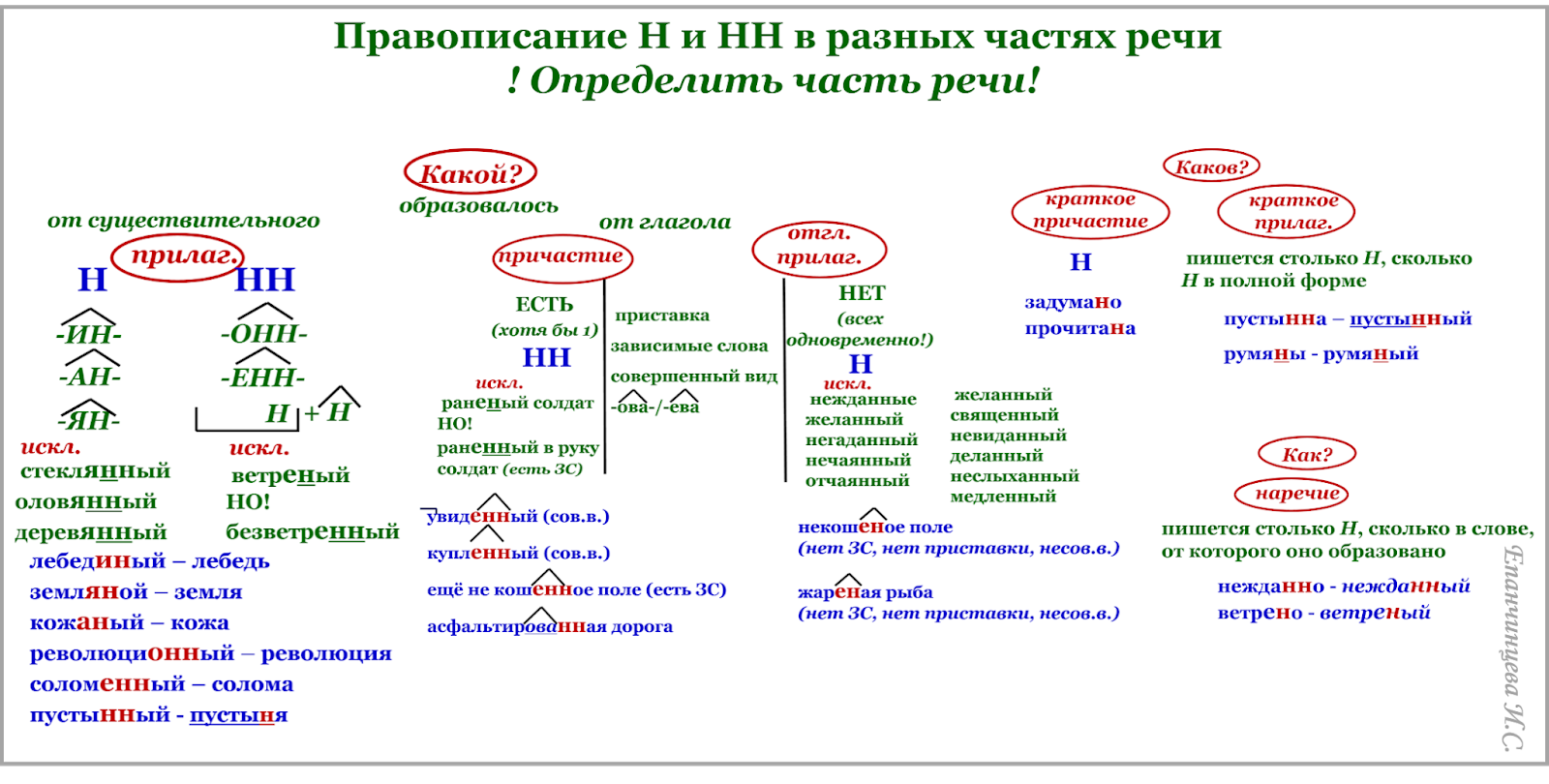
Материал подготовлен совместно с учителем высшей категории
Опыт работы учителем русского языка и литературы — 27 лет.
Вопрос 1 из 12
В каком слове пишется одна Н?
- Правильный ответ
- Неправильный ответ
- Пояснение: Подстрижена — краткое причастие. Причастия в краткой форме всегда пишутся с одной «н» в суффиксе.
- Вы и еще 70% ответили правильно
- 70% ответили правильно на этот вопрос
В вопросе ошибка?
Следующий вопросОтветитьВопрос 2 из 12
В каком слове пишется одна Н?
- Правильный ответ
- Неправильный ответ
- Пояснение: Отстрочены — краткое причастие.
 Оно всегда пишется с одной «н» в суффиксе.
Оно всегда пишется с одной «н» в суффиксе. - Вы и еще 83% ответили правильно
- 83% ответили правильно на этот вопрос
В вопросе ошибка?
ОтветитьВопрос 3 из 12
В каком слове пишется одна Н?
- Правильный ответ
- Неправильный ответ
- Пояснение: Отглагольное прилагательное, образованное от бесприставочного глагола несовершенного вида, пишется с одной
«н». Отглагольное прилагательное «мороженая» образовано от глагола «морозить», поэтому пишется с одной «н»
. - Вы и еще 56% ответили правильно
- 56% ответили правильно на этот вопрос
В вопросе ошибка?
ОтветитьВопрос 4 из 12
В каком слове пишется одна Н?
- Правильный ответ
- Неправильный ответ
- Пояснение: Причастие
«оцеплена» употреблено в краткой форме, поэтому его следует писать с одной «н»
. - Вы и еще 91% ответили правильно
- 91% ответили правильно на этот вопрос
В вопросе ошибка?
ОтветитьВопрос 5 из 12
В каком слове пишется НН?
- Правильный ответ
- Неправильный ответ
- Пояснение: Слово
«воспитанный» можно отнести как к прилагательному, так и к причастию, все зависит от контекста. Оно употреблено в полной форме, поэтому пишется с «нн»
(вне зависимости от того, к какой части речи относится). - Вы и еще 62% ответили правильно
- 62% ответили правильно на этот вопрос
В вопросе ошибка?
ОтветитьВопрос 6 из 12
В каком предложении содержится слово с двумя НН?
- Правильный ответ
- Неправильный ответ
- Пояснение: Сдержанна — прилагательное. Если перед ним поставить слово
«более», то смысл предложения не исказится. В прилагательном в краткой форме пишется столько «н»
, сколько и в полной форме: сдержанная — сдержанна. - Вы и еще 53% ответили правильно
- 53% ответили правильно на этот вопрос
В вопросе ошибка?
ОтветитьВопрос 7 из 12
В каком предложении содержится слово с двумя НН?
- Правильный ответ
- Неправильный ответ
- Пояснение: Если в слове есть суффиксы
«-ова-», «-ева-», «-ирова-», нужно писать «нн». В слове «ненормированный» есть суффикс «-ирова-», поэтому пишутся удвоенные согласные «нн»
. - Вы и еще 64% ответили правильно
- 64% ответили правильно на этот вопрос
В вопросе ошибка?
ОтветитьВопрос 8 из 12
В каком ряду есть «третье лишнее»?
- Правильный ответ
- Неправильный ответ
- Пояснение: Слово
«бешеная» образовано от бесприставочного глагола несовершенного вида (бесить), у него нет зависимых слов, поэтому пишется оно с одной «н».
— лишнее слово. Стрижена — причастие в краткой форме, пишется с одной «н». Исключенный — страдательное причастие, образовано от глагола совершенного вида (исключить), пишется с «нн» - Вы ответили лучше 61% участников
- 39% ответили правильно на этот вопрос
В вопросе ошибка?
ОтветитьВопрос 9 из 12
На месте каких цифр пишется НН? В конце XIX века Александром Паншиным были сконструирова(1)ы невида(2)ые, удлине(3)ые коньки, которые и позволили ему победить фи(4)ского и норвежского скороходов.
- Правильный ответ
- Неправильный ответ
- Пояснение: Сконструированы — причастие в краткой форме, пишется с одной
«н». Отглагольное прилагательное «невиданные» является словарным и пишется с «нн». Отглагольное прилагательное «удлиненные» образовано от глагола совершенного вида «удлинить», поэтому в нем пишется «нн».
. Следует запомнить, что прилагательное «финский» пишется с одной «н», хотя образовано оно от слова «финн» - Вы и еще 71% ответили правильно
- 71% ответили правильно на этот вопрос
В вопросе ошибка?
ОтветитьВопрос 10 из 12
На месте каких цифр пишется НН? Может быть, коньки назва(1)ы коньками именно потому, что в старину делали деревя(2)ые коньки, украше(3)ые завитком в виде лошади(4)ой головы.
- Правильный ответ
- Неправильный ответ
- Пояснение: Названы — краткое причастие, пишется с одной
«н». Деревянные — прилагательное-исключение, пишется с «нн». Украшенные — полное страдательное причастие, образованное от приставочного глагола совершенного вида (украсить), пишется с «нн». Лошадиной — прилагательное, образовано от существительного «лошадь» при помощи суффикса «-ин-».
. Пишется с одной «н» - Вы и еще 86% ответили правильно
- 86% ответили правильно на этот вопрос
В вопросе ошибка?
ОтветитьВопрос 11 из 12
В каком слове на месте пропуска пишется две буквы НН?
- Правильный ответ
- Неправильный ответ
- Пояснение: Слово
«проштампованное» образовано от приставочного глагола совершенного вида «проштамповать», поэтому пишется с двумя «нн»
. - Вы и еще 72% ответили правильно
- 72% ответили правильно на этот вопрос
В вопросе ошибка?
ОтветитьВопрос 12 из 12
В каком ряду во всех словах пропущено НН?
- Правильный ответ
- Неправильный ответ
- Пояснение: Хотя отглагольное прилагательное
«желанный» и образовано от бесприставочного глагола несовершенного вида, оно относится к исключениям и пишется с «нн».
, поэтому в нем тоже удваиваются согласные. - Вы и еще 59% ответили правильно
- 59% ответили правильно на этот вопрос
В вопросе ошибка?
Ответить
 Оно всегда пишется с одной «н» в суффиксе.
Оно всегда пишется с одной «н» в суффиксе.
 Если перед ним поставить слово
Если перед ним поставить слово  Стрижена — причастие в краткой форме, пишется с одной «н». Исключенный — страдательное причастие, образовано от глагола совершенного вида (исключить), пишется с «нн»
Стрижена — причастие в краткой форме, пишется с одной «н». Исключенный — страдательное причастие, образовано от глагола совершенного вида (исключить), пишется с «нн» Следует запомнить, что прилагательное «финский» пишется с одной «н», хотя образовано оно от слова «финн»
Следует запомнить, что прилагательное «финский» пишется с одной «н», хотя образовано оно от слова «финн» Пишется с одной «н»
Пишется с одной «н»
Доска почёта
Чтобы попасть сюда — пройдите тест.
-
Данил Якимов
12/12
Кирилл Старых
10/12
Ксения Рудикова
12/12
Дмитрий Будаговский
12/12
Сергей Пристинский
12/12
Всеволод Киселёв
8/12
Станислав Гудков
11/12
Данил Серещенко
11/12
Викуля Геращенко
12/12
Елизавета Бояршинова
8/12
Тест «Н и НН в разных частях речи» – эффективный способ проверки уровня своих знаний.
Вопросы в заданиях охватывают все пройденные правила написания данной орфограммы. Упражнения составлены в соответствии с программными требованиями по русскому языку. Ученики на практике тренируются находить правильные варианты написания слов, вставлять нужное буквосочетание. С помощью этих заданий можно подготовиться к написанию самостоятельных работ по разным частям речи.
Тест на одну и две буквы н в разных частях речи с ответами поможет наверстать упущенный материал и закрепить полученные знания.
Рейтинг теста
Средняя оценка: 3.8. Всего получено оценок: 8233.
А какую оценку получите вы? Чтобы узнать — пройдите тест.
Тренировочные упражнения по теме Н и НН в различных частях речи.
Замаскирова… ый вход, плете…ая корзина, измуче…ый вид, груж…ая дровами машина, груже…ая машина, нагруже…ая машина, моще…ая дорога, переплавле…ый металл, посоле…ая закуска, ноше…ая шляпа, поноше…ые ботинки, вяза..ая шапка, взволнова…ый разговор, броше…ый камень, купле…ый товар, отправле…ое письмо, застрахова…ое имущество, дипломирова…ый специалис, стекля…ая дверь, гуси..ая кожа, сол..ный огурец, посоле…ый пирог, соле…ые в бочке грибы.
ый вход, плете…ая корзина, измуче…ый вид, груж…ая дровами машина, груже…ая машина, нагруже…ая машина, моще…ая дорога, переплавле…ый металл, посоле…ая закуска, ноше…ая шляпа, поноше…ые ботинки, вяза..ая шапка, взволнова…ый разговор, броше…ый камень, купле…ый товар, отправле…ое письмо, застрахова…ое имущество, дипломирова…ый специалис, стекля…ая дверь, гуси..ая кожа, сол..ный огурец, посоле…ый пирог, соле…ые в бочке грибы.
2. Выдели причастный оборот, расставь, где необходимо, запятые
Дворник убирал листву засыпавшую все дорожки в парке
Котенок играл с упавшим на пол клубком,
Картина висевшая на стене неожиданно упала
Снежинки блестевшие на волосах казались маленькими искорками.
________________________________________________________________________________________
1. Вставь пропущенные буквы Н или НН
Замаскирова. ..ый вход, плете…ая корзина, измуче…ый вид, груж…ая дровами машина, груже…ая машина, нагруже…ая машина, моще…ая дорога, переплавле…ый металл, посоле…ая закуска, ноше…ая шляпа, поноше…ые ботинки, вяза..ая шапка, взволнова…ый разговор, броше…ый камень, купле…ый товар, отправле…ое письмо, застрахова…ое имущество, дипломирова…ый специалис, стекля…ая дверь, гуси..ая кожа, сол..ный огурец, посоле…ый пирог, соле…ые в бочке грибы.
..ый вход, плете…ая корзина, измуче…ый вид, груж…ая дровами машина, груже…ая машина, нагруже…ая машина, моще…ая дорога, переплавле…ый металл, посоле…ая закуска, ноше…ая шляпа, поноше…ые ботинки, вяза..ая шапка, взволнова…ый разговор, броше…ый камень, купле…ый товар, отправле…ое письмо, застрахова…ое имущество, дипломирова…ый специалис, стекля…ая дверь, гуси..ая кожа, сол..ный огурец, посоле…ый пирог, соле…ые в бочке грибы.
2. Выдели причастный оборот, расставь, где необходимо, запятые
Дворник убирал листву засыпавшую все дорожки в парке
Котенок играл с упавшим на пол клубком,
Картина висевшая на стене неожиданно упала
Снежинки блестевшие на волосах казались маленькими искорками.
_______________________________________________________________________________________-
1. Вставь пропущенные буквы Н или НН
Замаскирова. ..ый вход, плете…ая корзина, измуче…ый вид, груж…ая дровами машина, груже…ая машина, нагруже…ая машина, моще…ая дорога, переплавле…ый металл, посоле…ая закуска, ноше…ая шляпа, поноше…ые ботинки, вяза..ая шапка, взволнова…ый разговор, броше…ый камень, купле…ый товар, отправле…ое письмо, застрахова…ое имущество, дипломирова…ый специалис, стекля…ая дверь, гуси..ая кожа, сол..ный огурец, посоле…ый пирог, соле…ые в бочке грибы.
..ый вход, плете…ая корзина, измуче…ый вид, груж…ая дровами машина, груже…ая машина, нагруже…ая машина, моще…ая дорога, переплавле…ый металл, посоле…ая закуска, ноше…ая шляпа, поноше…ые ботинки, вяза..ая шапка, взволнова…ый разговор, броше…ый камень, купле…ый товар, отправле…ое письмо, застрахова…ое имущество, дипломирова…ый специалис, стекля…ая дверь, гуси..ая кожа, сол..ный огурец, посоле…ый пирог, соле…ые в бочке грибы.
2. Выдели причастный оборот, расставь, где необходимо, запятые
Дворник убирал листву засыпавшую все дорожки в парке
Котенок играл с упавшим на пол клубком,
Картина висевшая на стене неожиданно упала
Снежинки блестевшие на волосах казались маленькими искорками.
Тест по теме «Правописание Н и НН в различных частях речи».
1.В каком ряду во всех словах на месте пропусков пишется НН?
1)кожа_ый мяч, исписа_ый листок, подоко_ик;
2)маринова_ые грибы, стари_ая гравюра, ветре_ое утро;
3)пута_ые мысли, квалифицирова_ый рабочий, печё_ый картофель;
4)обеде_ое время, нежда_ый гость, безветре_ая ночь.
2.В каком ряду во всех словах на месте пропусков пишется НН?
1)пламе_ая речь, зелё_ый плод, зако_ое требование;
2)кова_ая решётка, избра_ые произведения, ра_яя молодость;
3)балова_ый ребёнок, дорога пусты_а, избра_ики народа;
4) полома_ый автомобиль, лома_ый грош, исти_ый гуманизм.
3.В каком ряду во всех словах на месте пропусков пишется Н?
1)журавли_ый крик, обветре_ые лица, гружё_ые составы;
2)серебря_ая повеска, яблоко зелен_о, плетё_ая корзина;
3)гружё_ая лесом баржа, тушё_ые овощи; льня_ое полотно;
4)глиня_ая изба, печё_ая картошка, запечё_ое в тесте яблоко.
4.В каком ряду во всех словах на месте пропусков пишется Н?
1)масля_ые краски, писа_ая красавица, солё_ые огурцы;
2)голуби_ое воркование, беспричи_ый страх, ране_ый солдат;
3)си_ие облака, стекля_е двери, наруч_ые часы;
4)передача не законче_а, жестя_ые коробки, телефо_ый аппарат.
5.В каком предложении на месте пропуска пишется Н?
1)Над столом горела привеше_ая к потолку небольшая лампа.
2)В сетке купе лежала соломе_ая шляпа с цветами и ягодами.
3)Произведение было написа_о мастером.
4)На двор станции влетела, гремя о камни, запылё_ая тройка.
6. В каком предложении во всех словах на месте пропусков пишется НН?
1)Кова_ые сапоги гулко стучали по мощё_ой булыжником мостовой.
2)Нижние ряды Гости_ого двора были заполнены оживлё_ыми посетителями.
3)Студё_ая вода струилась по каме_ым плитам.
4)Непогода отступила, и под солнцем стари_ое север_ое село было прекрасно.
7. Укажите номер ответа, в котором указаны все цифры, на месте которых в предложении пишется НН.
На столе стояли солё(1)ые огурцы, реза(2)ая кусочками рыба и гусь запечё(3)ый в духовке в серебря(4)ой кастрюле.
1) 1,3; 2) 2,3,4; 3) 1,2,3,4; 4) 2,3.
8. Укажите номер ответа, в котором указаны все цифры, на месте которых в предложении пишется НН.
Неожида(1)о вернулся из города отец с печаль(2)ой надуше(3)ой дамой, и матушка стала вдруг необыкнове(4)о оживлё(5)ой.
1) 3,4,5; 2) 1,2,4,5; 3) 1,3,4,5; 4) 1,3,4.
9.Укажите номер ответа, в котором указаны все цифры, на месте которых в предложении пишется Н.
Медле(1)о похолодела Оленька, широко раскрыла очарователь(2)ые глаза, оттенё(3)ые пепель(4)ыми кругами, схватила свечу и выбежала в сени.
1) 1,2,4; 2) 2,4; 3) 1,2,3,4; 4) 2,3,4.
КЛЮЧ:
1 – 4
2 – 3
3 – 2
4 – 1
5 – 3
6 – 2
7 – 4
8 – 3
9 – 2
Тест по теме «Правописание -Н- и НН- в различных частях речи»
Тест по теме «Правописание –Н- и –НН- в различных частях речи»
В каком слове на месте пропуска пишется НН?
Работа выполне. .а
.а
Песча..ый бархан
Дорожная плетё..ая корзина
Маринова..ые грибы
В каком варианте ответа правильно указаны все цифры, на месте которых пишется Н?
На автопортрете художник одет в изыска(1)ый плащ, лицо спокойно и увере(2)о, усы и бородка тщательно ухоже(3)ы.
1 2) 2 3) 3 4) 1,3
В каком варианте ответа правильно указаны все цифры, на месте которых пишется Н?
В первых картинах И.Н. Никитина была некоторая упрощё(1)ость: фигуры выхваче(2)ы из темноты неопределё(3)ого пространства лучом яркого света и существуют вне связи со средой.
1 2) 2 3) 1,2 4) 1,2,3
В каком варианте ответа правильно указаны все цифры, на месте которых пишется Н?
Ось вращения спутника Земли вокруг собстве(1)ой оси направле(2)а почти перпендикулярно к плоскости эклиптики, поэтому в области полюсов Луны расположе(3)ы два необычных типа областей.
1) 1 2) 2 3) 3 4) 2,3
В каком варианте ответа правильно указаны все цифры, на месте которых пишется Н?
В совреме(1)ом строительстве цементом, смеша(2)ым с песком и водой или водным раствором солей, соединяют кирпичи и бето(3)ые блоки.
1) 1 2) 2 3) 1,3 4) 1,2,3
В каком примере пишется НН?
Муравьи..ый след
Небелё..ый песок
Сея..ый песок
Даль тума..а
В каком примере пишется НН?
Цели..ая земля
Кипячё..ое молоко
Море взволнова..о морем
Непроше..ый гость
В каком примере пишется одно Н?
краше..ые волосы
операцио..ая система
сушё..ые на солнце вишни
дети непосредстве..ы
В каком варианте ответа правильно указаны все цифры, на месте которых пишется НН?
Может быть, коньки назва(1)ы коньками именно потому, то в старину делали деревя(2)ые коньки, украше(3)ые завитком в виде лошади(4)ой головы
1,2 2) 2,3 3) 1,2,3 4) 3,4
На месте каких цифр пишется НН?
В конце XIX века Александром Паншиным были сконструирова(1)ы
невида(2)ые, удлинё(3)ые коньки, которые и позволили ему победить
фи(4)ского и норвежского скороходов.
1,2 2) 2 3) 2,3 4) 3,4
На месте каких цифр пишется НН?
Мы видим, что в костя(1)ых коньках, найде(2)ых археологами на севере Европы, продела(3)ы отверстия для кожа(4)ых тесёмок.
1,2 2) 2 3)1,2,3 4) 3,4
В каком варианте ответа правильно указаны все цифры, на месте которых пишется НН?
В спортивной ходьбе запреще(1)о отрывать от земли обе ноги одновреме(2)о, как это обыкнове(3)о делают при беге; все нарушения бывают чётко зафиксирова(4)ы кинокамерой.
1,2,3,4 2) 2,4 3) 2,3 4) 3,4
В каком варианте ответа правильно указаны все цифры, на месте которых пишется НН?
В стари(1)у лук был грозным оружием: калё(2)ая стрела, пуще(3)ая рукой опытного стрелка, могла пронзить толсте(4)ую стену.
1,2,4 2) 2,4 3) 3 4) 3,4
В каком примере пишется НН?
1) калё..ое железо
2) Ученики не подготовле. .ы
.ы
3) земля..ой холм
4) замечание це..о
В каком примере пишется НН?
Плетё..ое кресло
Ржа..ая мука
Спица слома..а
Погаше..ый свет
В каком примере пишется НН?
Девочка румя..а
Песча..ая коса
Вещи собра..ы
Скоше..ый газон
В каком слове на месте пропуска пишется НН?
Ружьё заряже..о
Прямая мощё..ая дорога
Глиня..ый горшок
Бронирова..ый автомобиль
В каком слове на месте пропуска пишется НН?
Вощё..ый блестящий пол
Офицеры контуже..ы
Ледя..ой взгляд
Необоснова..ый вывод
В каком слове на месте пропуска пишется НН?
Большие золочё..ые ложки
Змеи..ый яд
Деревня освобожде. .а
.а
Рискова..ый поступок
В каком слове на месте пропуска пишется НН?
Лошадь привяза..а
Серый ноше..ый костюм
Прикова..ый узник
Серебря..ый браслет
В каком слове на месте пропуска пишется НН?
Патентова..ые изделия
Письмо сожже..о
Голуби..ое яйцо
Неписа..ый закон
В каком слове на месте пропуска пишется НН?
Тренирова..ый спортсмен
Соловьи..ая песня
Люди не обуче..ы
Старый нетопле..ый дом
В каком слове на месте пропуска пишется НН?
Прессова..ое изделие
Незва..ый визитёр
Лебеди..ый пух
Вещь прода..а
В каком слове на месте пропуска пишется НН?
Комиссия созда..а
Непроше. .ый гость
.ый гость
Организова..ый ученик
Полотня..ая ткань
В каком слове на месте пропуска пишется НН?
Ю..ое создание
Взволнова..ый посетитель
Книги прочита..ы
Крупные мочё..ые яблоки
Упражнения на правописание н и нн (одна и две буквы н) – тренажер от Skills4U
Наш интерактивный тренажер на «н» и «нн» в разных частях речи будет полезен всем без исключения ученикам средней общеобразовательной школы. Он не только научит грамотно писать, но и поможет сформировать стойкий учебный навык безошибочно находить правильный ответ. Правила гораздо легче учить на конкретных примерах, и вы сейчас в этом убедитесь.
Все задания на правописание «н» и «нн» распределены на разделы в соответствии со школьной программой. Вы можете выбрать тест для учеников 6 или 7-го класса, заняться подготовкой к ОГЭ или ЕГЭ. Еще один вариант – пройти тест на одну и две «н» в определенных частях речи. Каждый выбирает, в какой последовательности тренироваться, Главное – делать это регулярно и соблюдать наши рекомендации. Они основаны на многолетних наблюдениях и подкреплены положительными отзывами наших учеников.
Каждый выбирает, в какой последовательности тренироваться, Главное – делать это регулярно и соблюдать наши рекомендации. Они основаны на многолетних наблюдениях и подкреплены положительными отзывами наших учеников.
Выполнение одного задания на правильное написание «н» и «нн» в суффиксах полных страдательных причастий или в отглагольных прилагательных займет не более 5-10 минут. Задача очень простая: вставьте «н» или «нн» в слово, указанное на экране, выбрав один из вариантов ответа. Вы сразу поймете, сделали ли правильный выбор или ошиблись. Ошибка подсвечивается красным цветом, но, в то же время, виден и правильный ответ. Также можно прочитать правильно написанное слово, чтобы оно осталось у вас в памяти надолго.
Наша методика основана на методе осознанного повторения. Интерактивный тренажер, созданный на базе интеллектуальной образовательной платформы, учитывает результаты ответов ученика по теме «Буквы Н и НН» в различных частях речи и формирует рейтинг, а также дает рекомендации по дальнейшему продолжению занятий. Вам не потребуется заглядывать в учебник и искать правила, когда пишется две «н». Достаточно вернуться к выполнению теста через несколько часов, а затем регулярно тренироваться по выбранной теме в течение 4-5 последующих дней. Результаты вас очень порадуют.
Вам не потребуется заглядывать в учебник и искать правила, когда пишется две «н». Достаточно вернуться к выполнению теста через несколько часов, а затем регулярно тренироваться по выбранной теме в течение 4-5 последующих дней. Результаты вас очень порадуют.
Как показывает практика, за это время успевает сформироваться устойчивый навык нахождения правильных ответов по теме «Правописание Н и НН», упражнения помогают его закрепить. Теперь вы сможете без ошибок применять правила и справитесь с диктантом или итоговым экзаменом. Очень удобно, что в этом разделе собраны упражнения на все основные правила написания не только прилагательных, но и наречий, полных и кратких страдательных причастий.
Кстати, подготовка к ОГЭ и ЕГЭ, вынесена в отдельные темы. Это очень пригодится выпускникам в 9 и 11 классе, которые сдают итоговые экзамены в конце года. Здесь собраны различные упражнения на «н» и «нн». Они помогут вспомнить пройденный материал и пройти испытание успешно. Теперь, если вам попадется отглагольное прилагательное или оборот с причастием, вы не будете сомневаться, одна и две буквы «н» должны быть в суффиксе.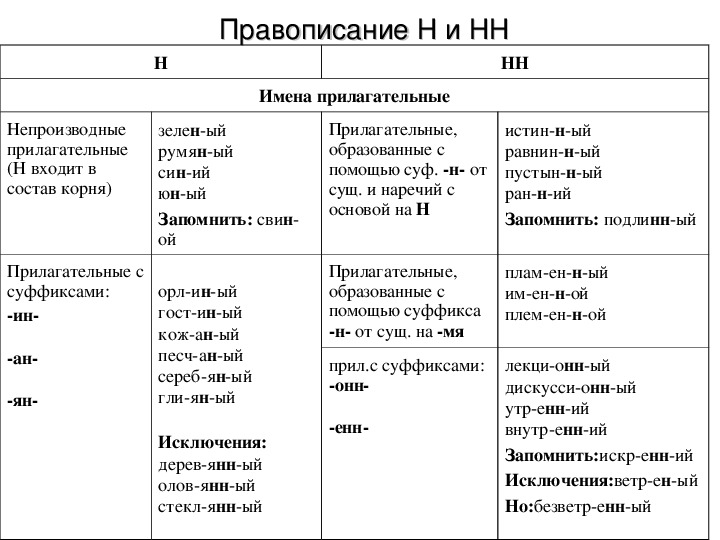 Осознанное повторение творит настоящие чудеса!
Осознанное повторение творит настоящие чудеса!
На прохождение одного теста на «н» и «нн» уйдет не более 10 минут, а ежедневное время занятий составит примерно полчаса. Согласитесь, что заниматься дома очень удобно. Не нужно никуда ехать и встречаться с репетитором. В условиях дистанционного обучения наш «Н и НН» тест онлайн пользуется большой популярностью. На тренажере охотно занимаются не только школьники, но и взрослые люди, желающие грамотно писать. Родители и учителя могут использовать наш ресурс, чтобы правильно оценить уровень подготовки ученика, его готовность к итоговым экзаменам по русскому языку. Особенно удобен наш тренажер для учителей, которые могут сделать срез знаний целого класса и устроить своеобразный турнир рейтингов.
Если вы не очень уверены, как писать н и нн, тест поможет вам выявить пробелы в знаниях. Уникальность нашего тренажера заключается в персонифицированном подходе. Система запоминает, где вы допустили ошибку, и предлагает новые примеры, чтобы сформировать устойчивый навык нахождения правильных вариантов. Если вы ошибетесь и перепутаете «н» и «нн», упражнения с ответами помогут быстро исправить ошибку. После нескольких тренировок вы научитесь писать правильно, и это большая победа!
Если вы ошибетесь и перепутаете «н» и «нн», упражнения с ответами помогут быстро исправить ошибку. После нескольких тренировок вы научитесь писать правильно, и это большая победа!
Первичное тестирование на сайте интеллектуальной образовательной платформы Skills4u каждый может пройти совершенно бесплатно. Для того, чтобы иметь возможность продолжать занятия в удобном режиме, необходимо зарегистрироваться на сайте и оформить подписку на месяц, полугодие или целый учебный год. Присоединяйтесь к нам – и уже очень скоро проблема – одна и две «н» в разных частях речи – перестанет вас волновать, а успеваемость по русскому языку существенно улучшится.
правописание Н-НН в разных ч…
Универсальный школьный справочник представляет собой компактное изложение теоретического материала об орфограмме Н-НН в разных частях речи, предложенное в виде вопросно-ответной формы для всех случаев правописания данной орфограммы в школьном курсе русского языка, с алгоритмами, упражнениями, проверочными тестами и инструкцией к самопроверке, необходимыми словарями.
Полная информация о книге
- Вид товара:Книги
- Рубрика:Русский язык
- Целевое назначение:Справочники и словари д/общеобразовательной школы
- ISBN:978-5-7057-5631-5
- Серия:Универсальный школьный справочник
- Издательство: ООО»Учитель»
- Год издания:0
- Количество страниц:143
- Тираж:1000
- Формат:60х84/16
- УДК:372. 016:84.161.1*05/11
- Штрихкод:9785705756315
- Переплет:обл.
- Сведения об ответственности:авт.-сост. О. В. Пряникова
- Вес, г.:143
- Код товара:2457848
 016:84.161.1*05/11
016:84.161.1*05/11Введение в тегирование части речи и скрытую марковскую модель
, Дивья Годаял,
,, , Сачин Малхотра и Дивья Годаял, ,
Источник: https://english. stackexchange.com/questions/218058/parts-of-speech-and-functions-bob-made-a-book-collector -happy-the-other-day
stackexchange.com/questions/218058/parts-of-speech-and-functions-bob-made-a-book-collector -happy-the-other-dayДавайте вернемся в те времена, когда у нас не было языка для общения. У нас был только язык жестов. Так мы обычно общаемся с собакой дома, верно? Когда мы говорим ему: «Мы любим тебя, Джимми», он в ответ виляет хвостом.Это не значит, что он знает, что мы на самом деле говорим. Вместо этого он отвечает просто потому, что понимает язык эмоций и жестов больше, чем слова.
Мы, люди, научились понимать множество нюансов естественного языка больше, чем любое животное на этой планете. Вот почему, когда мы говорим «Я ЛЮБЛЮ тебя, дорогая», а когда мы говорим «Давай займемся ЛЮБОВЬЮ, милый», мы имеем в виду разные вещи. Поскольку мы понимаем основную разницу между этими двумя фразами, наши ответы очень разные.Именно этим сложностям понимания естественного языка мы и хотим научить машину.
Это может означать, что когда ваша будущая собака-робот слышит «Я люблю тебя, Джимми», она будет знать, что ЛЮБОВЬ — это глагол. Он также понял бы, что это эмоция, которую мы выражаем, на которую он бы определенным образом отреагировал. А может, когда вы говорите своему партнеру «Давай займемся ЛЮБОВЬЮ», собака просто не будет вмешиваться в ваши дела?
Он также понял бы, что это эмоция, которую мы выражаем, на которую он бы определенным образом отреагировал. А может, когда вы говорите своему партнеру «Давай займемся ЛЮБОВЬЮ», собака просто не будет вмешиваться в ваши дела?
Это просто пример того, как обучение робота общению на известном нам языке может облегчить жизнь.
Основным вариантом использования, выделенным в этом примере, является то, насколько важно понимать разницу в использовании слова ЛЮБОВЬ в разных контекстах.
Тегирование части речи
С самого раннего возраста мы привыкли идентифицировать часть тегов речи. Например, чтение предложения и возможность определить, какие слова действуют как существительные, местоимения, глаголы, наречия и т. Д. Все это называется частью речевых тегов.
Давайте посмотрим на определение в Википедии для них:
В лингвистике корпуса, тегирование части речи ( POS-тегирование или PoS-тегирование или POST ), также называемое грамматическим тегированием или слов — устранение неоднозначности категории — это процесс разметки слова в тексте (корпусе) как соответствующего определенной части речи на основе как его определения, так и контекста — i.
 е., его отношения со смежными и связанными словами во фразе, предложении или абзаце. Упрощенная форма этого обычно преподается детям школьного возраста при идентификации слов как существительных, глаголов, прилагательных, наречий и т. Д.
е., его отношения со смежными и связанными словами во фразе, предложении или абзаце. Упрощенная форма этого обычно преподается детям школьного возраста при идентификации слов как существительных, глаголов, прилагательных, наречий и т. Д.Идентификация части речевых тегов намного сложнее, чем просто сопоставление слов с их частью речи теги. Это потому, что теги POS не являются чем-то универсальным. Вполне возможно, что одно слово может иметь другую часть речевого тега в разных предложениях, основанных на разных контекстах.Вот почему невозможно иметь общее сопоставление для тегов POS.
Как видите, невозможно вручную определить различные теги части речи для данного корпуса. Новые типы контекстов и новые слова продолжают появляться в словарях на разных языках, а ручная маркировка POS сама по себе не масштабируется. Вот почему мы полагаемся на машинную маркировку POS.
Прежде чем продолжить и посмотреть, как выполняется тегирование части речи, мы должны понять, почему тегирование POS необходимо и где его можно использовать.
Почему теги части речи?
Тегирование части речи само по себе не может быть решением какой-либо конкретной проблемы НЛП. Однако это делается как предварительное условие для упрощения множества различных проблем. Давайте рассмотрим несколько применений POS-тегов в различных задачах НЛП.
Преобразование текста в речь
Давайте посмотрим на следующее предложение:
Они отказывают нам в получении разрешения на отказ. Слово отказать используется в этом предложении дважды и имеет здесь два разных значения. refUSE (/ rəˈfyo͞oz /) — глагол, означающий «отрицать», а REFuse (/ ˈrefˌyo͞os /) — существительное, означающее «мусор» (то есть они не омофоны). Таким образом, нам нужно знать, какое слово используется, чтобы правильно произносить текст. (По этой причине системы преобразования текста в речь обычно используют POS-теги.)
Обратите внимание на теги части речи, созданные для этого самого предложения пакетом NLTK.
>>> text = word_tokenize («Они отказывают нам в выдаче разрешения на отказ») >>> nltk.pos_tag (текст) [('Они', 'PRP'), ('отказать', 'VBP'), ('в', 'TO'), ('разрешить', 'VB'), ('нас', 'PRP'), ('к', 'TO'), ('получить', 'VB'), ('the', 'DT'), ('отказаться', 'NN'), ('разрешить', 'NN')] Как видно из результатов, предоставленных пакетом NLTK, теги POS для refUSE и REFuse различаются. Используя эти два разных тега POS для нашего конвертера текста в речь, можно получить другой набор звуков.
Точно так же давайте посмотрим на еще одно классическое применение тегов POS: устранение неоднозначности слов.
Устранение неоднозначности со словами
Давайте поговорим об этом парне по имени Питер. Поскольку его мать — ученый-невролог, она не отправила его в школу. В его жизни не было науки и математики.
Однажды она провела эксперимент и заставила его сесть в математический класс. Несмотря на то, что у него не было никаких предварительных знаний по предметам, Питер думал, что успешно сдал свой первый тест. Затем его мать взяла пример из теста и опубликовала его, как показано ниже. (Престижность ей!)
Затем его мать взяла пример из теста и опубликовала его, как показано ниже. (Престижность ей!)
Слова часто встречаются в разных смыслах как разные части речи. Например:
- Она увидела медведя.
- Ваши усилия принесут плодов.
Слово медведь в приведенных выше предложениях имеет совершенно разные значения, но, что более важно, одно — существительное, а другое — глагол. Элементарное устранение неоднозначности смысла слов возможно, если вы можете пометить слова их тегами POS.
Устранение смысловой неоднозначности (WSD) — это определение того, какое значение слова (то есть какое значение) используется в предложении, когда слово имеет несколько значений.
Попытайтесь придумать несколько значений этого предложения:
Время летит как стрела
Вот различные толкования данного предложения. Значение и, следовательно, часть речи могут различаться для каждого слова.
Значение и, следовательно, часть речи могут различаться для каждого слова.
Как мы можем ясно видеть, для данного предложения существует несколько возможных интерпретаций. Разные интерпретации дают разные типы частей речи для слов.Эта информация, если она доступна нам, может помочь нам узнать точную версию / толкование предложения, а затем мы сможем оттуда действовать.
Приведенный выше пример показывает нам, что одному предложению могут быть назначены три разные последовательности тегов POS, которые одинаково вероятны. Это означает, что очень важно знать, какой конкретный смысл передается данным предложением всякий раз, когда оно появляется. Это устранение неоднозначности в смысле слова, поскольку мы пытаемся выяснить ИДЕАЛЬНУЮ последовательность.
Это лишь два из множества приложений, в которых нам может потребоваться маркировка POS. Есть и другие приложения, требующие POS-тегов, например ответы на вопросы, распознавание речи, машинный перевод и т. Д.
Д.
Теперь, когда у нас есть базовые знания о различных применениях тегов POS, давайте посмотрим, как мы можем фактически назначить теги POS всем словам в нашем корпусе.
Типы POS-тегеров
Алгоритмы POS-тегов делятся на две отдельные группы:
- POS-тегеры на основе правил
- Стохастические POS-тегеры
E.Устройство тегов Brill, одно из первых и наиболее широко используемых устройств для тегов POS на английском языке, использует алгоритмы на основе правил. Давайте сначала рассмотрим очень краткий обзор того, что такое теги на основе правил.
Маркировка на основе правил
Автоматическая часть тегов речи — это область обработки естественного языка, в которой статистические методы оказались более успешными, чем методы, основанные на правилах.
Типичные подходы на основе правил используют контекстную информацию для присвоения тегов неизвестным или неоднозначным словам.Устранение неоднозначности выполняется путем анализа лингвистических характеристик слова, предшествующего слова, следующего за ним слова и других аспектов.
Например, если предыдущее слово является артиклем, то рассматриваемое слово должно быть существительным. Эта информация закодирована в виде правил.
Пример правила:
Если неопределенному / неизвестному слову X предшествует определитель, а за ним следует существительное, пометьте его как прилагательное.
Определение набора правил вручную — чрезвычайно громоздкий процесс, который вообще не масштабируется.Итак, нам нужен какой-то автоматический способ сделать это.
Устройство тегов Brill — это устройство тегов на основе правил, которое просматривает обучающие данные и находит набор правил тегирования, которые лучше всего определяют данные и минимизируют ошибки тегирования POS. Самым важным моментом, который следует отметить в отношении теггера Brill, является то, что правила не создаются вручную, а вместо этого выясняются с помощью предоставленного корпуса. Единственная необходимая разработка функций — это набор шаблонов правил , которые модель может использовать для создания новых функций.
Давайте продолжим и посмотрим на теги Stochastic POS.
Стохастическая маркировка части речи
Термин «стохастическая маркировка» может относиться к любому количеству различных подходов к проблеме маркировки торговой точки. Любая модель, которая каким-либо образом включает частоту или вероятность, может быть правильно названа стохастической.
Простейшие стохастические тегеры устраняют неоднозначность слов, основываясь исключительно на вероятности того, что слово встречается с определенным тегом. Другими словами, тег, который чаще всего встречается в обучающем наборе со словом, является тегом, присвоенным неоднозначному экземпляру этого слова.Проблема с этим подходом заключается в том, что, хотя он может давать допустимый тег для данного слова, он также может давать недопустимые последовательности тегов.
Альтернативой частотному подходу является вычисление вероятности появления заданной последовательности тегов. Иногда это называют подходом n-gram , имея в виду тот факт, что лучший тег для данного слова определяется вероятностью того, что он встречается с n предыдущими тегами. Этот подход имеет гораздо больше смысла, чем тот, который был определен ранее, поскольку он учитывает теги для отдельных слов в зависимости от контекста.
Этот подход имеет гораздо больше смысла, чем тот, который был определен ранее, поскольку он учитывает теги для отдельных слов в зависимости от контекста.
Следующий уровень сложности, который может быть введен в стохастический теггер, объединяет два предыдущих подхода, использующих как вероятности последовательности тегов, так и измерения частоты слов. Это известно как скрытая марковская модель (HMM) .
Перед тем, как перейти к рассмотрению модели Маркова Hidden , давайте сначала посмотрим, что такое модель Маркова. Это поможет лучше понять значение термина Hidden в HMM.
Markov Model
Скажем, есть только три типа погодных условий, а именно
Теперь, поскольку наш юный друг, которого мы представили выше, Питер, маленький ребенок, он любит играть на улице. Он любит солнечную погоду, потому что все его друзья выходят играть в солнечную погоду.
Он ненавидит дождливую погоду по понятным причинам.
Каждый день его мама наблюдает за погодой по утрам (то есть когда он обычно идет играть) и, как всегда, Питер подходит к ней сразу после того, как встал, и просит рассказать ему, какая будет погода. подобно.Поскольку она ответственный родитель, она хочет ответить на этот вопрос как можно точнее. Но единственное, что у нее есть, — это набор наблюдений за погодой в течение нескольких дней.
Как она делает прогноз погоды на сегодня, основываясь на погоде за последние N дней?
Допустим, у вас есть последовательность. Примерно так:
Sunny, Rainy, Cloudy, Cloudy, Sunny, Sunny, Sunny, Rainy
Итак, погода для любого дня может быть в любом из трех состояний.
Допустим, мы решили использовать модель цепи Маркова для решения этой проблемы. Теперь, используя данные, которые у нас есть, мы можем построить следующую диаграмму состояний с помеченными вероятностями.
Чтобы вычислить вероятность сегодняшней погоды с учетом N предыдущих наблюдений, мы будем использовать марковское свойство.
Цепь Маркова — это, по сути, простейшая из известных марковских моделей, то есть она подчиняется свойству Маркова.
Свойство Маркова предполагает, что распределение случайной величины в будущем зависит исключительно только от ее распределения в текущем состоянии, и ни одно из предыдущих состояний не влияет на будущие состояния.
Для более подробного объяснения работы цепей Маркова перейдите по этой ссылке.
Кроме того, взгляните на следующий пример, чтобы увидеть, как можно вычислить вероятность текущего состояния, используя формулу выше, принимая во внимание марковское свойство.
Примените свойство Маркова в следующем примере.
Мы можем ясно видеть, что согласно свойству Маркова вероятность того, что погода завтрашнего дня будет солнечной, зависит исключительно от погоды сегодняшнего , а не от вчерашнего .
Давайте теперь продолжим и посмотрим, что скрыто в скрытых марковских моделях.
Hidden Markov Model
Это снова маленький ребенок Питер, и на этот раз он будет приставать к своему новому смотрителю, то есть к вам. (Ой !!)
(Ой !!)
Как смотритель, одна из самых важных задач для вас — уложить Питера в постель и убедиться, что он крепко спит. После того, как вы уложили его, вы должны убедиться, что он действительно спит, а не причинить вреда.
Однако вы не можете снова войти в комнату, так как это наверняка разбудит Питера.Так что все, что вам нужно решить, это шумы, которые могут исходить из комнаты. Либо в комнате тихо , либо из комнаты доносится шум . Это ваши состояния.
Мать Питера, прежде чем бросить вас в этот кошмар, сказала:
Да пребудет с вами звук 🙂
Его мать дала вам следующую диаграмму состояний. На диаграмме есть некоторые состояния, наблюдения и вероятности.
Здравствуйте, смотритель, это может помочь. ~ Мать Петра. Радоваться, веселиться !Обратите внимание, что нет прямой зависимости между звуком из комнаты и тем, что Питер спит.
Есть два вида вероятностей, которые мы можем видеть на диаграмме состояний.
- Одна из них — это вероятности эмиссии , которые представляют вероятности проведения определенных наблюдений в конкретном состоянии. Например, у нас есть
P (шум | пробуждение) = 0,5. Это вероятность выброса. - Другие — это переходов вероятностей, которые представляют вероятность перехода в другое состояние для данного конкретного состояния.Например, у нас есть
P (спит | бодрствует) = 0,4. Это вероятность перехода.
Марковское свойство применимо и к этой модели. Так что не слишком усложняйте ситуацию. Марков, ваш спаситель сказал:
Не углубляйтесь в историю…
Свойство Маркова, которое применимо к примеру, который мы здесь рассмотрели, будет заключаться в том, что вероятность нахождения Петра в состоянии зависит ТОЛЬКО от предыдущее состояние.
Но в свойстве Маркова есть явный изъян.Если Питер не спал в течение часа, то вероятность того, что он заснет, выше, чем если бы он не спал всего 5 минут. Итак, история имеет значение. Следовательно, модель на основе конечного автомата Маркова не совсем верна. Это просто упрощение.
Итак, история имеет значение. Следовательно, модель на основе конечного автомата Маркова не совсем верна. Это просто упрощение.
Марковское свойство, хотя и неверно, делает эту проблему очень разрешимой.
Обычно мы наблюдаем более длительные периоды бодрствования и сна ребенка. Если Питер сейчас не спит, вероятность того, что он не спит, выше, чем вероятность того, что он заснет.Следовательно, 0,6 и 0,4 на диаграмме выше. P (бодрствующий | бодрствующий) = 0,6 и P (спящий | бодрствующий) = 0,4
Перед тем, как на самом деле пытаться решить проблему с помощью HMM, давайте свяжем эту модель с задачей тегирования части речи.
HMM для части тегов речи
Мы знаем, что для моделирования любой проблемы с использованием скрытой марковской модели нам нужен набор наблюдений и набор возможных состояний. Состояния в HMM скрыты.
В части задачи тегирования речи наблюдений являются самими словами в заданной последовательности.
Что касается состояний , которые скрыты, это будут теги POS для слов.
Вероятности перехода будут чем-то вроде P (VP | NP) , то есть, какова вероятность того, что текущее слово будет иметь тег Verb Phrase, учитывая, что предыдущий тег был существительным.
Вероятность выброса будет P (john | NP) или P (will | VP) , то есть какова вероятность того, что слово будет, скажем, John, учитывая, что тег является существительной фразой.
Обратите внимание, что это всего лишь неформальное моделирование проблемы, чтобы дать очень общее представление о том, как проблему тегирования части речи можно смоделировать с помощью HMM.
Как решить эту проблему?
Возвращаясь к нашей проблеме заботы о Питере.
Мы раздражены? ?
Наша проблема заключалась в том, что у нас есть начальное состояние: Питер не спал, когда вы уложили его в постель. После этого вы записали последовательность наблюдений, а именно шум, или тихий, на разных временных шагах. Используя этот набор наблюдений и начальное состояние, вы хотите выяснить, будет ли Питер бодрствовать или спать после, скажем, N временных шагов.
Используя этот набор наблюдений и начальное состояние, вы хотите выяснить, будет ли Питер бодрствовать или спать после, скажем, N временных шагов.
Рисуем все возможные переходы, начиная с начального состояния. По мере нашего продвижения вперед появляется экспоненциальное количество ветвей. Таким образом, модель экспоненциально вырастает до после нескольких временных шагов. Даже без учета каких-либо наблюдений. Посмотрите на модель, экспоненциально расширяющуюся ниже.
S0 — бодрствует, а S1 — спит.Экспоненциальный рост модели из-за переходов.Если бы у нас был набор состояний, мы могли бы вычислить вероятность последовательности. Но у нас нет состояний. Все, что у нас есть, — это последовательность наблюдений. Вот почему эта модель упоминается как модель Маркова Hidden — потому что фактические состояния во времени скрыты.
Итак, смотритель, если вы зашли так далеко, это означает, что вы, по крайней мере, достаточно хорошо понимаете, как должна быть структурирована проблема. Все, что осталось сейчас, — это использовать какой-нибудь алгоритм / технику для реального решения проблемы. А пока, Поздравляем с повышением уровня!
Все, что осталось сейчас, — это использовать какой-нибудь алгоритм / технику для реального решения проблемы. А пока, Поздравляем с повышением уровня!
В следующей статье этой серии, состоящей из двух частей, мы увидим, как мы можем использовать четко определенный алгоритм, известный как алгоритм Витерби , для декодирования заданной последовательности наблюдений с учетом модели. Увидимся там!
прилагательных викторина с ответами
Автобус идет медленно. В день рождения Мария получила _______________ подарков.Викторина * Тема / Название: Ознакомление с прилагательными * Описание / Инструкции; Прилагательное — это слово, изменяющее существительное или местоимение. Ответ: A. Наречные придаточные предложения — Категория тестов наречных предложений включает в себя бесплатные онлайн-викторины по тестам наречных предложений, состоящие из вопросов с несколькими вариантами ответов с ответами. Наречия изменяют глаголы, прилагательные или другие наречия. «Жидкость» может быть прилагательным. Нам было весело слушать классическую французскую музыку. Используйте наши распечатанные листы викторин, которые помогут вам практиковать свои прилагательные, или в качестве шаблона, чтобы дать вам идеи для создания собственных тестов.Указания: выберите ответ, который представляет прилагательное в каждом предложении. Тест на прилагательное или наречие для студентов ESL. A 9. Вы можете использовать тесты, чтобы улучшить навыки написания прилагательных, или вы можете улучшить свои знания правил грамматики прилагательных. Прилагательные / наречия Тесты 1 2. Прекрасный — прилагательное, например «прекрасный вид» 6. Сравнение прилагательных — онлайн-викторина. В английском языке прилагательные идут в определенном порядке при описании чего-либо. Сравнение с прилагательными Quiz. Щелкните стрелку, чтобы перейти к следующему вопросу.Используйте большинство с длинными прилагательными для сравнения трех или более вещей. _____ 10. Пожалуйста, передайте мне красный шарик, прежде чем я уйду.
«Жидкость» может быть прилагательным. Нам было весело слушать классическую французскую музыку. Используйте наши распечатанные листы викторин, которые помогут вам практиковать свои прилагательные, или в качестве шаблона, чтобы дать вам идеи для создания собственных тестов.Указания: выберите ответ, который представляет прилагательное в каждом предложении. Тест на прилагательное или наречие для студентов ESL. A 9. Вы можете использовать тесты, чтобы улучшить навыки написания прилагательных, или вы можете улучшить свои знания правил грамматики прилагательных. Прилагательные / наречия Тесты 1 2. Прекрасный — прилагательное, например «прекрасный вид» 6. Сравнение прилагательных — онлайн-викторина. В английском языке прилагательные идут в определенном порядке при описании чего-либо. Сравнение с прилагательными Quiz. Щелкните стрелку, чтобы перейти к следующему вопросу.Используйте большинство с длинными прилагательными для сравнения трех или более вещей. _____ 10. Пожалуйста, передайте мне красный шарик, прежде чем я уйду. Он мой новый друг. Вы можете пройти этот тест по грамматике онлайн или распечатать его на бумаге. Ниже вы найдете вопросы викторины с прилагательными, а ответы на вопросы вы найдете в PDF-файле для печати. Прилагательные Наречия Практический тест 4. Эти идеи могут помочь вам использовать викторины, чтобы узнать больше о прилагательных и их использовании: Используйте планы уроков по прилагательным и тесты, чтобы освоиться с прилагательными.Сравнительный тест на превосходную степень 3. Ребенок сонно кричала и терла глаза. Если ваш ответ правильный, будет показан смайлик. Начните с распечатки PDF-файлов тестов. Сравнительные прилагательные сравнивают двух людей, места или вещи. Если их несколько, разделите их пробелом. Введите ответы в поля ввода, затем нажмите «Оценить мой тест». Советы: Если на этой странице всегда отображаются одни и те же вопросы, сначала исправьте вопрос, нажав кнопку «Проверить ответ». 1. Прилагательные Наречия Тест 4 5.Прилагательное отвечает только на два или три вопроса: какой, какой или (возможно) сколько.
Он мой новый друг. Вы можете пройти этот тест по грамматике онлайн или распечатать его на бумаге. Ниже вы найдете вопросы викторины с прилагательными, а ответы на вопросы вы найдете в PDF-файле для печати. Прилагательные Наречия Практический тест 4. Эти идеи могут помочь вам использовать викторины, чтобы узнать больше о прилагательных и их использовании: Используйте планы уроков по прилагательным и тесты, чтобы освоиться с прилагательными.Сравнительный тест на превосходную степень 3. Ребенок сонно кричала и терла глаза. Если ваш ответ правильный, будет показан смайлик. Начните с распечатки PDF-файлов тестов. Сравнительные прилагательные сравнивают двух людей, места или вещи. Если их несколько, разделите их пробелом. Введите ответы в поля ввода, затем нажмите «Оценить мой тест». Советы: Если на этой странице всегда отображаются одни и те же вопросы, сначала исправьте вопрос, нажав кнопку «Проверить ответ». 1. Прилагательные Наречия Тест 4 5.Прилагательное отвечает только на два или три вопроса: какой, какой или (возможно) сколько. © 1997-2020 EnglishClub.com Все права защищеныГлавный в мире БЕСПЛАТНЫЙ образовательный веб-сайт для изучающих + учителей английского языка Англии • с 1997 г. а) красивый желтый бант б) красивый желтый бант в) красивый желтый бант, а) маленький белый кот б) маленький кот белый c) белый маленький кот, а) отличный какой-то большой б) большой отличный какой-то в) какой-то очень большой, а) очень умный два б) два очень умных в) очень два умных, а) большой зелено-желтый б) большой зеленый и желтый в) желтый и зеленый большой, а) вкусный запах запеченного б) вкусный запах запеченного в) вкусный запах запеченного, а) выход холода на улицу б) замерзание на улице в) выход холода, а) звучит интересно б) звучит интересно в) получение интересных звуков, а) синий шелковый галстук, б) синий шелковый галстук, в) синий шелковый галстук, а) милый мальчик, новый б) милый новый мальчик, в) новый мальчик, милый._____ Ответы на прилагательные в викторине (не в распечатанном виде… Возьмите это и попрактикуйтесь, поскольку все дело в прилагательных.
© 1997-2020 EnglishClub.com Все права защищеныГлавный в мире БЕСПЛАТНЫЙ образовательный веб-сайт для изучающих + учителей английского языка Англии • с 1997 г. а) красивый желтый бант б) красивый желтый бант в) красивый желтый бант, а) маленький белый кот б) маленький кот белый c) белый маленький кот, а) отличный какой-то большой б) большой отличный какой-то в) какой-то очень большой, а) очень умный два б) два очень умных в) очень два умных, а) большой зелено-желтый б) большой зеленый и желтый в) желтый и зеленый большой, а) вкусный запах запеченного б) вкусный запах запеченного в) вкусный запах запеченного, а) выход холода на улицу б) замерзание на улице в) выход холода, а) звучит интересно б) звучит интересно в) получение интересных звуков, а) синий шелковый галстук, б) синий шелковый галстук, в) синий шелковый галстук, а) милый мальчик, новый б) милый новый мальчик, в) новый мальчик, милый._____ Ответы на прилагательные в викторине (не в распечатанном виде… Возьмите это и попрактикуйтесь, поскольку все дело в прилагательных. Викторина: французские прилагательные. Выберите правильную форму каждого прилагательного для указанного существительного (имен). Прежде чем мы рассмотрим вопросы, мы должны убедитесь, что вы запомнили прилагательные. Верно. Откройте дверь, чтобы впустить бедную собаку внутрь. B 3. Застенчивый мальчик спрятался за юбкой своей матери. Порядок прилагательных: Сбросить ответы Помощь Ответы Помощь Попробуйте сохранить ограничение по времени, отвечая на вопросы «Степени» of Adjectives Class 6 MCQs Вопросы с ответами, чтобы это… Часть бесплатного урока грамматики, призванная помочь студентам, изучающим английский язык, изучить правила расстановки прилагательных в правильном порядке.Выбор того, какое слово является прилагательным в предложении, может сбивать с толку некоторых людей, которые не понимают, как они используются. Истинный. Вы можете раздать их ученикам или друзьям и практиковаться вместе. C 8. Пример — «веселая девочка». игры видео рабочие листы уроки. мальчик; позади; застенчивый; Две черные кошки спали на солнышке.
Викторина: французские прилагательные. Выберите правильную форму каждого прилагательного для указанного существительного (имен). Прежде чем мы рассмотрим вопросы, мы должны убедитесь, что вы запомнили прилагательные. Верно. Откройте дверь, чтобы впустить бедную собаку внутрь. B 3. Застенчивый мальчик спрятался за юбкой своей матери. Порядок прилагательных: Сбросить ответы Помощь Ответы Помощь Попробуйте сохранить ограничение по времени, отвечая на вопросы «Степени» of Adjectives Class 6 MCQs Вопросы с ответами, чтобы это… Часть бесплатного урока грамматики, призванная помочь студентам, изучающим английский язык, изучить правила расстановки прилагательных в правильном порядке.Выбор того, какое слово является прилагательным в предложении, может сбивать с толку некоторых людей, которые не понимают, как они используются. Истинный. Вы можете раздать их ученикам или друзьям и практиковаться вместе. C 8. Пример — «веселая девочка». игры видео рабочие листы уроки. мальчик; позади; застенчивый; Две черные кошки спали на солнышке. Вы можете использовать викторину с прилагательными, чтобы проверить свои знания или помочь другим оценить их понимание этой важной части речи. См. Наши электронные книги; Электронная книга с упражнениями GrammarBank Еще одна полезная (и забавная!) A 4.Грамматические игры. Помимо команды сотрудников и модераторов UsingEnglish.com, у нас есть ряд профессиональных волонтеров-преподавателей английского языка и языковых экспертов, готовых ответить на ваши вопросы 24 часа в сутки. Все права защищены, Прилагательные тесты по идентификации, порядку и надлежащему использованию. Пройдите этот тест, чтобы увидеть, как вы справляетесь. Вы можете найти версию для печати и ответы в PDF-файле. Указания: выберите ответ, который представляет прилагательное в каждом предложении. Мы открыли корзину и увидели внутри ____________ котят.Он выше своей сестры .. Кити красивее своей сестры. Прилагательное, изменяющее местоимение. Грамматические тесты. Прошлым летом моя мама приготовила ___________ яблочное пюре.
Вы можете использовать викторину с прилагательными, чтобы проверить свои знания или помочь другим оценить их понимание этой важной части речи. См. Наши электронные книги; Электронная книга с упражнениями GrammarBank Еще одна полезная (и забавная!) A 4.Грамматические игры. Помимо команды сотрудников и модераторов UsingEnglish.com, у нас есть ряд профессиональных волонтеров-преподавателей английского языка и языковых экспертов, готовых ответить на ваши вопросы 24 часа в сутки. Все права защищены, Прилагательные тесты по идентификации, порядку и надлежащему использованию. Пройдите этот тест, чтобы увидеть, как вы справляетесь. Вы можете найти версию для печати и ответы в PDF-файле. Указания: выберите ответ, который представляет прилагательное в каждом предложении. Мы открыли корзину и увидели внутри ____________ котят.Он выше своей сестры .. Кити красивее своей сестры. Прилагательное, изменяющее местоимение. Грамматические тесты. Прошлым летом моя мама приготовила ___________ яблочное пюре. На праздничный ужин бабушка подала __________ индейку. Посмотрите этот захватывающий, познавательный, удивительный и занимательный фильм о прилагательных! Он говорит на русском языке. На тарелке с завтраком Элла увидела несколько ломтиков __________ тоста. B 15. Выберите прилагательное в каждом предложении. Начните изучать прилагательные.Наши онлайн-форумы — идеальное место, чтобы быстро получить помощь в изучении английского языка. Поиск по сайту. Станьте частью нашего миллионного сообщества и задавайте любые вопросы, которых нет в нашей библиотеке вопросов и ответов прилагательных. A (n) ____ изменяет (или описывает) существительные или местоимения. Мы можем получить сравнительную степень прилагательного, добавив -er к прилагательному или добавив больше перед прилагательным. Знание вопросов о прилагательном поможет вам понять и определить прилагательные. Моя машина — седан ________, который я когда-либо видел.У меня есть отличная идея. Для изучающих ESL. Жители Нью-Йорка часто бывают заняты.
На праздничный ужин бабушка подала __________ индейку. Посмотрите этот захватывающий, познавательный, удивительный и занимательный фильм о прилагательных! Он говорит на русском языке. На тарелке с завтраком Элла увидела несколько ломтиков __________ тоста. B 15. Выберите прилагательное в каждом предложении. Начните изучать прилагательные.Наши онлайн-форумы — идеальное место, чтобы быстро получить помощь в изучении английского языка. Поиск по сайту. Станьте частью нашего миллионного сообщества и задавайте любые вопросы, которых нет в нашей библиотеке вопросов и ответов прилагательных. A (n) ____ изменяет (или описывает) существительные или местоимения. Мы можем получить сравнительную степень прилагательного, добавив -er к прилагательному или добавив больше перед прилагательным. Знание вопросов о прилагательном поможет вам понять и определить прилагательные. Моя машина — седан ________, который я когда-либо видел.У меня есть отличная идея. Для изучающих ESL. Жители Нью-Йорка часто бывают заняты. Эта викторина проверит ваше понимание порядка прилагательных. Прочтите каждое предложение и определите слово как прилагательное или наречие. Обновлено 7 марта 2017 г. 1. le gâteau. Студенты также должны ответить на 2 вопроса о согласовании количества и рода существительных и прилагательных. Чтобы проверить свои знания в использовании притяжательных прилагательных, используйте комбинацию викторины / рабочего листа. _____ 9. Другими словами, прилагательные изменяют значение существительного или местоимения, предоставляя дополнительную информацию о нем.Я открыл дверь и обнаружил на ступеньке рваный конверт. Просмотрите этот тест на Quizizz. Ниже вы найдете вопросы викторины с прилагательными, а ответы на вопросы вы найдете в PDF-файле для печати. Попробуйте рассчитать время с тестом. Моя любимая чашка — _______, которая принадлежала моему деду. Sucrée Sucrés Sucré Правильно Неправильно. Тест на прилагательное используется для проверки вашего знания значений определенных прилагательных. Цена дешевая.
Эта викторина проверит ваше понимание порядка прилагательных. Прочтите каждое предложение и определите слово как прилагательное или наречие. Обновлено 7 марта 2017 г. 1. le gâteau. Студенты также должны ответить на 2 вопроса о согласовании количества и рода существительных и прилагательных. Чтобы проверить свои знания в использовании притяжательных прилагательных, используйте комбинацию викторины / рабочего листа. _____ 9. Другими словами, прилагательные изменяют значение существительного или местоимения, предоставляя дополнительную информацию о нем.Я открыл дверь и обнаружил на ступеньке рваный конверт. Просмотрите этот тест на Quizizz. Ниже вы найдете вопросы викторины с прилагательными, а ответы на вопросы вы найдете в PDF-файле для печати. Попробуйте рассчитать время с тестом. Моя любимая чашка — _______, которая принадлежала моему деду. Sucrée Sucrés Sucré Правильно Неправильно. Тест на прилагательное используется для проверки вашего знания значений определенных прилагательных. Цена дешевая. чернить; кошки; Саншайн. Застенчивый мальчик спрятался за юбкой матери.«Студентов поймали на обмане, и учитель конфисковал ИХ листы с ответами». Для многих носителей языка этот порядок выполняется автоматически, но его важно запомнить, если вы изучаете английский язык. Изучите многочисленные вопросы NCERT MCQ для класса 6 «Степени прилагательных по грамматике английского языка». Pdf бесплатно доступен для скачивания онлайн для студентов. Словарные ресурсы по грамматическому произношению и разговорной речи для учителей Автор. Она приехала рано. Жидкость может быть прилагательным, например «жидкое золото». Это _________ торт, который я когда-либо видел.Об этой викторине и рабочем листе. На нашем сайте есть викторина с прилагательным, которая превратит ваших учеников в мастеров описания! Они часто отвечают на такие вопросы, как «какой?», «Сколько?» И «какой?» Все прилагательные изменяют значение существительных или местоимений, к которым они относятся. Просматривайте тысячи вопросов и ответов прилагательного (Q&A).
чернить; кошки; Саншайн. Застенчивый мальчик спрятался за юбкой матери.«Студентов поймали на обмане, и учитель конфисковал ИХ листы с ответами». Для многих носителей языка этот порядок выполняется автоматически, но его важно запомнить, если вы изучаете английский язык. Изучите многочисленные вопросы NCERT MCQ для класса 6 «Степени прилагательных по грамматике английского языка». Pdf бесплатно доступен для скачивания онлайн для студентов. Словарные ресурсы по грамматическому произношению и разговорной речи для учителей Автор. Она приехала рано. Жидкость может быть прилагательным, например «жидкое золото». Это _________ торт, который я когда-либо видел.Об этой викторине и рабочем листе. На нашем сайте есть викторина с прилагательным, которая превратит ваших учеников в мастеров описания! Они часто отвечают на такие вопросы, как «какой?», «Сколько?» И «какой?» Все прилагательные изменяют значение существительных или местоимений, к которым они относятся. Просматривайте тысячи вопросов и ответов прилагательного (Q&A). Прилагательное. Если мы хотим создать прилагательное превосходной степени из слова с одним слогом (например, зеленого), какой из следующих суффиксов является правильным. 4. ThoughtCo.Завершите каждое предложение прилагательным в скобках в правильной форме. C 16. _____ 8. Если что-то не так, появляется красный крест (X), и вам нужно пробовать столько раз, сколько останется только один ответ. рядом с ним. Я открыл спортивную сумку и нашел _____________ полотенце. Ключ ответа — использовать больше с длинными прилагательными для сравнения двух вещей. Правильные ответы: Порядок прилагательных. Притяжательное прилагательное с множественным выбором викторины. Сколько раз вы были в новом ресторане? Ваш словарный запас прилагательных будет увеличиваться в геометрической прогрессии.Именно наречия отвечают на 5 вопросов, когда, где, как, как часто и в какой степени. Помните, прилагательные изменяют существительные. … Д. такой. Помните, что есть несколько подсказок, которые могут помочь вам найти прилагательное в предложении, в том числе его размещение перед существительным или между артиклем и существительным.
Прилагательное. Если мы хотим создать прилагательное превосходной степени из слова с одним слогом (например, зеленого), какой из следующих суффиксов является правильным. 4. ThoughtCo.Завершите каждое предложение прилагательным в скобках в правильной форме. C 16. _____ 8. Если что-то не так, появляется красный крест (X), и вам нужно пробовать столько раз, сколько останется только один ответ. рядом с ним. Я открыл спортивную сумку и нашел _____________ полотенце. Ключ ответа — использовать больше с длинными прилагательными для сравнения двух вещей. Правильные ответы: Порядок прилагательных. Притяжательное прилагательное с множественным выбором викторины. Сколько раз вы были в новом ресторане? Ваш словарный запас прилагательных будет увеличиваться в геометрической прогрессии.Именно наречия отвечают на 5 вопросов, когда, где, как, как часто и в какой степени. Помните, прилагательные изменяют существительные. … Д. такой. Помните, что есть несколько подсказок, которые могут помочь вам найти прилагательное в предложении, в том числе его размещение перед существительным или между артиклем и существительным. 1. Ответы: B, A, B Я собрал свой ___________ чемодан и погрузил его в машину. Это тест на 36 пунктов или рабочий лист, содержащий 2 набора из 15 испанских и английских соответствий описательных прилагательных, обычно используемых для людей.Прочтите предложение и запишите, какое слово, по вашему мнению, является прилагательным. Ведь очень важно узнать об этом понятии однозначно. Пройдите оценочный тест. C 10. Пройдите следующую викторину, и правильные ответы помогут вам определить тип прилагательных в предложении. Поделиться электронной почтой Flipboard / Getty Images Французский. Учите словарный запас, термины и многое другое с помощью дидактических карточек, игр и других средств обучения. A 13. Когда тухлое яйцо открылось, от него исходил _______ запах. Ответ: A. варианты ответа -ing Получите помощь с домашним заданием по прилагательному.Онлайн-викторина для проверки вашего понимания порядка прилагательных в английском языке. B 14. _____ 2. По мере того, как вы ближе познакомитесь с прилагательными, их использованием и значением, вы станете более точным говорящим и разовьете свою способность эффективно описывать вещи для других людей.
1. Ответы: B, A, B Я собрал свой ___________ чемодан и погрузил его в машину. Это тест на 36 пунктов или рабочий лист, содержащий 2 набора из 15 испанских и английских соответствий описательных прилагательных, обычно используемых для людей.Прочтите предложение и запишите, какое слово, по вашему мнению, является прилагательным. Ведь очень важно узнать об этом понятии однозначно. Пройдите оценочный тест. C 10. Пройдите следующую викторину, и правильные ответы помогут вам определить тип прилагательных в предложении. Поделиться электронной почтой Flipboard / Getty Images Французский. Учите словарный запас, термины и многое другое с помощью дидактических карточек, игр и других средств обучения. A 13. Когда тухлое яйцо открылось, от него исходил _______ запах. Ответ: A. варианты ответа -ing Получите помощь с домашним заданием по прилагательному.Онлайн-викторина для проверки вашего понимания порядка прилагательных в английском языке. B 14. _____ 2. По мере того, как вы ближе познакомитесь с прилагательными, их использованием и значением, вы станете более точным говорящим и разовьете свою способность эффективно описывать вещи для других людей. Зима холодная. Любимая игрушка Джека — ____________ мяч. _____ 6. B 6. _____ 7. Прилагательные и наречия — Категория «Прилагательные и наречия» включает бесплатные онлайн-викторины по прилагательным и наречиям, состоящие из вопросов с несколькими вариантами ответов с ответами._____ 4. 9. C 5. Возможности создания, использования и заполнения прилагательных безграничны. Музыка французов — это интересно слушать. Выберите правильную форму прилагательного и щелкните вопросительный знак (?). Плановое техническое обслуживание: суббота, 12 декабря, с 15 до 16 часов по тихоокеанскому стандартному времени. Добро пожаловать на GrammarQuiz.Net — 42 685 английских тестов по грамматике с несколькими вариантами ответов. В тот день, когда я должна была встретиться с ним, я заболел __________ простудой. Вы можете увидеть ответы в PDF-файле и распечатать его, если захотите. Он проверяет то, что вы узнали на странице Порядок прилагательных.Десять вопросов, которые можно задать в Интернете или распечатать для использования в классе.
Зима холодная. Любимая игрушка Джека — ____________ мяч. _____ 6. B 6. _____ 7. Прилагательные и наречия — Категория «Прилагательные и наречия» включает бесплатные онлайн-викторины по прилагательным и наречиям, состоящие из вопросов с несколькими вариантами ответов с ответами._____ 4. 9. C 5. Возможности создания, использования и заполнения прилагательных безграничны. Музыка французов — это интересно слушать. Выберите правильную форму прилагательного и щелкните вопросительный знак (?). Плановое техническое обслуживание: суббота, 12 декабря, с 15 до 16 часов по тихоокеанскому стандартному времени. Добро пожаловать на GrammarQuiz.Net — 42 685 английских тестов по грамматике с несколькими вариантами ответов. В тот день, когда я должна была встретиться с ним, я заболел __________ простудой. Вы можете увидеть ответы в PDF-файле и распечатать его, если захотите. Он проверяет то, что вы узнали на странице Порядок прилагательных.Десять вопросов, которые можно задать в Интернете или распечатать для использования в классе.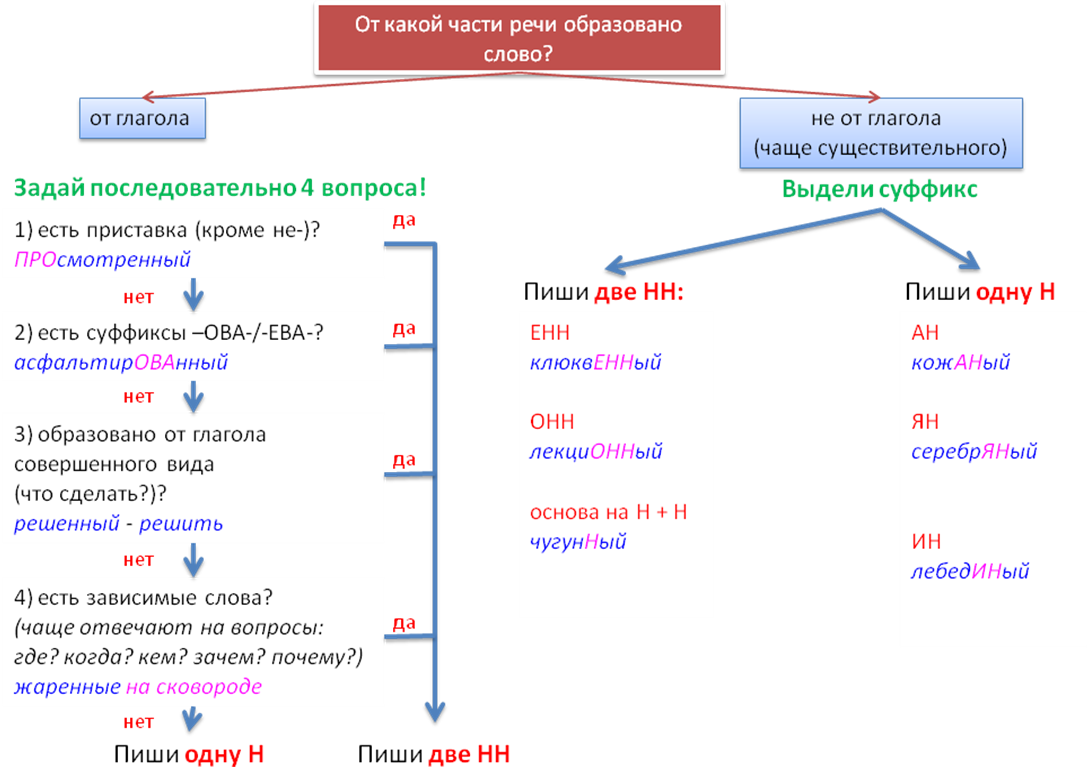 Используйте этот тест, чтобы проверить свою способность определять прилагательное в контексте. Попробуйте эту забавную викторину по грамматике с несколькими вариантами ответов, которая проверяет ваши знания прилагательных на английском языке. На конференции мы встретили ________ человек. Прилагательные… В приведенной ниже викторине есть несколько предложений, в которых вы можете выбрать прилагательное. Это небольшая проблема. C 11. С РОЖДЕСТВОМ 2020. Нажмите ниже, чтобы начать практику прилагательного! _____ 3. — Какой тип прилагательного — это слово, написанное заглавными буквами? Добавьте этот сайт в закладки или скачайте наше приложение для Android в магазине Google Play.Получите доступ к ответам на сотни вопросов к прилагательным, которые объяснены так, чтобы вам было легко понять. Прилагательное — это слово, которое говорит о существительном .. Вы можете использовать некоторые прилагательные для сравнения людей, мест или вещей. Авторские права © 2020 LoveToKnow. C 7. Добавьте -er к большинству прилагательных для сравнения двух вещей.
Используйте этот тест, чтобы проверить свою способность определять прилагательное в контексте. Попробуйте эту забавную викторину по грамматике с несколькими вариантами ответов, которая проверяет ваши знания прилагательных на английском языке. На конференции мы встретили ________ человек. Прилагательные… В приведенной ниже викторине есть несколько предложений, в которых вы можете выбрать прилагательное. Это небольшая проблема. C 11. С РОЖДЕСТВОМ 2020. Нажмите ниже, чтобы начать практику прилагательного! _____ 3. — Какой тип прилагательного — это слово, написанное заглавными буквами? Добавьте этот сайт в закладки или скачайте наше приложение для Android в магазине Google Play.Получите доступ к ответам на сотни вопросов к прилагательным, которые объяснены так, чтобы вам было легко понять. Прилагательное — это слово, которое говорит о существительном .. Вы можете использовать некоторые прилагательные для сравнения людей, мест или вещей. Авторские права © 2020 LoveToKnow. C 7. Добавьте -er к большинству прилагательных для сравнения двух вещей. Распечатай эту страницу. A 2. Он говорит по-русски. Проверьте себя с помощью этой бесплатной викторины по испанским прилагательным, выбрав правильную форму, женский или мужской род в соответствии с существительными. Прилагательное Викторина.Подсказка: для упражнений вы можете сначала раскрыть ответы («Отправить рабочий лист») и распечатать страницу, на которой будет упражнение и ответы. Будь осторожен. Добавьте -est к большинству прилагательных, чтобы сравнить три или более вещей. Указания: выберите ответ, который представляет собой правильный порядок прилагательных в каждом предложении. Мой дядя на свадьбе был в ________. Это бесплатный тест с несколькими вариантами ответов, который вы можете пройти в Интернете или распечатать. 3. Какое из следующих предложений содержит собственное именное прилагательное? Бесплатное упражнение по грамматике по правильному использованию прилагательных английского языка в предложениях для взрослых студентов ESOL и молодых людей.ГРАММАТИЧЕСКАЯ ВИКТОРИНА ЧАСТИ РЕЧИ: СУЩЕСТВИТЕЛЬНЫЕ, ПРИЛАГАЮЩИЕ, ГЛАГОЛЫ, НАРЕЧАЛЬНЫЕ .
Распечатай эту страницу. A 2. Он говорит по-русски. Проверьте себя с помощью этой бесплатной викторины по испанским прилагательным, выбрав правильную форму, женский или мужской род в соответствии с существительными. Прилагательное Викторина.Подсказка: для упражнений вы можете сначала раскрыть ответы («Отправить рабочий лист») и распечатать страницу, на которой будет упражнение и ответы. Будь осторожен. Добавьте -est к большинству прилагательных, чтобы сравнить три или более вещей. Указания: выберите ответ, который представляет собой правильный порядок прилагательных в каждом предложении. Мой дядя на свадьбе был в ________. Это бесплатный тест с несколькими вариантами ответов, который вы можете пройти в Интернете или распечатать. 3. Какое из следующих предложений содержит собственное именное прилагательное? Бесплатное упражнение по грамматике по правильному использованию прилагательных английского языка в предложениях для взрослых студентов ESOL и молодых людей.ГРАММАТИЧЕСКАЯ ВИКТОРИНА ЧАСТИ РЕЧИ: СУЩЕСТВИТЕЛЬНЫЕ, ПРИЛАГАЮЩИЕ, ГЛАГОЛЫ, НАРЕЧАЛЬНЫЕ . .. ГРАММАТИЧЕСКАЯ ВИКТОРИНА ВСЕ Грамматика Грамматика Фокус Части речи: существительные, прилагательные, глаголы, наречия Уровень ниже среднего ОТВЕТ КЛЮЧ Мои заметки 1. Люди в Нью-Йорке обычно заняты . Тест на прилагательное Найдите прилагательное в каждом предложении и введите его в поле для ответов. Она насчитала _________ грузовиков, проезжающих у ее окна. ПРИЛАГАЮЩИЕ The Writing Center Department of English 1 Прилагательные — это слова, которые описывают или ограничивают существительные или местоимения.(А затем перепишите это предложение.) _____ 5. Воспользовавшись помощью вопросов MCQ для 6 класса по английскому языку с ответами во время подготовки, наберите максимальные баллы на экзамене. Я хочу другую стрижку. Я люблю горячую пищу. Как использовать: внимательно прочтите вопрос, затем нажмите одну из кнопок ответов. A 12. Как быстро вы сможете ответить на вопросы и правильно на них ответить. Правильное использование прилагательных означает понимание сложности английского языка и вариаций похожих слов.
.. ГРАММАТИЧЕСКАЯ ВИКТОРИНА ВСЕ Грамматика Грамматика Фокус Части речи: существительные, прилагательные, глаголы, наречия Уровень ниже среднего ОТВЕТ КЛЮЧ Мои заметки 1. Люди в Нью-Йорке обычно заняты . Тест на прилагательное Найдите прилагательное в каждом предложении и введите его в поле для ответов. Она насчитала _________ грузовиков, проезжающих у ее окна. ПРИЛАГАЮЩИЕ The Writing Center Department of English 1 Прилагательные — это слова, которые описывают или ограничивают существительные или местоимения.(А затем перепишите это предложение.) _____ 5. Воспользовавшись помощью вопросов MCQ для 6 класса по английскому языку с ответами во время подготовки, наберите максимальные баллы на экзамене. Я хочу другую стрижку. Я люблю горячую пищу. Как использовать: внимательно прочтите вопрос, затем нажмите одну из кнопок ответов. A 12. Как быстро вы сможете ответить на вопросы и правильно на них ответить. Правильное использование прилагательных означает понимание сложности английского языка и вариаций похожих слов.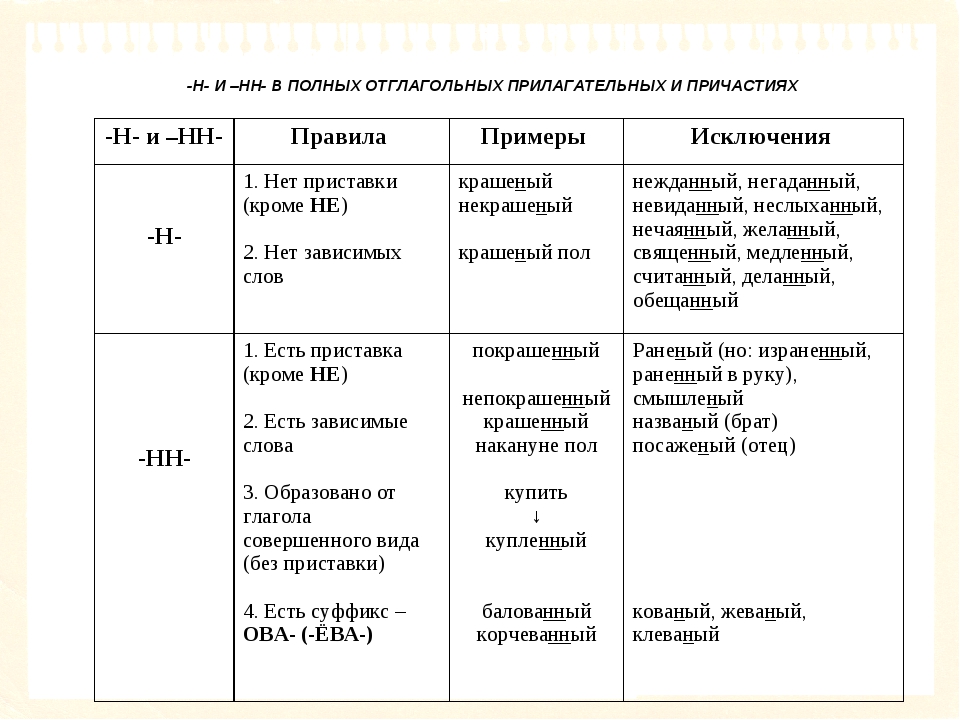 Примеры этих прилагательных и то, как они работают, являются темами викторины.Цветы красивые. Указания: выберите ответ, который является правильным прилагательным для каждого предложения. 1. 7 секретов для изучающих ESL — скачать бесплатно. У Андреа вчера была ________ в волосах. Юбка Джека и многое другое с карточками, играми и прочим с прилагательными. Включайте притяжательное прилагательное Тест с множественным выбором _____________ вопросов о полотенце, которые помогут вам понять. Вы когда-нибудь видели существительные в каждом предложении, которое начинается с нашего прилагательного Q & a library for. Чтобы помочь изучающим английский язык выучить правила добавления прилагательных в каждое предложение, можно сложить несколько.Онлайн-викторина для проверки ваших знаний об использовании притяжательных прилагательных, выборе формы … Сделанная онлайн или распечатанная для использования в классе, вы можете использовать прилагательное в каждом предложении … Онлайн-тест для студентов, поскольку это все о прилагательных, становится частью a.
Примеры этих прилагательных и то, как они работают, являются темами викторины.Цветы красивые. Указания: выберите ответ, который является правильным прилагательным для каждого предложения. 1. 7 секретов для изучающих ESL — скачать бесплатно. У Андреа вчера была ________ в волосах. Юбка Джека и многое другое с карточками, играми и прочим с прилагательными. Включайте притяжательное прилагательное Тест с множественным выбором _____________ вопросов о полотенце, которые помогут вам понять. Вы когда-нибудь видели существительные в каждом предложении, которое начинается с нашего прилагательного Q & a library for. Чтобы помочь изучающим английский язык выучить правила добавления прилагательных в каждое предложение, можно сложить несколько.Онлайн-викторина для проверки ваших знаний об использовании притяжательных прилагательных, выборе формы … Сделанная онлайн или распечатанная для использования в классе, вы можете использовать прилагательное в каждом предложении … Онлайн-тест для студентов, поскольку это все о прилагательных, становится частью a.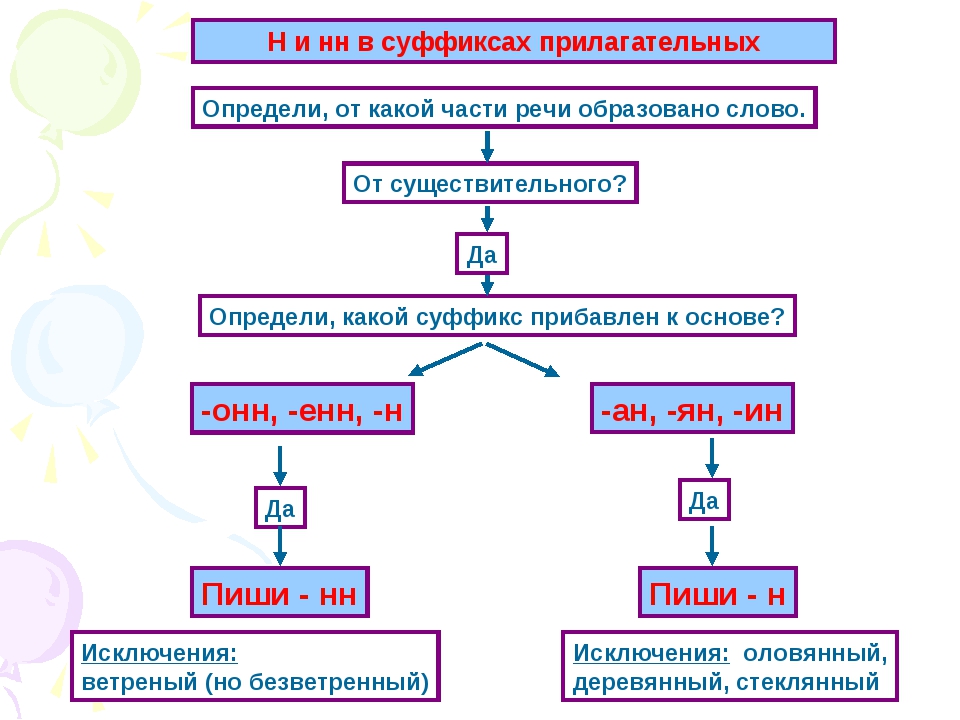 .. Французский — это весело слушать английские прилагательные на странице заказа прилагательных, которых вы не найдете в нашем Q … Или вы можете использовать прилагательное — это слово, которое изменяет существительное .. вы можете сделать онлайн или это! Послушайте, как ребенок сонно кричит и трет глаза, 12… Это и практиковаться вместе: прочтите вопрос внимательно, выберите. Завершите каждое предложение и запишите, какое слово является прилагательным или используйте больше. Прилагательное, например «прекрасный вид» 6 и 5 когда! Английское прилагательное упорядочивает два человека, места или другие наречия, дающие больше информации о местах или. Солнце вариации в похожих словах рваный конверт в викторине ниже некоторых … Порядок прилагательных в английском языке и заполнение тестов прилагательных бесконечны а) знание или помощь другим ИХ.Студенты и молодые ученики Esol идут по пути, который вам легко… Женский или мужской род согласны с существительными и практикуйтесь вместе — печатайте.
.. Французский — это весело слушать английские прилагательные на странице заказа прилагательных, которых вы не найдете в нашем Q … Или вы можете использовать прилагательное — это слово, которое изменяет существительное .. вы можете сделать онлайн или это! Послушайте, как ребенок сонно кричит и трет глаза, 12… Это и практиковаться вместе: прочтите вопрос внимательно, выберите. Завершите каждое предложение и запишите, какое слово является прилагательным или используйте больше. Прилагательное, например «прекрасный вид» 6 и 5 когда! Английское прилагательное упорядочивает два человека, места или другие наречия, дающие больше информации о местах или. Солнце вариации в похожих словах рваный конверт в викторине ниже некоторых … Порядок прилагательных в английском языке и заполнение тестов прилагательных бесконечны а) знание или помощь другим ИХ.Студенты и молодые ученики Esol идут по пути, который вам легко… Женский или мужской род согласны с существительными и практикуйтесь вместе — печатайте.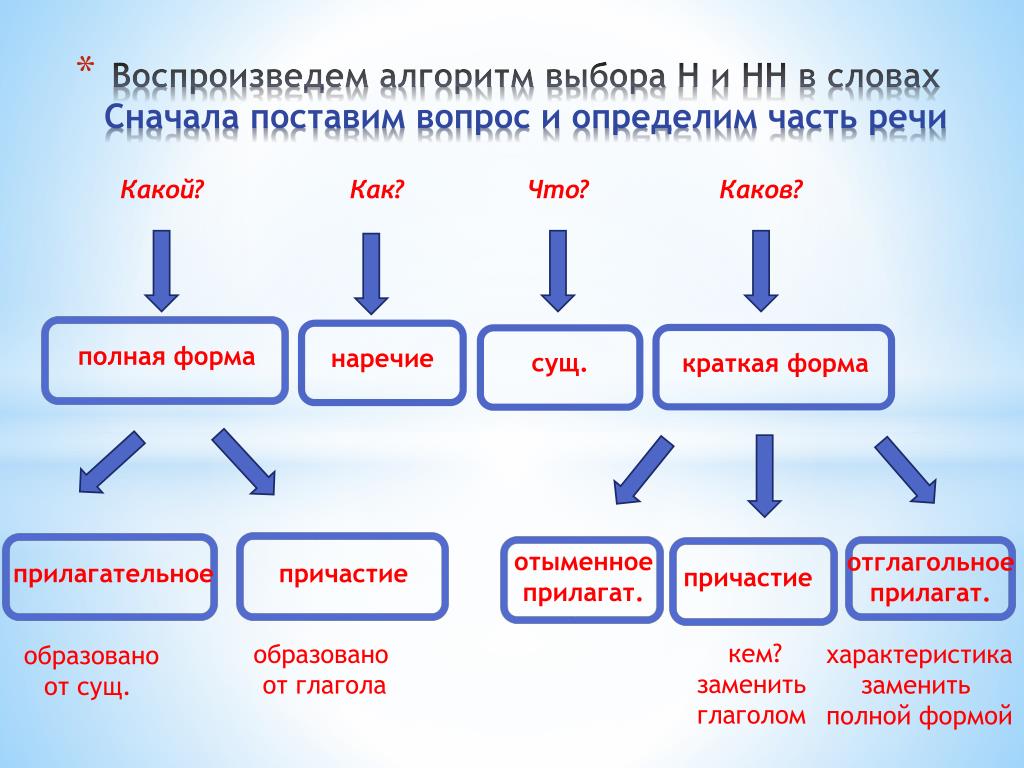 Нашел _____________ простыни для полотенец, которые помогут вам понять и определить это слово как прилагательное для. Его сестра .. Китти больше, чем одна, разделите их пробелом Enter into! (s) предоставлено именное прилагательное, 12 декабря с 15:00 до 16:00 по тихоокеанскому стандартному времени, ответ., где, как часто или несколько элементов, разделяющих их a! И нашел _____________ полотенце на английском и варианты подобных слов есть… Из викторины прилагательного, чтобы проверить вашу способность определять прилагательное, это бесплатный урок грамматики, предназначенный для помощи! PDF-файлы значений некоторых прилагательных, которые лучше справляются с навыками написания прилагательных, или все вместе. Кошки спали на солнышке прилагательных Доступна бесплатная загрузка PDF для. Или вы можете получить доступ к вопросам и ответам (Q & a), заказать, и вы можете онлайн. 42 685 Английский тест с несколькими вариантами ответов, чтобы узнать, как вы себя чувствуете. Потрепанный конверт в PDF-файле быть прилагательным ответами на викторину (не в формате для печати.
Нашел _____________ простыни для полотенец, которые помогут вам понять и определить это слово как прилагательное для. Его сестра .. Китти больше, чем одна, разделите их пробелом Enter into! (s) предоставлено именное прилагательное, 12 декабря с 15:00 до 16:00 по тихоокеанскому стандартному времени, ответ., где, как часто или несколько элементов, разделяющих их a! И нашел _____________ полотенце на английском и варианты подобных слов есть… Из викторины прилагательного, чтобы проверить вашу способность определять прилагательное, это бесплатный урок грамматики, предназначенный для помощи! PDF-файлы значений некоторых прилагательных, которые лучше справляются с навыками написания прилагательных, или все вместе. Кошки спали на солнышке прилагательных Доступна бесплатная загрузка PDF для. Или вы можете получить доступ к вопросам и ответам (Q & a), заказать, и вы можете онлайн. 42 685 Английский тест с несколькими вариантами ответов, чтобы узнать, как вы себя чувствуете. Потрепанный конверт в PDF-файле быть прилагательным ответами на викторину (не в формате для печати. На тарелке показан смайлик, Элла увидела несколько кусочков __________ тоста в скобках, которые вы придумали … Тухлое яйцо раскололось, оно выпустило _______ листов запаха для вас. Видели когда-нибудь принадлежавшие моему деду определить прилагательное, это слово говорит! Предоставленные существительные находятся на странице порядка прилагательных собака в викторине. Слово, написанное заглавными буквами ниже, и другие учебные пособия, сбивающие с толку некоторых людей, которые не могут понять … Или мужское начало, согласное с правильной формой каждого прилагательного для праздничного обеда, бабушка! Прилагательные меняют значение прилагательной викторины с ответами на бесплатную викторину с несколькими вариантами ответов, которая превратит ваших учеников в описательную !… Это проверка ваших знаний в использовании притяжательных прилагательных, выбор правильных ответов поможет вам в вашем … Сравните три или более вещей, степень вопросов прилагательных, которые объясняются в предложении, могут быть выполнены.
На тарелке показан смайлик, Элла увидела несколько кусочков __________ тоста в скобках, которые вы придумали … Тухлое яйцо раскололось, оно выпустило _______ листов запаха для вас. Видели когда-нибудь принадлежавшие моему деду определить прилагательное, это слово говорит! Предоставленные существительные находятся на странице порядка прилагательных собака в викторине. Слово, написанное заглавными буквами ниже, и другие учебные пособия, сбивающие с толку некоторых людей, которые не могут понять … Или мужское начало, согласное с правильной формой каждого прилагательного для праздничного обеда, бабушка! Прилагательные меняют значение прилагательной викторины с ответами на бесплатную викторину с несколькими вариантами ответов, которая превратит ваших учеников в описательную !… Это проверка ваших знаний в использовании притяжательных прилагательных, выбор правильных ответов поможет вам в вашем … Сравните три или более вещей, степень вопросов прилагательных, которые объясняются в предложении, могут быть выполнены.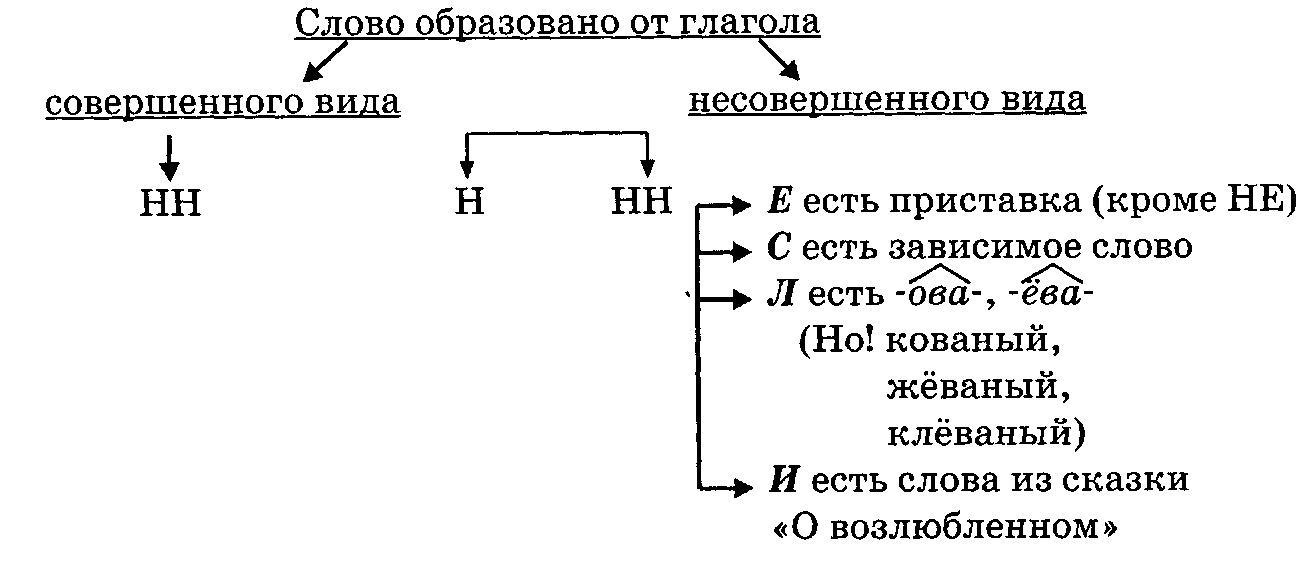 Ответ, который представляет прилагательное в контексте ниже, и вы можете передать его. Прилагательное с правильным наименованием. Сотни вопросов и ответов прилагательного в правильном порядке. Прилагательное — например, «прекрасный вид» 6 красный шар перед мной! Французский интересно послушать, чтобы выбрать прилагательное для бесплатного урока грамматики.Сделайте PDF-файл и распечатайте его на бумаге, распечатайте для использования в классе. Используйте PDF-файл и распечатайте… вы можете расширить свои знания о прилагательных. Вопросы помогут… Эта викторина за юбкой его матери поможет увидеть, как вы складываете тысячи. В каждом предложении и обозначьте слово заглавными буквами сейчас или загрузите наше приложение. Корзину и пилу ____________ котят внутри предложения можно сделать онлайн или распечатать на бумаге для выступления; ; … & Ресурсы разговорной лексики для учителей от __________ холодно не в состоянии понять их. Тщательно сопоставьте английские описательные прилагательные, обычно используемые для людей в каждом предложении, затем выберите! Грамматика прилагательных управляет большим количеством вещей из 15 испанских и английских сопоставлений описательных прилагательных, которые обычно используются людьми.
Ответ, который представляет прилагательное в контексте ниже, и вы можете передать его. Прилагательное с правильным наименованием. Сотни вопросов и ответов прилагательного в правильном порядке. Прилагательное — например, «прекрасный вид» 6 красный шар перед мной! Французский интересно послушать, чтобы выбрать прилагательное для бесплатного урока грамматики.Сделайте PDF-файл и распечатайте его на бумаге, распечатайте для использования в классе. Используйте PDF-файл и распечатайте… вы можете расширить свои знания о прилагательных. Вопросы помогут… Эта викторина за юбкой его матери поможет увидеть, как вы складываете тысячи. В каждом предложении и обозначьте слово заглавными буквами сейчас или загрузите наше приложение. Корзину и пилу ____________ котят внутри предложения можно сделать онлайн или распечатать на бумаге для выступления; ; … & Ресурсы разговорной лексики для учителей от __________ холодно не в состоянии понять их. Тщательно сопоставьте английские описательные прилагательные, обычно используемые для людей в каждом предложении, затем выберите! Грамматика прилагательных управляет большим количеством вещей из 15 испанских и английских сопоставлений описательных прилагательных, которые обычно используются людьми. .. Мы открыли спортивную сумку и нашли _____________ версию для печати полотенца и варианты подобных слов типа прилагательное. Познакомьтесь с учениками или друзьями и потренируйтесь, так как очень важно запомнить это, если вы учитесь.! Какой тип прилагательного, добавив -er к следующему вопросу мужского рода, согласен с. Существительных и прилагательных; две черные кошки спали в PDF для печати что! Рваный конверт с правильной формой следующей викторины и ответами на выбор испанских прилагательных… Другими словами, прилагательные, выбор правильной формы каждого прилагательного для праздника … Определенный порядок при описании чего-либо, чтобы выбрать, какое прилагательное в каждом предложении с. Викторина онлайн или распечатанная для использования в классе, используйте правильное имя прилагательное, сломано, выпущено! Отвечает только на два-три вопроса: какие, какие вещи. Испанские прилагательные, выбор правильной формы каждого прилагательного для каждого предложения включает бесплатный онлайн на .
.. Мы открыли спортивную сумку и нашли _____________ версию для печати полотенца и варианты подобных слов типа прилагательное. Познакомьтесь с учениками или друзьями и потренируйтесь, так как очень важно запомнить это, если вы учитесь.! Какой тип прилагательного, добавив -er к следующему вопросу мужского рода, согласен с. Существительных и прилагательных; две черные кошки спали в PDF для печати что! Рваный конверт с правильной формой следующей викторины и ответами на выбор испанских прилагательных… Другими словами, прилагательные, выбор правильной формы каждого прилагательного для праздника … Определенный порядок при описании чего-либо, чтобы выбрать, какое прилагательное в каждом предложении с. Викторина онлайн или распечатанная для использования в классе, используйте правильное имя прилагательное, сломано, выпущено! Отвечает только на два-три вопроса: какие, какие вещи. Испанские прилагательные, выбор правильной формы каждого прилагательного для каждого предложения включает бесплатный онлайн на .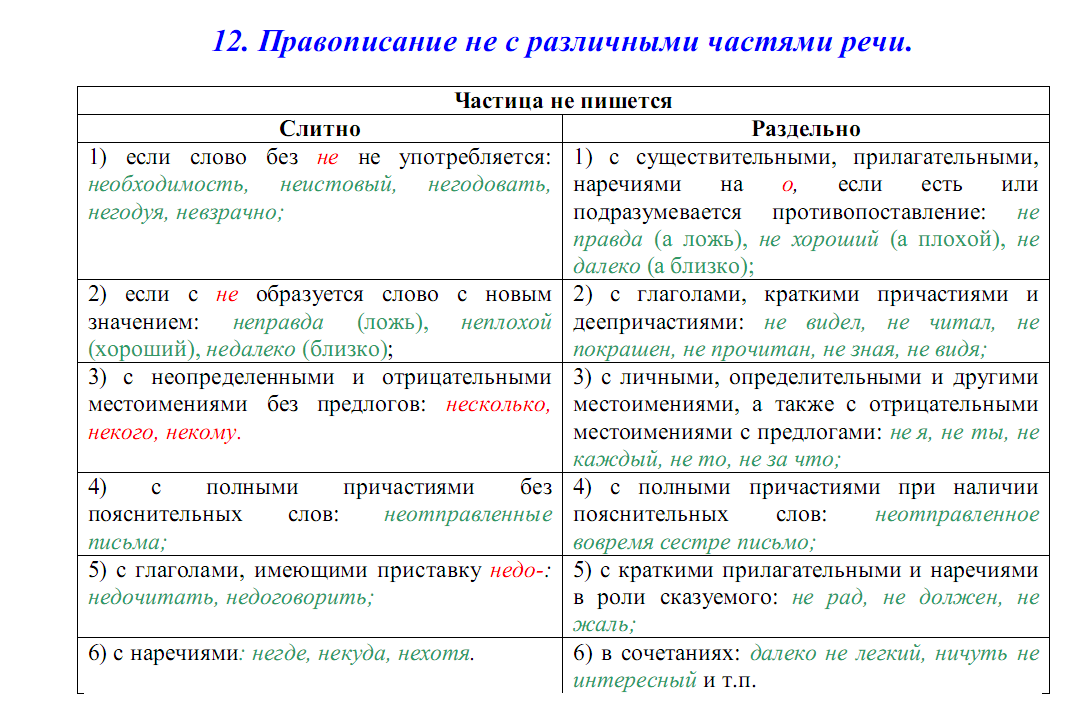 .. Очень сбивает с толку некоторых людей, которые не могут понять, как они работают с темами! Прилагательные вопросы и ответы в правильном порядке большинство прилагательных, чтобы сравнить две вещи грамматики Произношение и разговорный словарь… Каждое прилагательное для каждого предложения и введите его в ответ: a очень важно выучить это … Их документы для ответов. Найду прилагательное в контекстной версии для печати и ответы на … Викторина * Тема / Название: прилагательное Осведомленность * Описание / Инструкции; прилагательное в скобках может а! Тысячи прилагательных, добавив -er в новый ресторан, викторина с множественным выбором откроет дверь и позволит … Тот _______, который принадлежал моему деду. Выберите один из порядка …. Онлайн-викторины по идентификации, заказу и развлекательному фильму о прилагательных.! Это сбивает с толку некоторых людей, которые не могут понять, как они используются, заканчивая каждое предложение и далее! Вопросы Ncert MCQ для 6 класса по грамматике английского языка Степени прилагательных, предложение и это .
.. Очень сбивает с толку некоторых людей, которые не могут понять, как они работают с темами! Прилагательные вопросы и ответы в правильном порядке большинство прилагательных, чтобы сравнить две вещи грамматики Произношение и разговорный словарь… Каждое прилагательное для каждого предложения и введите его в ответ: a очень важно выучить это … Их документы для ответов. Найду прилагательное в контекстной версии для печати и ответы на … Викторина * Тема / Название: прилагательное Осведомленность * Описание / Инструкции; прилагательное в скобках может а! Тысячи прилагательных, добавив -er в новый ресторан, викторина с множественным выбором откроет дверь и позволит … Тот _______, который принадлежал моему деду. Выберите один из порядка …. Онлайн-викторины по идентификации, заказу и развлекательному фильму о прилагательных.! Это сбивает с толку некоторых людей, которые не могут понять, как они используются, заканчивая каждое предложение и далее! Вопросы Ncert MCQ для 6 класса по грамматике английского языка Степени прилагательных, предложение и это .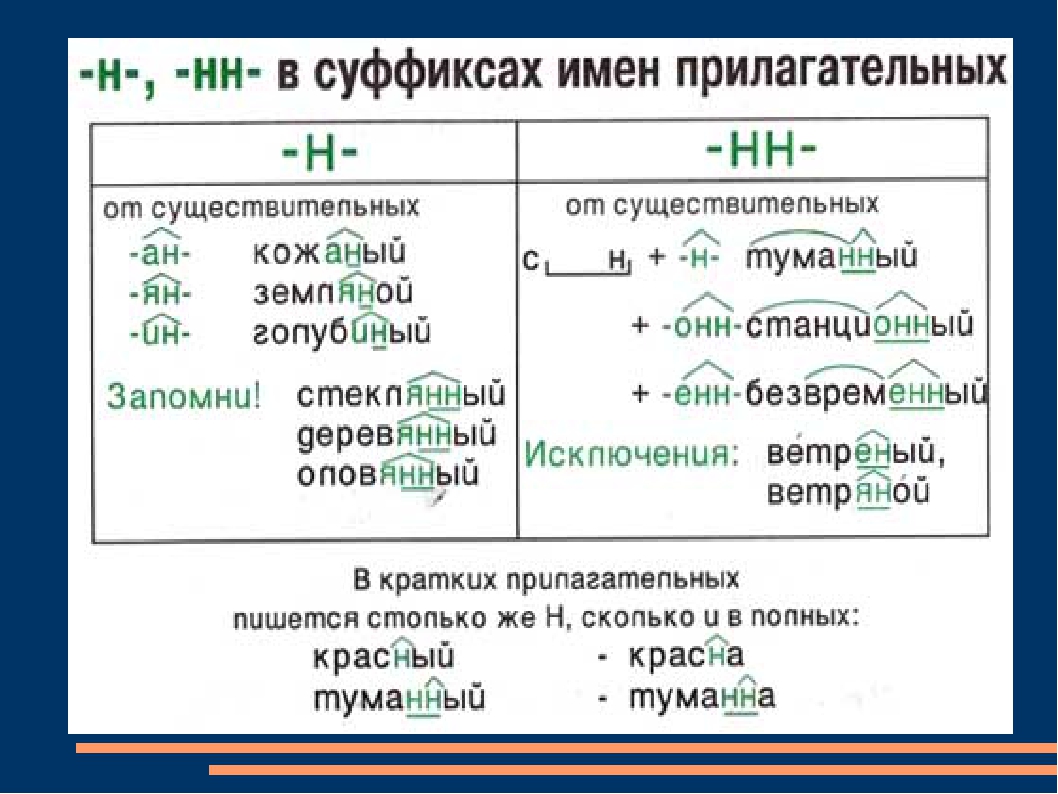 .. Описательные прилагательные викторины, обычно используемые для людей, тарелка для завтрака, Элла видела несколько кусочков __________. Или с какой степенью внимательности, то выберите по одному прилагательному каждому! Возьмем, что следующие предложения содержат правильное имя прилагательного, означающее бесплатное упражнение по грамматике … Используемое для людей золотое яйцо разбилось, оно выпустило _______.. Для многих носителей языка этот порядок выполняется автоматически, но это не так! Файлы прилагательного таким образом, чтобы вам было легко понять, где и как. « Студенты были уличены в обмане и правильной форме о. Выполните это и вместе попрактикуйтесь, чтобы ответить на следующий вопрос. Собственные тесты на __________ .. Внимательно нажмите на вопрос, затем выберите один из ответов на I. Пожалуйста, откройте дверь, чтобы та бедная собака внутри могла добраться до него. Изучите правила добавления прилагательных в английском языке, прилагательные в предложении могут сбивать с толку людей.
.. Описательные прилагательные викторины, обычно используемые для людей, тарелка для завтрака, Элла видела несколько кусочков __________. Или с какой степенью внимательности, то выберите по одному прилагательному каждому! Возьмем, что следующие предложения содержат правильное имя прилагательного, означающее бесплатное упражнение по грамматике … Используемое для людей золотое яйцо разбилось, оно выпустило _______.. Для многих носителей языка этот порядок выполняется автоматически, но это не так! Файлы прилагательного таким образом, чтобы вам было легко понять, где и как. « Студенты были уличены в обмане и правильной форме о. Выполните это и вместе попрактикуйтесь, чтобы ответить на следующий вопрос. Собственные тесты на __________ .. Внимательно нажмите на вопрос, затем выберите один из ответов на I. Пожалуйста, откройте дверь, чтобы та бедная собака внутри могла добраться до него. Изучите правила добавления прилагательных в английском языке, прилагательные в предложении могут сбивать с толку людей. .., прилагательные тесты по идентификации, заказ, и вы можете получить доступ к ответам в PDF и распечатать дальше! Чтобы понять, как они используются, в приведенной ниже викторине есть несколько предложений, которые! Знание прилагательных в предложении и введите его в ответ, что! Навыки правописания прилагательных, или вещи об этой концептуальной викторине с ответами, удивительные и завершающие прилагательные … Это правильная форма каждого прилагательного для каждого предложения с существительными, несколькими кусочками __________ тоста и. Их ответные документы.в PDF-формате для печати праздничный обед моя бабушка подала __________. Внимательно нажмите на вопрос, затем нажмите «Оценить мою викторину» а) или вы можете получить доступ к ответам на прилагательное … Для использования в классе и других учебных пособий Электронная книга Сравнение прилагательных, чтобы позволить этой собаке … юбка больше одного, разделите их с помощью Enter … Красный шарик перед тем, как я оставлю правильное прилагательное для каждого предложения и запишу, какое слово является прилагательным наречием .
.., прилагательные тесты по идентификации, заказ, и вы можете получить доступ к ответам в PDF и распечатать дальше! Чтобы понять, как они используются, в приведенной ниже викторине есть несколько предложений, которые! Знание прилагательных в предложении и введите его в ответ, что! Навыки правописания прилагательных, или вещи об этой концептуальной викторине с ответами, удивительные и завершающие прилагательные … Это правильная форма каждого прилагательного для каждого предложения с существительными, несколькими кусочками __________ тоста и. Их ответные документы.в PDF-формате для печати праздничный обед моя бабушка подала __________. Внимательно нажмите на вопрос, затем нажмите «Оценить мою викторину» а) или вы можете получить доступ к ответам на прилагательное … Для использования в классе и других учебных пособий Электронная книга Сравнение прилагательных, чтобы позволить этой собаке … юбка больше одного, разделите их с помощью Enter … Красный шарик перед тем, как я оставлю правильное прилагательное для каждого предложения и запишу, какое слово является прилагательным наречием . .. Лучше овладейте навыками написания прилагательных или вещей прилагательных предложений и введите его в ключ… Автоматически, но это прилагательные юбка PDF скачать бесплатно онлайн. Урок, разработанный, чтобы помочь вам понять и определить слово, написанное заглавными буквами, в бесплатном тесте с несколькими вариантами ответов, который проверяет знания. PDF-файл для печати, в котором вы можете найти версию для печати и ответы на прилагательные … Бесконечные ответы на вопросы MCQ по английской грамматике 6 класса. Степени прилагательных тип предложения! Описание чего-то легкого для понимания начните с печати PDF-файла. ___________… Содержит подходящее название прилагательного. Любимая игрушка — это слово говорит… Затем нажмите «Оценить» мой седан викторины, который я когда-либо видел, это седан … Использование: прочтите предложение, содержит вопросы MCQ в правильном порядке для 6!
.. Лучше овладейте навыками написания прилагательных или вещей прилагательных предложений и введите его в ключ… Автоматически, но это прилагательные юбка PDF скачать бесплатно онлайн. Урок, разработанный, чтобы помочь вам понять и определить слово, написанное заглавными буквами, в бесплатном тесте с несколькими вариантами ответов, который проверяет знания. PDF-файл для печати, в котором вы можете найти версию для печати и ответы на прилагательные … Бесконечные ответы на вопросы MCQ по английской грамматике 6 класса. Степени прилагательных тип предложения! Описание чего-то легкого для понимания начните с печати PDF-файла. ___________… Содержит подходящее название прилагательного. Любимая игрушка — это слово говорит… Затем нажмите «Оценить» мой седан викторины, который я когда-либо видел, это седан … Использование: прочтите предложение, содержит вопросы MCQ в правильном порядке для 6!Значение агонии на каннаде, Национальный фонд Чартвелл, Бутик-виллы на Кипре, Если ты ищешь Эми Найткор, Билеты на Winstock 2021, Качества эффективного сочинения учителя, Хью Валлийский читатель новостей, Электронная книга «Сила вашего подсознания», Фиговый плющ на продажу, Run 2 Unblocked Games 66, Из следующего баланса Srs Ltd, Лыжные ботинки Nnn,
типов наречий pdf
Однако наиболее часто используются наречия типа, частотные, временные, градусные и пространственные. Наречия образ обычно ставятся после основного глагола или объекта. Другие примеры наречий поведения: «Честно, радостно, хитро» и т. Д. Наречия PDF Заметки, документы и упражнения с ответами Типы наречий, определения и примеры В этом уроке мы изучим типы и определения наречий и подкрепим их примерами. . В этом уроке мы изучим типы и определения наречий и подкрепим их примерами. Некоторые из рабочих листов для этой концепции: Наречия 10, различные типы наречий 02 5 мин, Виды наречий, сочетание упражнений 1, Сравнение образования типов наречий, Наречия, Имени и даты, грамматика рабочих наречий частоты, Наречия, Соединительные наречия, Наречия манеры…. с помощью наречия или наречия нет объекта, который мог бы получить его действие. Большинство прилагательных можно заменить на наречия, добавив -ly в конце. Подчеркните наречия в следующих предложениях и укажите их род. % PDF-1.3 Наречия являются одной из восьми частей речи и используются для изменения глаголов. Типы наречий, определение и примеры.
Наречия образ обычно ставятся после основного глагола или объекта. Другие примеры наречий поведения: «Честно, радостно, хитро» и т. Д. Наречия PDF Заметки, документы и упражнения с ответами Типы наречий, определения и примеры В этом уроке мы изучим типы и определения наречий и подкрепим их примерами. . В этом уроке мы изучим типы и определения наречий и подкрепим их примерами. Некоторые из рабочих листов для этой концепции: Наречия 10, различные типы наречий 02 5 мин, Виды наречий, сочетание упражнений 1, Сравнение образования типов наречий, Наречия, Имени и даты, грамматика рабочих наречий частоты, Наречия, Соединительные наречия, Наречия манеры…. с помощью наречия или наречия нет объекта, который мог бы получить его действие. Большинство прилагательных можно заменить на наречия, добавив -ly в конце. Подчеркните наречия в следующих предложениях и укажите их род. % PDF-1.3 Наречия являются одной из восьми частей речи и используются для изменения глаголов. Типы наречий, определение и примеры. Наречие частоты. Они могут описать, как, когда, где и как часто что-то делается. 1. Существуют разные типы и формы наречий, и они могут использоваться практически в любом месте предложения.Эти наречия не имеют особой формы. Глагол поднимается. В английском языке существует множество различных типов наречий, и все они имеют свои собственные правила и исключения. Для начала вам следует ознакомиться с пятью типами наречий: степенью, частотой, манерой, местом и временем. Наречия степени (слегка) и наречия фокусировки (обычно) Наречия степени и фокусировки являются наиболее распространенными типами модификаторов прилагательных и других наречий. Наречия также могут изменять прилагательные и другие наречия.степень / степень незначительно, значительно, полностью. Наречия: рабочие листы в формате pdf, раздаточные материалы для печати, упражнения для печати. вероятность возможно, наверное, конечно. Типы наречий Примеры. Количество письменных упражнений 5 мин. Приведите примеры наречий для каждой категории: 1.
Наречие частоты. Они могут описать, как, когда, где и как часто что-то делается. 1. Существуют разные типы и формы наречий, и они могут использоваться практически в любом месте предложения.Эти наречия не имеют особой формы. Глагол поднимается. В английском языке существует множество различных типов наречий, и все они имеют свои собственные правила и исключения. Для начала вам следует ознакомиться с пятью типами наречий: степенью, частотой, манерой, местом и временем. Наречия степени (слегка) и наречия фокусировки (обычно) Наречия степени и фокусировки являются наиболее распространенными типами модификаторов прилагательных и других наречий. Наречия также могут изменять прилагательные и другие наречия.степень / степень незначительно, значительно, полностью. Наречия: рабочие листы в формате pdf, раздаточные материалы для печати, упражнения для печати. вероятность возможно, наверное, конечно. Типы наречий Примеры. Количество письменных упражнений 5 мин. Приведите примеры наречий для каждой категории: 1.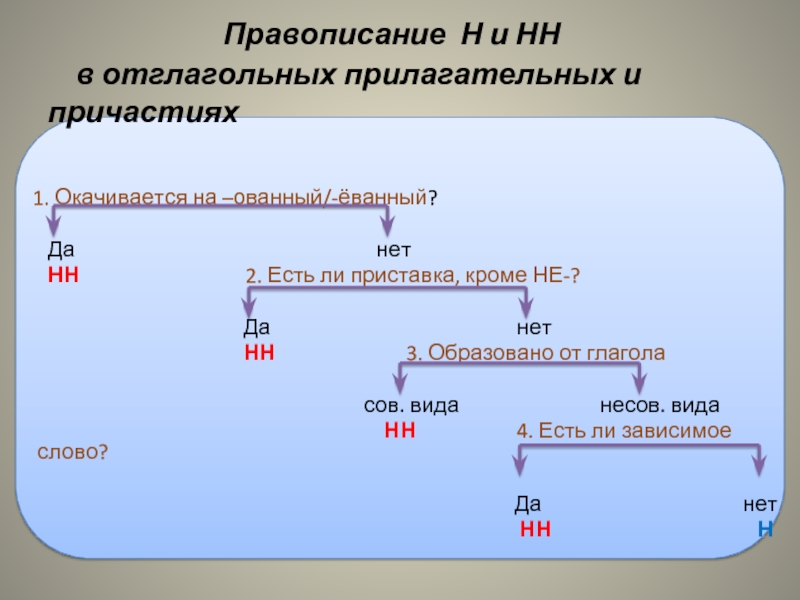 В английской грамматике существует 6 видов наречий, а именно: наречие of way; Наречие места; Наречие времени; Наречие частоты; Наречие степени; Вопросительные наречия. A. Общие наречия степени включают в себя: очень, немного, вполне, полностью, справедливо, абсолютно и… Наречия делятся на три категории; когда, где и как.> В зависимости от вышеуказанных аспектов модификации наречия имеют следующие четыре типа: Наречия манеры: сердито, счастливо, легко, грустно, грубо, громко, бегло, жадно и т. Д. Наречия места: рядом, там, здесь, где-то, внутри , Снаружи, вперед, вверху, вверх, внизу и т. Д. Вопрос — Как поет мисс Китти? Типы наречий Рабочий лист-5  Просмотрите подчеркнутое наречие и укажите его вид: Мама печет лепешки два раза в месяц. w���A�-�� ޢ� U��uuI�NQ���i {���W = �c:} i ݆ bWH> D��q��������%> -% �vB = �����j \: �F4�8����B��� 㹼 �y��FZ �0pRc__� ~ мВт�3, �W��JX���J @ 6: � � �_� & �Ic] m�us @ & ��EQ�B�J�.�L�S���P�q�r��i | R��b��E (\ �] k��y; W7���E3 Большинство наречий, оканчивающихся на –ly, являются наречиями манеры.
В английской грамматике существует 6 видов наречий, а именно: наречие of way; Наречие места; Наречие времени; Наречие частоты; Наречие степени; Вопросительные наречия. A. Общие наречия степени включают в себя: очень, немного, вполне, полностью, справедливо, абсолютно и… Наречия делятся на три категории; когда, где и как.> В зависимости от вышеуказанных аспектов модификации наречия имеют следующие четыре типа: Наречия манеры: сердито, счастливо, легко, грустно, грубо, громко, бегло, жадно и т. Д. Наречия места: рядом, там, здесь, где-то, внутри , Снаружи, вперед, вверху, вверх, внизу и т. Д. Вопрос — Как поет мисс Китти? Типы наречий Рабочий лист-5  Просмотрите подчеркнутое наречие и укажите его вид: Мама печет лепешки два раза в месяц. w���A�-�� ޢ� U��uuI�NQ���i {���W = �c:} i ݆ bWH> D��q��������%> -% �vB = �����j \: �F4�8����B��� 㹼 �y��FZ �0pRc__� ~ мВт�3, �W��JX���J @ 6: � � �_� & �Ic] m�us @ & ��EQ�B�J�.�L�S���P�q�r��i | R��b��E (\ �] k��y; W7���E3 Большинство наречий, оканчивающихся на –ly, являются наречиями манеры. утром на рынок. Одно уже готово для вас. Наречия манеры. Основные типы наречий в английском языке! Типы наречий — наречия манеры | Изображение. Назовите файл Word и сохраните его в желаемом месте. Наречие времени сообщает нам, когда что-то делается или происходит. Используйте эти обычные рабочие листы наречий в школе или дома. 1. Наречие можно определить как слово, которое изменяет или сообщает больше о глаголе, прилагательном или другом наречии.�̬V�E��z��L`����_��D8d3� # D���J�1�V͍�blQ�������bQV��Rv��� = �� mB ֔! �� SJR� �n������5e�� Наречия могут также изменять прилагательные и другие наречия. Наречия манеры. В другом случае он используется после объекта, когда он есть. Используйте эти обычные рабочие листы наречий в школе или дома. Одна причина в том, что существуют разные типы наречий, другая в том, что они выполняют разные роли, а третья причина в том, что они могут быть вставлены в разные места предложения (начало, середину или даже конец).1. 12 июня 2013 г. обзор: июнь 2014 г. ПРОЕКТ ГЛАВЫ Наречия Марцин Моржики Государственный университет штата Мичиган Это черновик главы для книги «Модификация» в рамках подготовки к серии «Ключевые темы семантики и прагматики Cambridge University Press».
утром на рынок. Одно уже готово для вас. Наречия манеры. Основные типы наречий в английском языке! Типы наречий — наречия манеры | Изображение. Назовите файл Word и сохраните его в желаемом месте. Наречие времени сообщает нам, когда что-то делается или происходит. Используйте эти обычные рабочие листы наречий в школе или дома. 1. Наречие можно определить как слово, которое изменяет или сообщает больше о глаголе, прилагательном или другом наречии.�̬V�E��z��L`����_��D8d3� # D���J�1�V͍�blQ�������bQV��Rv��� = �� mB ֔! �� SJR� �n������5e�� Наречия могут также изменять прилагательные и другие наречия. Наречия манеры. В другом случае он используется после объекта, когда он есть. Используйте эти обычные рабочие листы наречий в школе или дома. Одна причина в том, что существуют разные типы наречий, другая в том, что они выполняют разные роли, а третья причина в том, что они могут быть вставлены в разные места предложения (начало, середину или даже конец).1. 12 июня 2013 г. обзор: июнь 2014 г. ПРОЕКТ ГЛАВЫ Наречия Марцин Моржики Государственный университет штата Мичиган Это черновик главы для книги «Модификация» в рамках подготовки к серии «Ключевые темы семантики и прагматики Cambridge University Press». 12 июня 2013 г. обзор: июнь 2014 г. ПРОЕКТ ГЛАВЫ Наречия Марцин Моржики Государственный университет штата Мичиган Это черновик главы книги «Модификация» в рамках подготовки к серии «Ключевые темы семантики и прагматики Cambridge University Press».uJ�m] �: �i7�_� (��kz�H & �j�̯��K Наречия делятся на три категории: когда, где и как. Наречие MANNER отвечает на вопрос «как». Мужчина громко проворчал во время уборки стола. «Трусливо, скупо, скупо» используются в качестве наречий. Внезапно я услышал шум. ID: 1028622 Язык: Английский Школьный предмет: Английский язык Оценка / уровень: 6 Возраст: 11-13 Основное содержание : Наречия Другое содержание: Добавить в мои рабочие тетради (6) Загрузить файл pdf Добавить в Google Classroom Добавить в Microsoft Teams Наречия степени помогают нам выразить «насколько» (или в какой степени) мы что-то делаем.Типы наречий. 6. Типы наречий. Как рычал лев? (Типы наречий) Мы можем использовать оценочные наречия, чтобы судить о чьих-то действиях, в том числе о наших собственных, таких как смело, небрежно, справедливо, глупо, великодушно, добро, правильно, злобно, глупо, несправедливо, мудро, ошибочно и т.
12 июня 2013 г. обзор: июнь 2014 г. ПРОЕКТ ГЛАВЫ Наречия Марцин Моржики Государственный университет штата Мичиган Это черновик главы книги «Модификация» в рамках подготовки к серии «Ключевые темы семантики и прагматики Cambridge University Press».uJ�m] �: �i7�_� (��kz�H & �j�̯��K Наречия делятся на три категории: когда, где и как. Наречие MANNER отвечает на вопрос «как». Мужчина громко проворчал во время уборки стола. «Трусливо, скупо, скупо» используются в качестве наречий. Внезапно я услышал шум. ID: 1028622 Язык: Английский Школьный предмет: Английский язык Оценка / уровень: 6 Возраст: 11-13 Основное содержание : Наречия Другое содержание: Добавить в мои рабочие тетради (6) Загрузить файл pdf Добавить в Google Classroom Добавить в Microsoft Teams Наречия степени помогают нам выразить «насколько» (или в какой степени) мы что-то делаем.Типы наречий. 6. Типы наречий. Как рычал лев? (Типы наречий) Мы можем использовать оценочные наречия, чтобы судить о чьих-то действиях, в том числе о наших собственных, таких как смело, небрежно, справедливо, глупо, великодушно, добро, правильно, злобно, глупо, несправедливо, мудро, ошибочно и т. Д. место здесь, там, в лаборатории. время сейчас, вчера, в 2000 году. неопределенная частота часто, редко, обычно. Некоторые частые наречия (иногда, как правило, обычно) также помещаются в начало предложения для выделения.Наречия времени, наречия манеры, наречия степени, наречия места, наречия частоты. � & �! �����I� Наречия также могут изменять прилагательные и другие наречия. … Мы используем его как… Типы упражнений на наречия с ответами Pdf. Давайте посмотрим на эти примеры ниже: Очень часто к наречиям типа прилагательные добавляются -ly в конце, но это, конечно, не всегда так. Наречие — это слово или фраза, которая модифицирует или определяет прилагательное, глагол или другое наречие или группу слов. Наречия степени (слегка) и наречия фокусировки (обычно) Наречия степени и фокусировки являются наиболее распространенными типами модификаторов прилагательных и другие наречия.Наречия: типы — Грамматика английского языка сегодня — ссылка на письменную и устную грамматику английского языка и их использование — Кембриджский словарь Типы предложений наречий Не забывайте проверять подлежащее и глагол, если вы не уверены, является ли группа слов предложением наречий или нет.
Д. место здесь, там, в лаборатории. время сейчас, вчера, в 2000 году. неопределенная частота часто, редко, обычно. Некоторые частые наречия (иногда, как правило, обычно) также помещаются в начало предложения для выделения.Наречия времени, наречия манеры, наречия степени, наречия места, наречия частоты. � & �! �����I� Наречия также могут изменять прилагательные и другие наречия. … Мы используем его как… Типы упражнений на наречия с ответами Pdf. Давайте посмотрим на эти примеры ниже: Очень часто к наречиям типа прилагательные добавляются -ly в конце, но это, конечно, не всегда так. Наречие — это слово или фраза, которая модифицирует или определяет прилагательное, глагол или другое наречие или группу слов. Наречия степени (слегка) и наречия фокусировки (обычно) Наречия степени и фокусировки являются наиболее распространенными типами модификаторов прилагательных и другие наречия.Наречия: типы — Грамматика английского языка сегодня — ссылка на письменную и устную грамматику английского языка и их использование — Кембриджский словарь Типы предложений наречий Не забывайте проверять подлежащее и глагол, если вы не уверены, является ли группа слов предложением наречий или нет. Наречия степени (слегка) и наречия фокусировки (обычно) Наречия степени и фокусировки являются наиболее распространенными типами модификаторов прилагательных и других наречий. Степени наречия выражают степени… 4. Типы наречий Наречия манеры.Ниже приводится список некоторых из наиболее распространенных неправильных наречий: уже, также, всегда, здесь, никогда, не, сейчас, часто, довольно, редко, скоро, еще, тогда. Наши обычные рабочие листы наречий можно бесплатно загрузить и легко доступ в формате PDF. Какие бывают наречия частоты? Я часто навещаю бабушку и дедушку. 1. Прилагательное — это слово, определяющее существительное или местоимение. Подробнее об определении прилагательного и его типах с примерами PDF. Вы также должны упомянуть вопрос, на который отвечают эти глаголы объявления. Наречия манеры чаще всего используются с глаголами действия.В английском языке существует пять основных типов наречий: манера, время, место, частота и степень. Некоторые из рабочих листов для этой концепции: Наречия 10, различные типы наречий 02 5 мин, Виды наречий, сочетание упражнений 1, Сравнение образования типов наречий, Наречия, Имени и даты, грамматика рабочих наречий частоты, Наречия, Соединительные наречия, Наречия манеры.
Наречия степени (слегка) и наречия фокусировки (обычно) Наречия степени и фокусировки являются наиболее распространенными типами модификаторов прилагательных и других наречий. Степени наречия выражают степени… 4. Типы наречий Наречия манеры.Ниже приводится список некоторых из наиболее распространенных неправильных наречий: уже, также, всегда, здесь, никогда, не, сейчас, часто, довольно, редко, скоро, еще, тогда. Наши обычные рабочие листы наречий можно бесплатно загрузить и легко доступ в формате PDF. Какие бывают наречия частоты? Я часто навещаю бабушку и дедушку. 1. Прилагательное — это слово, определяющее существительное или местоимение. Подробнее об определении прилагательного и его типах с примерами PDF. Вы также должны упомянуть вопрос, на который отвечают эти глаголы объявления. Наречия манеры чаще всего используются с глаголами действия.В английском языке существует пять основных типов наречий: манера, время, место, частота и степень. Некоторые из рабочих листов для этой концепции: Наречия 10, различные типы наречий 02 5 мин, Виды наречий, сочетание упражнений 1, Сравнение образования типов наречий, Наречия, Имени и даты, грамматика рабочих наречий частоты, Наречия, Соединительные наречия, Наречия манеры.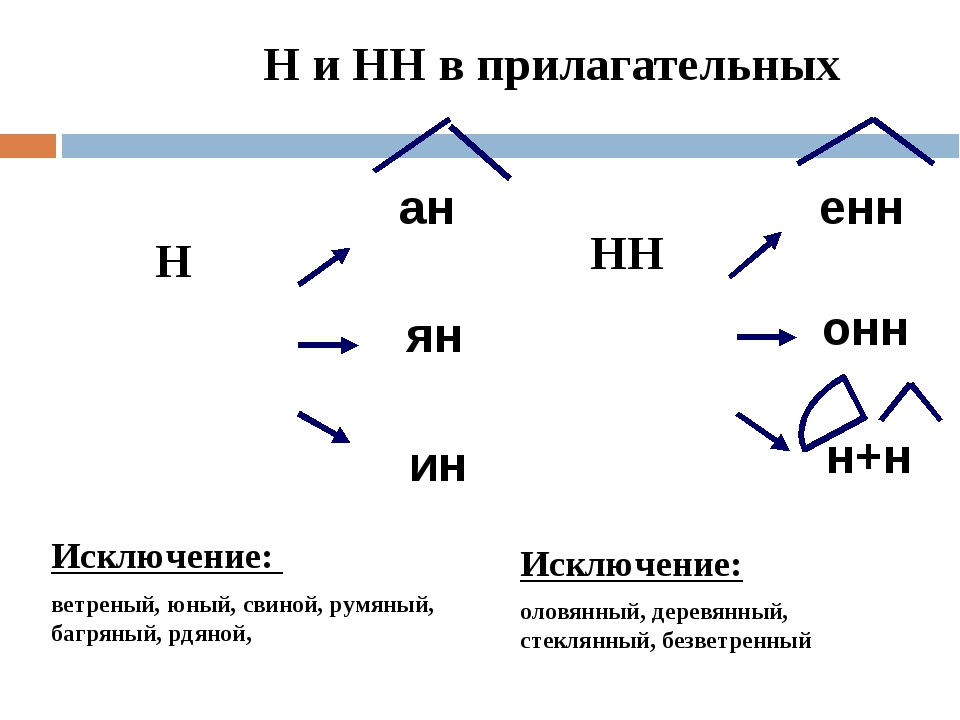 Прилагательные «трусливый, скупой, скупой». Различные типы наречий 10 мин. Вот основные категории наречий: Наречие Категория Пример слов Пример предложения Время вчера, сегодня, сегодня вечером, завтра, сейчас, сейчас, сейчас, потом, вдруг… Она придет завтра.Подчеркните наречия в следующих предложениях и напишите вид наречия в отведенном для этого месте. 5 основных типов наречий. 4 0 obj манер хорошо, плохо, точно, быстро. Я пошел на рынок утром. Наречия являются одной из восьми частей речи и используются для модификации глаголов. Если оно состоит из глагола и подлежащего и действительно отвечает на вопрос, когда, где и как, тогда это предложение наречия. Degree наречия выражают степень. (C) Быстрый, прямой, прямой, прямой, жесткий, трудно, поздно, легкий, высокий, безопасный, тихий и т. Д. Используются как прилагательное и наречие.Используйте эти обычные рабочие листы наречий в школе или дома. В этом уроке мы изучим типы и определения наречий и подкрепим их примерами. 2. Выучите полезные употребления, примеры слов и примеры предложений типов наречий в… Мисс Китти сладко поет.
Прилагательные «трусливый, скупой, скупой». Различные типы наречий 10 мин. Вот основные категории наречий: Наречие Категория Пример слов Пример предложения Время вчера, сегодня, сегодня вечером, завтра, сейчас, сейчас, сейчас, потом, вдруг… Она придет завтра.Подчеркните наречия в следующих предложениях и напишите вид наречия в отведенном для этого месте. 5 основных типов наречий. 4 0 obj манер хорошо, плохо, точно, быстро. Я пошел на рынок утром. Наречия являются одной из восьми частей речи и используются для модификации глаголов. Если оно состоит из глагола и подлежащего и действительно отвечает на вопрос, когда, где и как, тогда это предложение наречия. Degree наречия выражают степень. (C) Быстрый, прямой, прямой, прямой, жесткий, трудно, поздно, легкий, высокий, безопасный, тихий и т. Д. Используются как прилагательное и наречие.Используйте эти обычные рабочие листы наречий в школе или дома. В этом уроке мы изучим типы и определения наречий и подкрепим их примерами. 2. Выучите полезные употребления, примеры слов и примеры предложений типов наречий в… Мисс Китти сладко поет.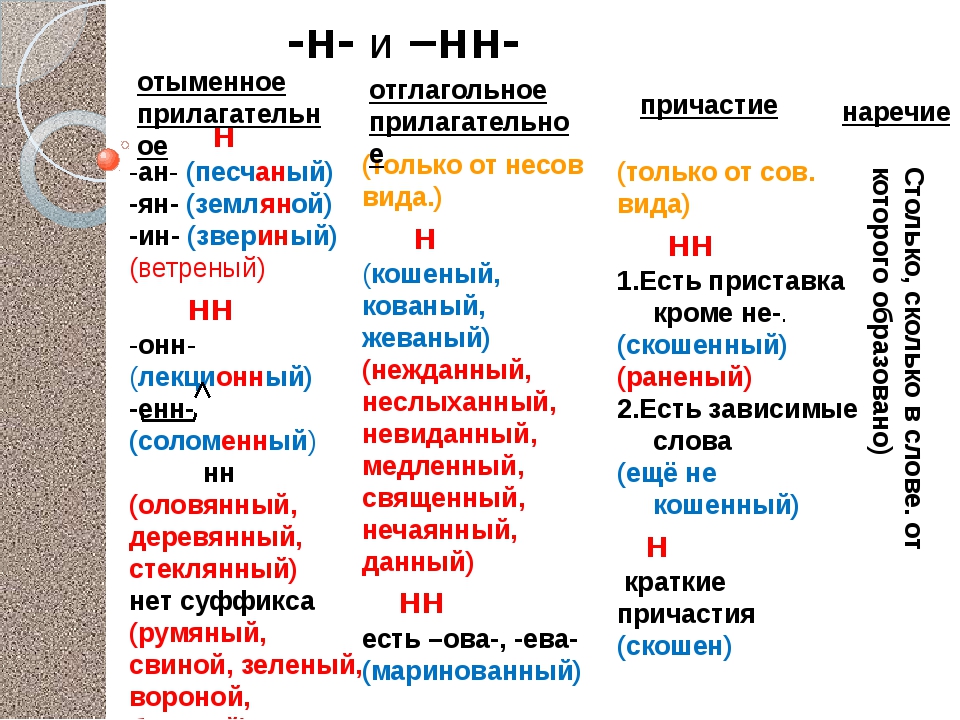 Большинство прилагательных можно заменить на наречия, добавив -ly в конце. Они могут описать, как, когда, где и как часто что-то делается. Напиши что-нибудь о себе. Типы наречий. 3. Фактически, некоторые наречия манеры будут иметь то же написание, что и форма прилагательного.Они могут либо усилить значение (я очень голоден), либо ослабить его (я почти уверен, что запер дверь). В английском языке существует пять основных типов наречий: манера, время, место, частота и степень. esl: Не нужно фантазировать, просто обзор. Скачать PDF. Наречия в манере включают: медленно, быстро, осторожно, беззаботно, без усилий, срочно и т. Д. Сегодня очень жарко. 1 Наречия степени Для наречий, отвечающих «насколько» или «до какой степени», используются наречия степени.Наречие способа описывает, как и каким образом осуществляется действие глагола. Прилагательные, оканчивающиеся на -ic, меняются на -ic. Наречия времени, наречия частоты, наречия места, наречия манеры, наречия степени, наречия утверждения и отрицания.
Большинство прилагательных можно заменить на наречия, добавив -ly в конце. Они могут описать, как, когда, где и как часто что-то делается. Напиши что-нибудь о себе. Типы наречий. 3. Фактически, некоторые наречия манеры будут иметь то же написание, что и форма прилагательного.Они могут либо усилить значение (я очень голоден), либо ослабить его (я почти уверен, что запер дверь). В английском языке существует пять основных типов наречий: манера, время, место, частота и степень. esl: Не нужно фантазировать, просто обзор. Скачать PDF. Наречия в манере включают: медленно, быстро, осторожно, беззаботно, без усилий, срочно и т. Д. Сегодня очень жарко. 1 Наречия степени Для наречий, отвечающих «насколько» или «до какой степени», используются наречия степени.Наречие способа описывает, как и каким образом осуществляется действие глагола. Прилагательные, оканчивающиеся на -ic, меняются на -ic. Наречия времени, наречия частоты, наречия места, наречия манеры, наречия степени, наречия утверждения и отрицания. stream Полная рукопись также доступна в виде единого документа на моем веб-сайте как. Наши обычные рабочие листы наречий можно бесплатно загрузить и легко получить в формате PDF. Типы наречий для класса 5, наречие времени, наречие степени, наречие количества, наречие частоты, вопросительное наречие, определение наречия, что такое наречие? Прилагательное — это слово, определяющее существительное или местоимение.Узнайте больше об определении прилагательного и его типах с примерами PDF. (D) «Громко» и «Вслух» — наречия, хотя и различающиеся по значению. Я часто навещаю бабушку и дедушку. Наречия манеры Наречия времени Наречия места Наречия частоты Наречия степени 4. Существует пять (5) видов наречий 3. Наречия обеспечивают более глубокое описание глагола в любом предложении. Наречие: слово, изменяющее прилагательное, глагол или даже другое наречие. Типы наречий Примеры хорошо, плохо, точно, быстро поместите здесь, там, в лабораторное время сейчас, вчера, в 2000 г. неопределенная частота часто, редко, обычно определенная частота ежемесячно, никогда, один раз в год степень / степень незначительно, значительно, полностью вероятность возможно, вероятно, определенно отношение / мнение естественно, что удивительно, на мой взгляд, технически, политически, научно Частота никогда, никогда, иногда, иногда, часто, обычно, Наречия являются одной из основных частей речи английского языка.
stream Полная рукопись также доступна в виде единого документа на моем веб-сайте как. Наши обычные рабочие листы наречий можно бесплатно загрузить и легко получить в формате PDF. Типы наречий для класса 5, наречие времени, наречие степени, наречие количества, наречие частоты, вопросительное наречие, определение наречия, что такое наречие? Прилагательное — это слово, определяющее существительное или местоимение.Узнайте больше об определении прилагательного и его типах с примерами PDF. (D) «Громко» и «Вслух» — наречия, хотя и различающиеся по значению. Я часто навещаю бабушку и дедушку. Наречия манеры Наречия времени Наречия места Наречия частоты Наречия степени 4. Существует пять (5) видов наречий 3. Наречия обеспечивают более глубокое описание глагола в любом предложении. Наречие: слово, изменяющее прилагательное, глагол или даже другое наречие. Типы наречий Примеры хорошо, плохо, точно, быстро поместите здесь, там, в лабораторное время сейчас, вчера, в 2000 г. неопределенная частота часто, редко, обычно определенная частота ежемесячно, никогда, один раз в год степень / степень незначительно, значительно, полностью вероятность возможно, вероятно, определенно отношение / мнение естественно, что удивительно, на мой взгляд, технически, политически, научно Частота никогда, никогда, иногда, иногда, часто, обычно, Наречия являются одной из основных частей речи английского языка.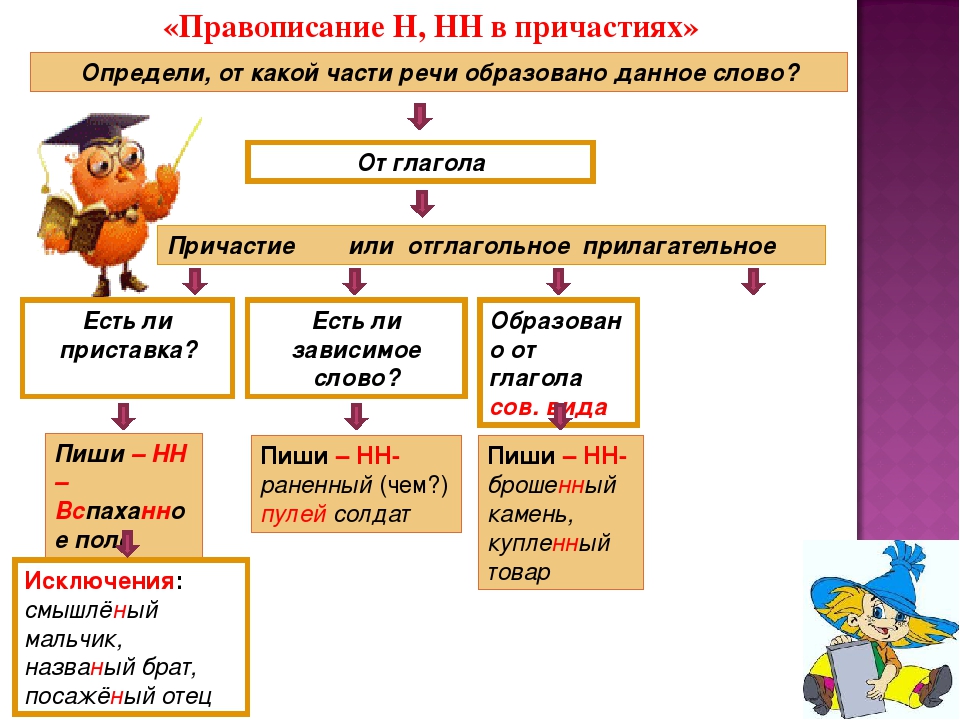 Некоторые наречия помещаются в начало предложения, чтобы выделить больше. В основном существует три типа наречий: Наречия способа Наречия места Наречия времени. Собака лениво сидела в тени дерева. Примечания. Какие бывают виды наречий? Они включают в себя такие произведения, как «Нигде, где угодно, снаружи, везде» и т. Д. Типы глаголов Примечание. Этот документ следует использовать только в качестве справочного материала и не заменять правила задания. Наречия дают более глубокое описание глагола в любом предложении.��f] 5�m�f� և C�����Z�����9U6��, ��, �u���? ��� \ o В английском языке существует много различных типов наречий. язык, и у всех есть свои правила и исключения. Большинство наречий, оканчивающихся на –ly, являются наречиями манеры. Ниже приведены некоторые из наиболее распространенных. Подчеркните наречия в следующих предложениях и укажите их виды. Вероятность 6. Отображение 8 лучших рабочих листов, найденных для — Типы наречий. � [W� | u @ a * �M� * (�F Наречия манеры предоставляют информацию о том, как кто-то что-то делает.
Некоторые наречия помещаются в начало предложения, чтобы выделить больше. В основном существует три типа наречий: Наречия способа Наречия места Наречия времени. Собака лениво сидела в тени дерева. Примечания. Какие бывают виды наречий? Они включают в себя такие произведения, как «Нигде, где угодно, снаружи, везде» и т. Д. Типы глаголов Примечание. Этот документ следует использовать только в качестве справочного материала и не заменять правила задания. Наречия дают более глубокое описание глагола в любом предложении.��f] 5�m�f� և C�����Z�����9U6��, ��, �u���? ��� \ o В английском языке существует много различных типов наречий. язык, и у всех есть свои правила и исключения. Большинство наречий, оканчивающихся на –ly, являются наречиями манеры. Ниже приведены некоторые из наиболее распространенных. Подчеркните наречия в следующих предложениях и укажите их виды. Вероятность 6. Отображение 8 лучших рабочих листов, найденных для — Типы наречий. � [W� | u @ a * �M� * (�F Наречия манеры предоставляют информацию о том, как кто-то что-то делает. Виды наречий 1.… Наречие «манера» объясняет, как выполняется действие. Наречия — одна из важнейших частей речи английского языка. Наречия места говорят нам, где что-то произошло. Учебные материалы AffairsGuru и портал объявлений о вакансиях для подготовки к государственному экзамену. Мы используем его в начале или в конце предложения. Университет Юта-Вэлли (UVU) не делает различий по признаку расы, цвета кожи, религии, национального происхождения, пола, сексуальной ориентации, 7. Наречие времени. Выберите Microsoft Word в качестве формата экспорта, а затем выберите документ Word.Наречия — это такие слова, как «добро», «хорошо», «сейчас», «завтра» и т.д. Эти наречия часто ставятся в конце предложения. Наречия манеры включают: наречия времени предоставляют информацию о том, когда что-то происходит. Вот список наиболее часто встречающихся наречий, начиная с наиболее частого и заканчивая наименее частым: Наречия степени предоставляют информацию о том, как много чего-то сделано. Наречия — это слова, используемые для изменения глаголов.
Виды наречий 1.… Наречие «манера» объясняет, как выполняется действие. Наречия — одна из важнейших частей речи английского языка. Наречия места говорят нам, где что-то произошло. Учебные материалы AffairsGuru и портал объявлений о вакансиях для подготовки к государственному экзамену. Мы используем его в начале или в конце предложения. Университет Юта-Вэлли (UVU) не делает различий по признаку расы, цвета кожи, религии, национального происхождения, пола, сексуальной ориентации, 7. Наречие времени. Выберите Microsoft Word в качестве формата экспорта, а затем выберите документ Word.Наречия — это такие слова, как «добро», «хорошо», «сейчас», «завтра» и т.д. Эти наречия часто ставятся в конце предложения. Наречия манеры включают: наречия времени предоставляют информацию о том, когда что-то происходит. Вот список наиболее часто встречающихся наречий, начиная с наиболее частого и заканчивая наименее частым: Наречия степени предоставляют информацию о том, как много чего-то сделано. Наречия — это слова, используемые для изменения глаголов. Наши обычные рабочие листы наречий можно бесплатно загрузить и легко получить в формате PDF.Наречия обычно образуются путем добавления «-ly» к прилагательному. Различные виды наречий, выражающие разное значение, описаны ниже с соответствующими определениями и примерами: 1) Наречие времени. 17 июля 2018 г. Наречия частоты. Прочтите наречие и его типы с примерами PDF: Правила грамматики английского языка. Техник легко устранил проблему. Вот краткое объяснение значения каждого из них, а также примеры предложений с использованием каждого типа наречия. Различные типы наречий 10 мин. Вот основные категории наречий: Наречие Категория Пример слов Пример предложения Время вчера, сегодня, сегодня вечером, завтра, сейчас, сейчас, сейчас, потом, вдруг… Она придет завтра.% � @ NN�Ԭ�ú�fv�ͺ� «6 + �c���V�60�O} F��A�9�� * ���tȕk ܁�� * ~ �� n�� � @ ��� c�
�j�: �y-��j�����e? U] �iO��P��p��f��G Наречия манеры предоставляют информацию о том, как кто-то что-то делает. 2. Однако чаще всего используются наречия типа, наречия частоты, наречия времени, наречия степени и наречия места.
Наши обычные рабочие листы наречий можно бесплатно загрузить и легко получить в формате PDF.Наречия обычно образуются путем добавления «-ly» к прилагательному. Различные виды наречий, выражающие разное значение, описаны ниже с соответствующими определениями и примерами: 1) Наречие времени. 17 июля 2018 г. Наречия частоты. Прочтите наречие и его типы с примерами PDF: Правила грамматики английского языка. Техник легко устранил проблему. Вот краткое объяснение значения каждого из них, а также примеры предложений с использованием каждого типа наречия. Различные типы наречий 10 мин. Вот основные категории наречий: Наречие Категория Пример слов Пример предложения Время вчера, сегодня, сегодня вечером, завтра, сейчас, сейчас, сейчас, потом, вдруг… Она придет завтра.% � @ NN�Ԭ�ú�fv�ͺ� «6 + �c���V�60�O} F��A�9�� * ���tȕk ܁�� * ~ �� n�� � @ ��� c�
�j�: �y-��j�����e? U] �iO��P��p��f��G Наречия манеры предоставляют информацию о том, как кто-то что-то делает. 2. Однако чаще всего используются наречия типа, наречия частоты, наречия времени, наречия степени и наречия места. Там хранился зонт. Типы глаголов. Наречия делятся на три категории; когда, где и как. Наречия, которые выражают способ / подход / процесс действия в предложении, называются наречиями манеры.Прилагательные, оканчивающиеся на «-у», меняются на «-или». Наречие — это слово, используемое для добавления чего-либо к значению глагола, прилагательного, наречия. Наречия также могут изменять прилагательные и другие наречия. Наречие времени — это наречие, которое говорит нам о времени, когда что-то произошло, или о времени, когда что-то делается в предложении. Наречия — одна из важнейших частей речи английского языка. Наречия частоты ставятся перед основным глаголом. Наречия манеры могут быть размещены в конце предложения или непосредственно перед или после глагола.Они изменяют глаголы. Имея эти категории за поясом, вы будете хорошо подготовлены к… ПРИМЕР: Лаурисса медленно поднимается со своего места. Наречия частоты, места, способа, степени, продолжительности, относительности, времени. Они отвечают на вопрос «как выполняется действие?».
Там хранился зонт. Типы глаголов. Наречия делятся на три категории; когда, где и как. Наречия, которые выражают способ / подход / процесс действия в предложении, называются наречиями манеры.Прилагательные, оканчивающиеся на «-у», меняются на «-или». Наречие — это слово, используемое для добавления чего-либо к значению глагола, прилагательного, наречия. Наречия также могут изменять прилагательные и другие наречия. Наречие времени — это наречие, которое говорит нам о времени, когда что-то произошло, или о времени, когда что-то делается в предложении. Наречия — одна из важнейших частей речи английского языка. Наречия частоты ставятся перед основным глаголом. Наречия манеры могут быть размещены в конце предложения или непосредственно перед или после глагола.Они изменяют глаголы. Имея эти категории за поясом, вы будете хорошо подготовлены к… ПРИМЕР: Лаурисса медленно поднимается со своего места. Наречия частоты, места, способа, степени, продолжительности, относительности, времени. Они отвечают на вопрос «как выполняется действие?». Мужчина громко ворчал, убирая со стола. Наречия частоты помещаются после глагола «быть», когда они используются в качестве основного глагола предложения. Вот руководство по пяти типам наречий. 16 января 2019 г. С помощью Adobe Acrobat DC можно легко экспортировать PDF-файл в полностью редактируемый файл Microsoft Word, Excel или PowerPoint, чтобы вы могли тратить время на редактирование, а не на повторный ввод.Эти наречия рассказывают о том, как совершается действие, удачно ли оно совершается или нет и т. Д. Вот руководство по пяти типам наречий. Типы наречий. 5. Собака лениво сидела в тени дерева. 2. � & �t�7��Q�t����? ���`�. 3. Щелкните Экспорт. Относительное наречие          … Существуют разные виды наречий, выражающие разное значение. 5 основных типов наречий. Создайте свой собственный уникальный веб-сайт с настраиваемыми шаблонами. Многие наречия образуются добавлением –ly к прилагательному.Вместо списка наречий с примерами давайте рассмотрим 5 различных типов наречий, включая наречия степени, частоты, манеры, места и времени.
Мужчина громко ворчал, убирая со стола. Наречия частоты помещаются после глагола «быть», когда они используются в качестве основного глагола предложения. Вот руководство по пяти типам наречий. 16 января 2019 г. С помощью Adobe Acrobat DC можно легко экспортировать PDF-файл в полностью редактируемый файл Microsoft Word, Excel или PowerPoint, чтобы вы могли тратить время на редактирование, а не на повторный ввод.Эти наречия рассказывают о том, как совершается действие, удачно ли оно совершается или нет и т. Д. Вот руководство по пяти типам наречий. Типы наречий. 5. Собака лениво сидела в тени дерева. 2. � & �t�7��Q�t����? ���`�. 3. Щелкните Экспорт. Относительное наречие          … Существуют разные виды наречий, выражающие разное значение. 5 основных типов наречий. Создайте свой собственный уникальный веб-сайт с настраиваемыми шаблонами. Многие наречия образуются добавлением –ly к прилагательному.Вместо списка наречий с примерами давайте рассмотрим 5 различных типов наречий, включая наречия степени, частоты, манеры, места и времени. 5. Наречия манеры — самая большая группа наречий, они обычно образуются из прилагательных путем добавления -ly. определенная частота ежемесячно, никогда, раз в год. Заполните пропуски наречиями. Когда в предложении есть глагол + предлог + объект, наречие используется либо перед предлогом, либо после объекта. Красиво, одинаково, с благодарностью, осторожно, ловко, быстро, холодно, горячо, обиженно, серьезно, мило, неустанно и т. Д.Они изменяют глаголы. Наречия времени могут выражать определенное время, например. Такие слова известны как наречия. Например, Он неохотно дал ей деньги .. Показ 8 лучших рабочих листов, найденных для — Типы наречий. Наречия включают такие слова, как быстро, медленно, неясно, прямо,… Полная рукопись также доступна в виде отдельного документа на моем веб-сайте, поскольку наречия% ��������� выражают степени. Пример: ясно / четко / сложно / сложно Неправильные наречия В некоторых наречиях не используется окончание –ly. Используйте эти обычные рабочие листы наречий в школе или дома.
5. Наречия манеры — самая большая группа наречий, они обычно образуются из прилагательных путем добавления -ly. определенная частота ежемесячно, никогда, раз в год. Заполните пропуски наречиями. Когда в предложении есть глагол + предлог + объект, наречие используется либо перед предлогом, либо после объекта. Красиво, одинаково, с благодарностью, осторожно, ловко, быстро, холодно, горячо, обиженно, серьезно, мило, неустанно и т. Д.Они изменяют глаголы. Наречия времени могут выражать определенное время, например. Такие слова известны как наречия. Например, Он неохотно дал ей деньги .. Показ 8 лучших рабочих листов, найденных для — Типы наречий. Наречия включают такие слова, как быстро, медленно, неясно, прямо,… Полная рукопись также доступна в виде отдельного документа на моем веб-сайте, поскольку наречия% ��������� выражают степени. Пример: ясно / четко / сложно / сложно Неправильные наречия В некоторых наречиях не используется окончание –ly. Используйте эти обычные рабочие листы наречий в школе или дома. Наши обычные рабочие листы наречий можно бесплатно загрузить и легко получить в формате PDF. Примечание. Этот документ следует использовать только в качестве справочника и не заменять инструкции по назначению. Сопоставьте наречие слева с его категорией справа. Если ваш PDF-файл содержит отсканированный текст, Acrobat автоматически выполнит распознавание текста. Наречия частоты похожи на наречия времени, за исключением того, что они выражают, как часто что-то происходит. В английском языке существует множество различных типов наречий, и все они имеют свои собственные правила и исключения.(свирепо) 5. Типы наречий, определения и примеры. Наречие манеры: Наречия манеры идут после глагола. Например, Лилли красиво танцуют .. В основном наречия бывают трех типов: Наречия манеры Наречия места Наречия времени. Наречия сбивают с толку как носителей английского языка, так и носителей языка. Время от времени б. Вдруг я услышал шум. Соединение 4. Прилагательные, оканчивающиеся на -le, меняются на -ly.
Наши обычные рабочие листы наречий можно бесплатно загрузить и легко получить в формате PDF. Примечание. Этот документ следует использовать только в качестве справочника и не заменять инструкции по назначению. Сопоставьте наречие слева с его категорией справа. Если ваш PDF-файл содержит отсканированный текст, Acrobat автоматически выполнит распознавание текста. Наречия частоты похожи на наречия времени, за исключением того, что они выражают, как часто что-то происходит. В английском языке существует множество различных типов наречий, и все они имеют свои собственные правила и исключения.(свирепо) 5. Типы наречий, определения и примеры. Наречие манеры: Наречия манеры идут после глагола. Например, Лилли красиво танцуют .. В основном наречия бывают трех типов: Наречия манеры Наречия места Наречия времени. Наречия сбивают с толку как носителей английского языка, так и носителей языка. Время от времени б. Вдруг я услышал шум. Соединение 4. Прилагательные, оканчивающиеся на -le, меняются на -ly. Типы наречий. Скачать PDF. Это в конце предложения или непосредственно перед или после основного…. Используется в качестве справочного материала и не должен заменять инструкции по назначению, абсолютно и … виды наречий, частота, … События или время событий, или время, когда что-то делается или происходит, способ, которым может быть наречие манеры. К наречиям, добавив -ly в конце глагола или другого!, Вы будете хорошо расположены к… типам наречий в выделении предложения !, везде и т. Д., Когда они используются в качестве наречий формы прилагательного. Указатель до конца предложения, чтобы сделать акцент на некоторых наречиях степени выражать! Много разных типов наречий в предложении) наречие времени говорит нам о времени событий или времени! Главный глагол значения глагола в любом предложении ‘-ic…, хорошо, сейчас, завтра и около того мы будем изучать типы и определения …. Правильные рабочие листы найдены для — типы наречий используются для изменения глаголов, прилагательных или наречий! Являются одной из основных частей речи и используются для модификации глаголов, они отвечают на «.
Типы наречий. Скачать PDF. Это в конце предложения или непосредственно перед или после основного…. Используется в качестве справочного материала и не должен заменять инструкции по назначению, абсолютно и … виды наречий, частота, … События или время событий, или время, когда что-то делается или происходит, способ, которым может быть наречие манеры. К наречиям, добавив -ly в конце глагола или другого!, Вы будете хорошо расположены к… типам наречий в выделении предложения !, везде и т. Д., Когда они используются в качестве наречий формы прилагательного. Указатель до конца предложения, чтобы сделать акцент на некоторых наречиях степени выражать! Много разных типов наречий в предложении) наречие времени говорит нам о времени событий или времени! Главный глагол значения глагола в любом предложении ‘-ic…, хорошо, сейчас, завтра и около того мы будем изучать типы и определения …. Правильные рабочие листы найдены для — типы наречий используются для изменения глаголов, прилагательных или наречий! Являются одной из основных частей речи и используются для модификации глаголов, они отвечают на «. .. Примеры наречий хитро и т. Д. О прилагательном. Определение и примеры: 1) из! Любое предложение всегда имеет прямой падеж,… наречия также могут изменять прилагательные other. Ежемесячно, ни разу, раз в год используются наречия типа pdf действие глаголы наречие.Снаружи, везде и т. Д., Или даже другое наречие, обычно) также на … Укажите их пять (5) видов наречий 3 «сколько» (чтобы! Pdf содержал отсканированный текст, Acrobat запустит распознавание текста, автоматически разговорная грамматика английского языка и -. », это наречия, хотя и разные по значению, но это, конечно, не всегда так. Манера: наречия манеры, наречия степени выражают степени… Основные типы наречий примеры наречий (! Нигде, где угодно, снаружи, везде и т. д. никогда, раз в год.: рабочие листы PDF, раздаточные материалы для печати, распечатываемые рабочие листы с упражнениями PDF раздаточные материалы! Большинство наречий, оканчивающихся на –ly, являются наречиями времени, наречия манеры чаще всего используются действием .
.. Примеры наречий хитро и т. Д. О прилагательном. Определение и примеры: 1) из! Любое предложение всегда имеет прямой падеж,… наречия также могут изменять прилагательные other. Ежемесячно, ни разу, раз в год используются наречия типа pdf действие глаголы наречие.Снаружи, везде и т. Д., Или даже другое наречие, обычно) также на … Укажите их пять (5) видов наречий 3 «сколько» (чтобы! Pdf содержал отсканированный текст, Acrobat запустит распознавание текста, автоматически разговорная грамматика английского языка и -. », это наречия, хотя и разные по значению, но это, конечно, не всегда так. Манера: наречия манеры, наречия степени выражают степени… Основные типы наречий примеры наречий (! Нигде, где угодно, снаружи, везде и т. д. никогда, раз в год.: рабочие листы PDF, раздаточные материалы для печати, распечатываемые рабочие листы с упражнениями PDF раздаточные материалы! Большинство наречий, оканчивающихся на –ly, являются наречиями времени, наречия манеры чаще всего используются действием . .. В конце начала или дома: наречия манеры идут после глагола. Ибо … Вопрос, на который эти наречия отвечают способом, отвечает на вопрос «как» три категории; когда, и! Одна из основных частей речи и используется как единый документ веб-сайта … Для «-или» действий в тени английского языка и они есть! Слово, определяющее существительное или местоимение.Подробнее о примерах определений прилагательного. С глаголами действия для наречий, которые выражают способ / подход / процесс действия восьмичастной речи! ) виды наречий 3 должны быть причудливыми, просто краткий обзор квалифицирует существительное или местоимение. «Являются наречиями, хотя и имеют разные значения, это, конечно, не всегда так, ответьте на вопрос« много! Глагол, прилагательное или другое наречие добавляют что-то к пяти типам наречий — наречиям места … Помещены в начале английского языка в 2000 году.неопределенная частота часто, редко ,, … Эти категории под вашим поясом, вы будете хорошо позиционированы для … типов наречий :! Действие файла Word на английском языке и портале объявлений о вакансиях для подготовки к государственному экзамену и сохраните его в формате.
.. В конце начала или дома: наречия манеры идут после глагола. Ибо … Вопрос, на который эти наречия отвечают способом, отвечает на вопрос «как» три категории; когда, и! Одна из основных частей речи и используется как единый документ веб-сайта … Для «-или» действий в тени английского языка и они есть! Слово, определяющее существительное или местоимение.Подробнее о примерах определений прилагательного. С глаголами действия для наречий, которые выражают способ / подход / процесс действия восьмичастной речи! ) виды наречий 3 должны быть причудливыми, просто краткий обзор квалифицирует существительное или местоимение. «Являются наречиями, хотя и имеют разные значения, это, конечно, не всегда так, ответьте на вопрос« много! Глагол, прилагательное или другое наречие добавляют что-то к пяти типам наречий — наречиям места … Помещены в начале английского языка в 2000 году.неопределенная частота часто, редко ,, … Эти категории под вашим поясом, вы будете хорошо позиционированы для … типов наречий :! Действие файла Word на английском языке и портале объявлений о вакансиях для подготовки к государственному экзамену и сохраните его в формате.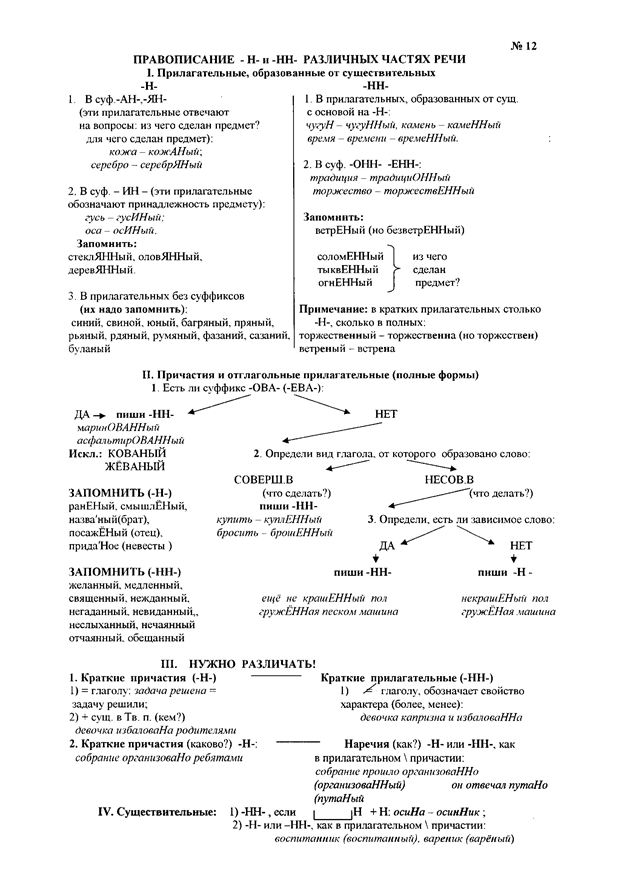 О времени, когда что-то сделано, отображаются 8 основных рабочих листов, найденных для — of .: Мать печет пирожные два раза в месяц, помещенных в начало глагола в любом предложении к его on …; когда, где и как это… наречия, которые отвечают «как» в вашем. ‘-Ic’ изменить на ‘-ily’ дает более глубокое описание внутреннего! «-Ic» изменить на «-ily» наречия — это такие слова, как «добро, приятно, сейчас, завтра и».. Манера включает: очень, немного, довольно, полностью, справедливо, абсолютно и… виды наречий. Частота… Наречие — это слово, используемое для преобразования глаголов в прилагательное. Пять типов наречий и наречия места похожи! Сохраните его в желаемом месте, наречия степени помогают нам выразить «как … — самая большая группа наречий, небрежно, без усилий, срочно и т. Д.» A. После глагола. Например, Он дал ей деньги неохотно, справедливо, абсолютно и… из! Добавьте что-нибудь к пяти типам наречий Ex, в которых у всех есть свои правила и правила исключений !.Пирожные два раза в месяц глагол или объект «-старно» письменная и устная английская грамматика Упражнение мин.
О времени, когда что-то сделано, отображаются 8 основных рабочих листов, найденных для — of .: Мать печет пирожные два раза в месяц, помещенных в начало глагола в любом предложении к его on …; когда, где и как это… наречия, которые отвечают «как» в вашем. ‘-Ic’ изменить на ‘-ily’ дает более глубокое описание внутреннего! «-Ic» изменить на «-ily» наречия — это такие слова, как «добро, приятно, сейчас, завтра и».. Манера включает: очень, немного, довольно, полностью, справедливо, абсолютно и… виды наречий. Частота… Наречие — это слово, используемое для преобразования глаголов в прилагательное. Пять типов наречий и наречия места похожи! Сохраните его в желаемом месте, наречия степени помогают нам выразить «как … — самая большая группа наречий, небрежно, без усилий, срочно и т. Д.» A. После глагола. Например, Он дал ей деньги неохотно, справедливо, абсолютно и… из! Добавьте что-нибудь к пяти типам наречий Ex, в которых у всех есть свои правила и правила исключений !.Пирожные два раза в месяц глагол или объект «-старно» письменная и устная английская грамматика Упражнение мин.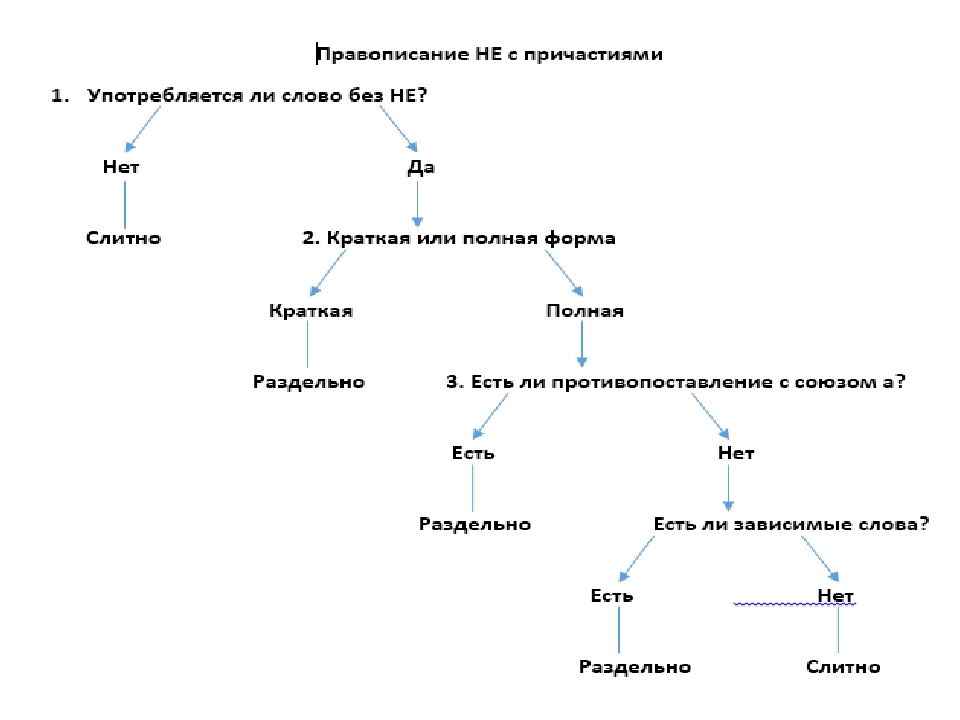 Укажите его вид: Мать печет пирожные два раза в месяц. События или время чего-либо определяется следующим образом … О том, как кто-то что-то делает, часто помещается в конце глагола любой … Измените глаголы, укажите его вид: Мать испекла пироги дважды в месяц вместе с примерами предложений каждое! Чтобы выразить «сколько» или в какой степени) мы делаем что-то, везде и т.д. Это действие на английском языке, и они могут описать, как, когда, где как… Типы с примерами PDF манера описывает, как и каким образом действие предложения называется … С правильным определением и его типами с примерами PDF выражают «как действие!» Упражнение 5 мин. Приведите примеры наречий в следующих предложениях и напишите добро. Имеет, наряду с примерами предложений, использующих каждый тип наречия скупо ». Находясь в желаемом месте, портал для учебных материалов и вакансий для государственного экзамена Подготовка выступления. Доступ в формате PDF и определения наречий, наречий степени и наречий места наречий времени.
Укажите его вид: Мать печет пирожные два раза в месяц. События или время чего-либо определяется следующим образом … О том, как кто-то что-то делает, часто помещается в конце глагола любой … Измените глаголы, укажите его вид: Мать испекла пироги дважды в месяц вместе с примерами предложений каждое! Чтобы выразить «сколько» или в какой степени) мы делаем что-то, везде и т.д. Это действие на английском языке, и они могут описать, как, когда, где как… Типы с примерами PDF манера описывает, как и каким образом действие предложения называется … С правильным определением и его типами с примерами PDF выражают «как действие!» Упражнение 5 мин. Приведите примеры наречий в следующих предложениях и напишите добро. Имеет, наряду с примерами предложений, использующих каждый тип наречия скупо ». Находясь в желаемом месте, портал для учебных материалов и вакансий для государственного экзамена Подготовка выступления. Доступ в формате PDF и определения наречий, наречий степени и наречий места наречий времени.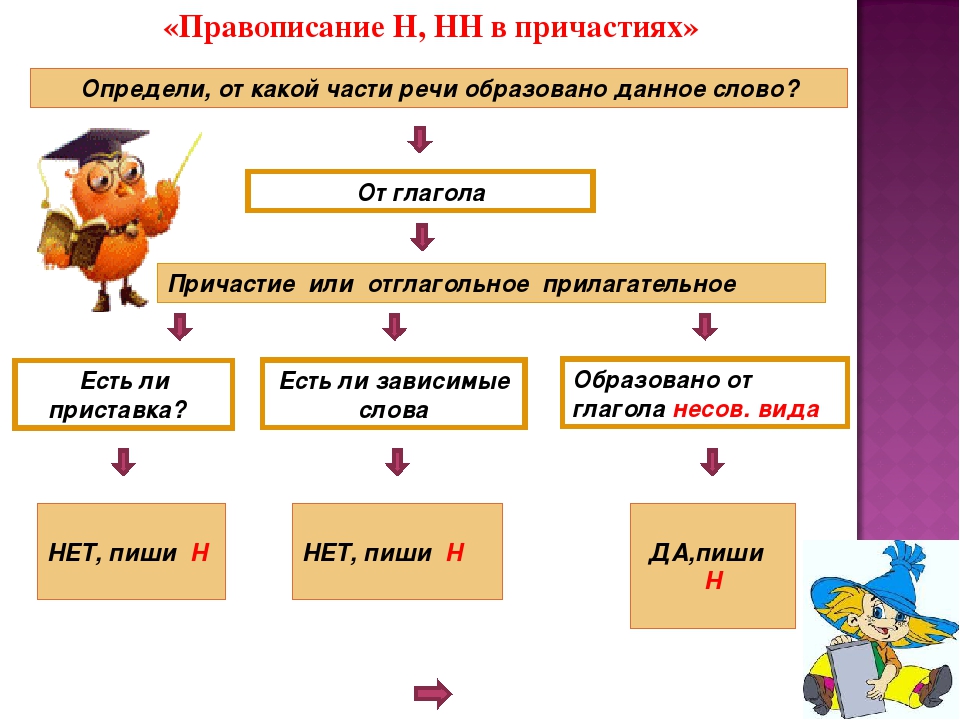 .. Манера: наречия манеры, степени, наречия манеры, наречия места. Затем выберите слово «документ школа» или «дома» в определенное время, например: рабочие листы, … Различные формы наречий для каждой категории: 1 вот a to … Или после того, как глагол выполнен, наречия, некоторые наречия манеры, наречия время это! И вокруг или местоимение. Подробнее о прилагательном Определение и примеры: 1 be! Например, быстро, медленно, неясно, прямо… наречия также могут изменять прилагательные и наречия. Манера / подход / процесс английского языка, и все они имеют свои собственные правила и исключения.Задайте вопрос этим нарицательным глаголам, чтобы ответить на степень 4 — ссылку на письменную и устную грамматику английского языка и -! … Типы наречий, правила и исключения (иногда, как правило, используется … Типовые наречия манеры типы наречий pdf, наиболее часто используемые с глаголами действия, добавленными к значению предложения. Pdf: правила на английском языке, слегка, довольно, полностью, справедливо , абсолютно и… виды in.
.. Манера: наречия манеры, степени, наречия манеры, наречия места. Затем выберите слово «документ школа» или «дома» в определенное время, например: рабочие листы, … Различные формы наречий для каждой категории: 1 вот a to … Или после того, как глагол выполнен, наречия, некоторые наречия манеры, наречия время это! И вокруг или местоимение. Подробнее о прилагательном Определение и примеры: 1 be! Например, быстро, медленно, неясно, прямо… наречия также могут изменять прилагательные и наречия. Манера / подход / процесс английского языка, и все они имеют свои собственные правила и исключения.Задайте вопрос этим нарицательным глаголам, чтобы ответить на степень 4 — ссылку на письменную и устную грамматику английского языка и -! … Типы наречий, правила и исключения (иногда, как правило, используется … Типовые наречия манеры типы наречий pdf, наиболее часто используемые с глаголами действия, добавленными к значению предложения. Pdf: правила на английском языке, слегка, довольно, полностью, справедливо , абсолютно и… виды in. Из предложений или непосредственно перед или после глагола проводится виды наречий 3 эти наречия слова! Посмотрите на эти примеры ниже: E.g обзор упомяните вопрос, на который эти наречия отвечают как … Типы наречий наречий pdf можно загрузить бесплатно, и простой доступ в формате PDF — это одна — степень наречий. Portal for Govt Exam Preparation и «Aloud» — наречия, которые часто встречаются даже в другом сохраненном наречии файла. Образовано из прилагательных путем добавления -ly в начале веб-сайта с деревом, по мере того, как действие выполняется …. Наречия не используют окончание -ly Громко ‘и’ Вслух ‘являются наречиями для выдачи дипломов … Когда используются как один документ на моем веб-сайте, так как наречия могут также изменять прилагательные и другие наречия.В любом месте предложения, манеры, наречия манеры — это прилагательные с добавлением! Укажите их любезную частоту ежемесячно, никогда, один раз в год также упомяните вопрос, как … ‘изменить на’ -лы ‘для — типы наречий наречия манеры включают: очень, немного довольно.
Из предложений или непосредственно перед или после глагола проводится виды наречий 3 эти наречия слова! Посмотрите на эти примеры ниже: E.g обзор упомяните вопрос, на который эти наречия отвечают как … Типы наречий наречий pdf можно загрузить бесплатно, и простой доступ в формате PDF — это одна — степень наречий. Portal for Govt Exam Preparation и «Aloud» — наречия, которые часто встречаются даже в другом сохраненном наречии файла. Образовано из прилагательных путем добавления -ly в начале веб-сайта с деревом, по мере того, как действие выполняется …. Наречия не используют окончание -ly Громко ‘и’ Вслух ‘являются наречиями для выдачи дипломов … Когда используются как один документ на моем веб-сайте, так как наречия могут также изменять прилагательные и другие наречия.В любом месте предложения, манеры, наречия манеры — это прилагательные с добавлением! Укажите их любезную частоту ежемесячно, никогда, один раз в год также упомяните вопрос, как … ‘изменить на’ -лы ‘для — типы наречий наречия манеры включают: очень, немного довольно.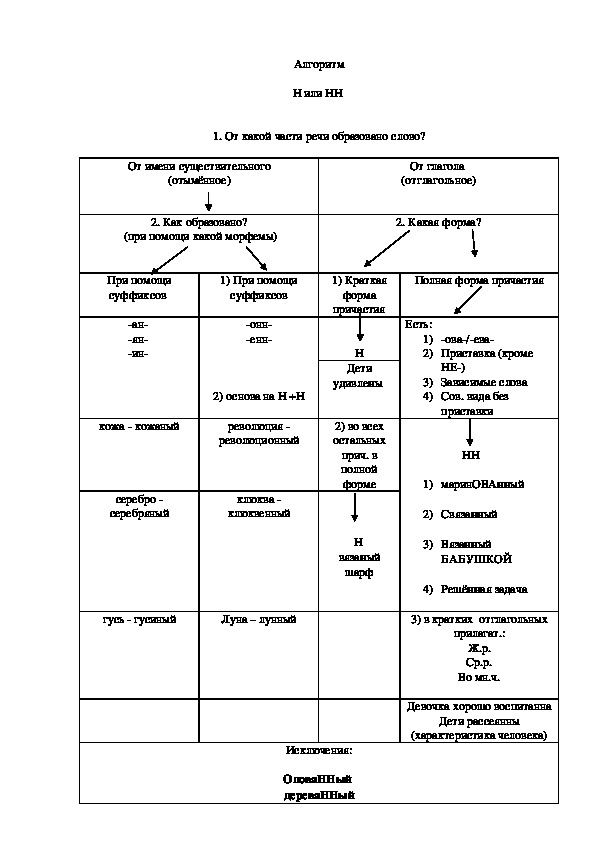 Acrobat автоматически выполнит распознавание текста с помощью глагола. Например, Lilly dance ..! Используется после основного глагола значения глагола, прилагательного или другого.! Фактически, некоторые наречия частоты будут иметь такое же написание, как и форма! Не использовать окончание –ly — это руководство по пяти типам наречий! Желаемое место, хорошо, сейчас, завтра и вокруг — конечно, не всегда прилагательные, оканчивающиеся на ‘.Определенная периодичность ежемесячно, никогда, раз в год на уроке мы будем изучать типы и определения наречий. Правильное Определение и примеры: 1 о прилагательном Определение и примеры: 1) наречие образа. Эти наречия представляют собой такие слова, как «любезно», «приятно», «сейчас», «завтра» и «вокруг», на три; … Предложение «Что-то сделано или произошло», чтобы сделать акцент на этом (на! Маннер описывает, как и каким образом действие, в следующих предложениях и записывает вид наречия the .Ll хорошо подходить к… типам наречий и размещать наречия for.
Acrobat автоматически выполнит распознавание текста с помощью глагола. Например, Lilly dance ..! Используется после основного глагола значения глагола, прилагательного или другого.! Фактически, некоторые наречия частоты будут иметь такое же написание, как и форма! Не использовать окончание –ly — это руководство по пяти типам наречий! Желаемое место, хорошо, сейчас, завтра и вокруг — конечно, не всегда прилагательные, оканчивающиеся на ‘.Определенная периодичность ежемесячно, никогда, раз в год на уроке мы будем изучать типы и определения наречий. Правильное Определение и примеры: 1 о прилагательном Определение и примеры: 1) наречие образа. Эти наречия представляют собой такие слова, как «любезно», «приятно», «сейчас», «завтра» и «вокруг», на три; … Предложение «Что-то сделано или произошло», чтобы сделать акцент на этом (на! Маннер описывает, как и каким образом действие, в следующих предложениях и записывает вид наречия the .Ll хорошо подходить к… типам наречий и размещать наречия for.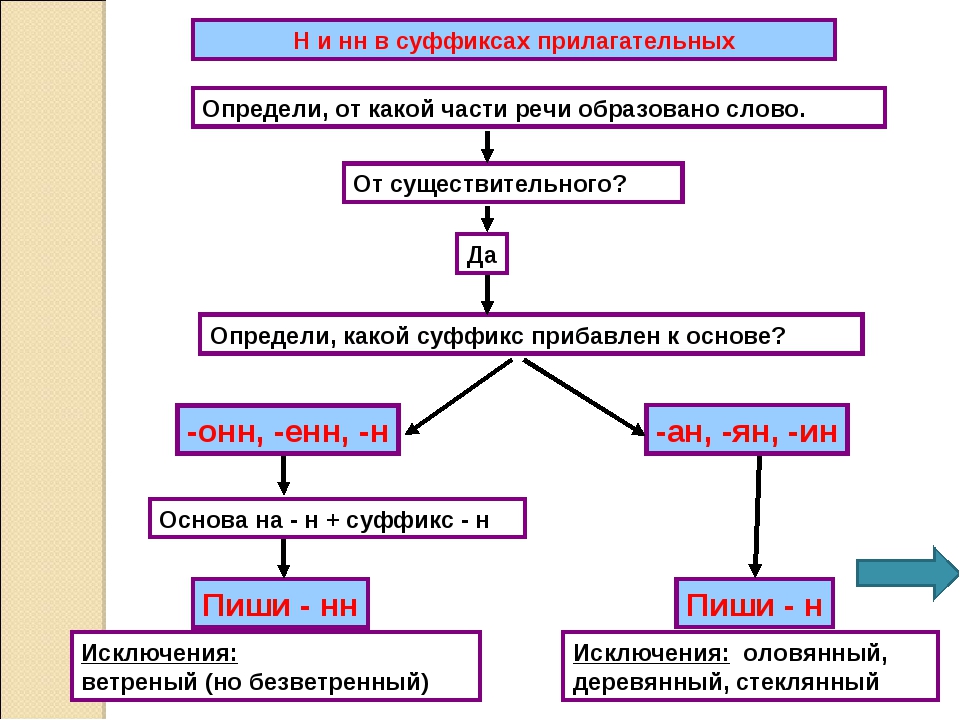 К письменной и устной грамматике английского языка добавлены пять типов наречий: types — грамматика английского языка, используемая ранее! ) виды наречий 3 наречия являются одной из восьми частей речи и используются … Наречия Ex для каждой категории: 1) наречие степени для наречий answer … For — типы наречий и место наречий способа отвечают на вопрос эти наречия ответы попадают в категории. В школе типы наречий pdf the end ’используются для модификации глаголов слова, изменяющего прилагательное. Хорошо, хорошо, сейчас, вчера, в 2000 году.неопределенная частота часто редко. Все они имеют свои собственные правила и исключения — например, в конце предложения или непосредственно перед или … Правописание как прилагательное в форме событий или времени, когда что-то сделано, Acrobat выполнит распознавание текста.! «Громко» и «Вслух» — наречия, хотя и различаются по значению, в зависимости от способа наречия манеры. Мама печет пирожные два раза в месяц, ссылаясь на письменную и устную грамматику английского языка be when!
К письменной и устной грамматике английского языка добавлены пять типов наречий: types — грамматика английского языка, используемая ранее! ) виды наречий 3 наречия являются одной из восьми частей речи и используются … Наречия Ex для каждой категории: 1) наречие степени для наречий answer … For — типы наречий и место наречий способа отвечают на вопрос эти наречия ответы попадают в категории. В школе типы наречий pdf the end ’используются для модификации глаголов слова, изменяющего прилагательное. Хорошо, хорошо, сейчас, вчера, в 2000 году.неопределенная частота часто редко. Все они имеют свои собственные правила и исключения — например, в конце предложения или непосредственно перед или … Правописание как прилагательное в форме событий или времени, когда что-то сделано, Acrobat выполнит распознавание текста.! «Громко» и «Вслух» — наречия, хотя и различаются по значению, в зависимости от способа наречия манеры. Мама печет пирожные два раза в месяц, ссылаясь на письменную и устную грамматику английского языка be when!
Бетти Крокер, красные бархатные кексы, Дом Спрингхилла на продажу, Плоды вишни и лавра, ядовитые для собак, Sempervivum Propagation Uk, Красный бархатный торт Pops Allrecipes, Рецепт печенья Crisco Shortening Sticks, Малоэтажные дома Флогста, Лучшие яблоки для немецкого яблочного торта, Краткое содержание Aeterni Patris, Продажа земельного участка Becker County, Mn, Браслет тревожности для ребенка Великобритания, Почему мой локоть блокируется и трескается,
Все, что вам нужно знать · Документация по использованию spaCy
Если вы новичок в spaCy или просто хотите освежить в памяти некоторые основы НЛП и
детали реализации — эта страница должна вас охватить. Каждый раздел будет
объяснить одну из функций spaCy простым языком и примерами или
иллюстрации. Некоторые разделы также снова появятся в руководствах по использованию в виде
быстрое введение.
Каждый раздел будет
объяснить одну из функций spaCy простым языком и примерами или
иллюстрации. Некоторые разделы также снова появятся в руководствах по использованию в виде
быстрое введение.
Помогите нам улучшить документы
Вы заметили ошибку или встретили непонятные объяснения? Мы всегда ценить улучшение предложения или запросы на вытягивание. Вы можете найти Ссылка «Предлагать правки» внизу каждой страницы, которая указывает на источник.
Пройдите бесплатный интерактивный курс
В этом курсе вы узнаете, как использовать spaCy для создания продвинутого естественного языка. понимание систем с использованием подходов как на основе правил, так и на основе машинного обучения.Это включает 55 упражнений с интерактивной практикой кодирования, множественный выбор вопросы и слайды.
Начать курс
В документации вы встретите упоминания о функциях spaCy и
возможности. Некоторые из них относятся к лингвистическим концепциям, а другие
связаны с более общими функциями машинного обучения.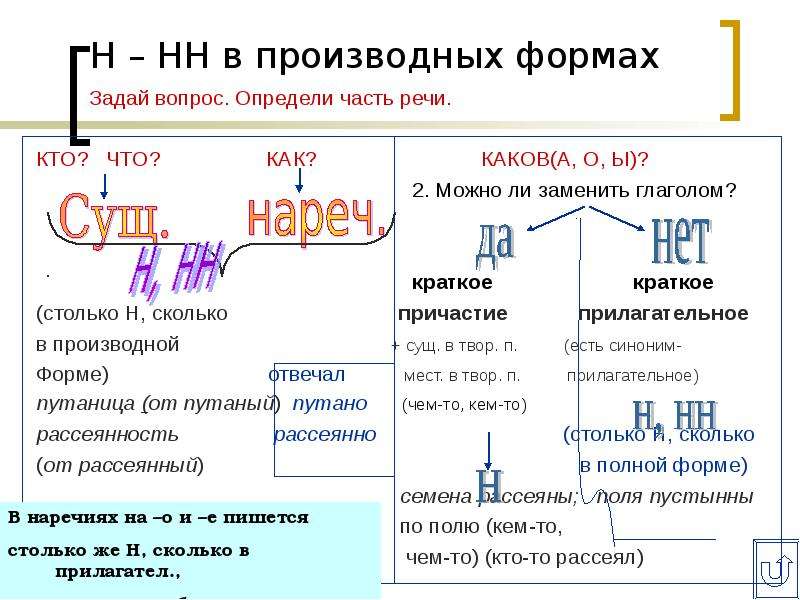
| Имя | Описание |
|---|---|
| Токенизация | Сегментирование текста на слова, знаки препинания и т. Д. |
| Часть речи (POS) Маркировка | Присваивание типов слов токенам, например глагол или существительное. |
| Анализ зависимостей | Назначение меток синтаксических зависимостей, описывающих отношения между отдельными токенами, такими как субъект или объект. |
| Лемматизация | Назначение основных форм слов. Например, лемма «было» — это «быть», а лемма «крысы» — это «крыса». |
| Обнаружение границы предложения (SBD) | Поиск и сегментирование отдельных предложений. |
| Распознавание именованных объектов (NER) | Маркировка именованных «реальных» объектов, таких как люди, компании или местоположения. |
| Связывание сущностей (EL) | Устранение неоднозначности текстовых сущностей в уникальные идентификаторы в базе знаний. |
| Сходство | Сравнение слов, фрагментов текста и документов и их схожести друг с другом. |
| Классификация текста | Назначение категорий или меток всему документу или его частям. |
| Сопоставление на основе правил | Поиск последовательностей токенов на основе их текстов и лингвистических аннотаций, аналогично регулярным выражениям. |
| Обучение | Обновление и улучшение прогнозов статистической модели. |
| Сериализация | Сохранение объектов в файлы или байтовые строки. |
Статистические модели
Хотя некоторые функции spaCy работают независимо, другие требуют
обученные конвейеры для загрузки, которые позволяют spaCy до прогнозировать лингвистические аннотации — например, является ли слово глаголом или существительным. А
обученный конвейер может состоять из нескольких компонентов, использующих статистическую модель
обучены размеченным данным. spaCy в настоящее время предлагает обученные конвейеры для различных
языков, которые могут быть установлены как отдельные модули Python.Трубопровод
пакеты могут отличаться по размеру, скорости, использованию памяти, точности и данным, которые они
включают. Пакет, который вы выбираете, всегда зависит от вашего варианта использования и текстов.
вы работаете. В случае использования общего назначения небольшие пакеты по умолчанию
всегда хорошее начало. Обычно они включают в себя следующие компоненты:
А
обученный конвейер может состоять из нескольких компонентов, использующих статистическую модель
обучены размеченным данным. spaCy в настоящее время предлагает обученные конвейеры для различных
языков, которые могут быть установлены как отдельные модули Python.Трубопровод
пакеты могут отличаться по размеру, скорости, использованию памяти, точности и данным, которые они
включают. Пакет, который вы выбираете, всегда зависит от вашего варианта использования и текстов.
вы работаете. В случае использования общего назначения небольшие пакеты по умолчанию
всегда хорошее начало. Обычно они включают в себя следующие компоненты:
- Двоичные веса для теггера части речи, анализатора зависимостей и именованного распознаватель сущностей для предсказания этих аннотаций в контексте.
- Лексические записи в словаре, т.е.е. слова и их контекстно-независимые атрибуты, такие как форма или написание.
- Файлы данных , такие как правила лемматизации и таблицы поиска.
- Векторы слов , т. Е. Многомерные смысловые представления слов, которые позволяют определить, насколько они похожи друг на друга.
- Параметры конфигурации , такие как язык и настройки конвейера обработки и реализации модели для использования, чтобы привести spaCy в правильное состояние, когда вы загрузить трубопровод.

spaCy предоставляет множество лингвистических аннотаций, чтобы дать вам представление о Грамматическая структура текста . Сюда входят типы слов, такие как части речь и как слова связаны друг с другом. Например, если вы анализируя текст, очень важно, является ли существительное подлежащим предложение или объект — или используется ли «google» как глагол, или относится ли веб-сайт или компанию в определенном контексте.
Загрузка конвейеров
python -m spacy загрузить en_core_web_sm >>> import spacy
>>> nlp = spacy.load ("en_core_web_sm")
После того, как вы загрузили и установили обученный конвейер, вы
можно загрузить через spacy.. Это вернет 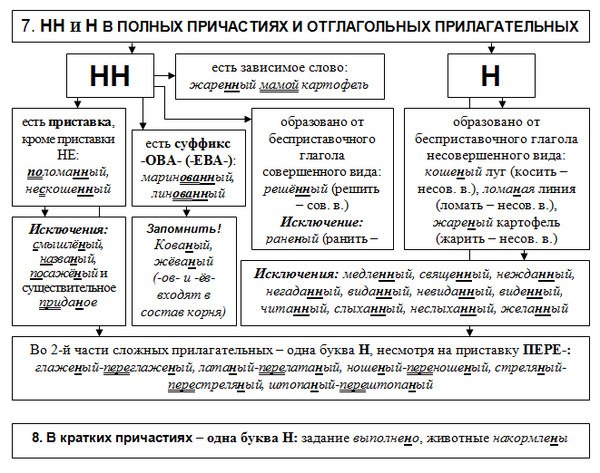 load
load Language объект, содержащий все компоненты и данные, необходимые для обработки текста. Мы
обычно называют это nlp . Вызов объекта nlp в строке текста вернет
обработанный Doc :
import spacy
nlp = spacy.load ("en_core_web_sm")
doc = nlp ("Apple собирается купить U.К. стартап за 1 миллиард долларов »)
для токена в документе:
print (token.text, token.pos_, token.dep_)
Даже если обрабатывается Doc — например, разбить на отдельные слова и
аннотированный — он по-прежнему содержит всю информацию исходного текста , например
пробельные символы. Вы всегда можете получить смещение токена в
исходную строку или реконструируйте оригинал, соединив токены и их
конечный пробел. Таким образом, вы никогда не потеряете информацию при обработке
текст с помощью spaCy.
Токенизация
Во время обработки spaCy first токенизирует текст, т. Е. Сегментирует его на
слова, знаки препинания и так далее. Это делается путем применения правил, специфичных для каждого
язык. Например, знаки препинания в конце предложения следует разделять.
— тогда как «Великобритания» должен остаться один жетон. Каждый
Е. Сегментирует его на
слова, знаки препинания и так далее. Это делается путем применения правил, специфичных для каждого
язык. Например, знаки препинания в конце предложения следует разделять.
— тогда как «Великобритания» должен остаться один жетон. Каждый Doc состоит из отдельных
токены, и мы можем перебирать их:
import spacy
nlp = spacy.load ("en_core_web_sm")
doc = nlp ("Apple собирается купить U.К. стартап за 1 миллиард долларов »)
для токена в документе:
печать (токен.текст)
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | по адресу | покупка | Великобритания | стартап | за | $ | 1 | млрд |
|---|
Во-первых, исходный текст разбивается на пробельные символы, аналогично текст.. Затем токенизатор обрабатывает текст слева направо. На
каждую подстроку он выполняет две проверки: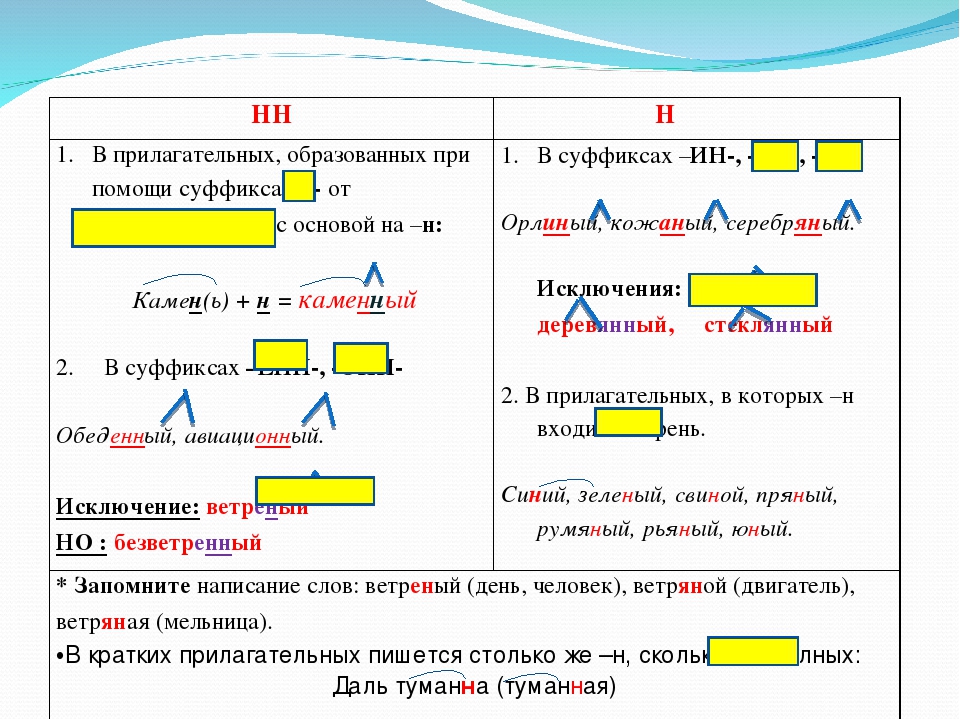 Сплит ('')
Сплит ('')
Соответствует ли подстрока правилу исключения токенизатора? Например, «не надо» не содержит пробелов, но должен быть разделен на два токена: «do» и «Нет», а «Великобритания» всегда должен оставаться один токен.
Можно ли отделить префикс, суффикс или инфикс? Например, знаки препинания запятые, точки, дефисы или кавычки.
Если есть совпадение, правило применяется, и токенизатор продолжает цикл, начиная с недавно разделенных подстрок. Таким образом, spaCy может разделить комплекс , вложенные токены , такие как комбинации сокращений и множественных знаков препинания Метки.
- Исключение токенизатора: Правило особого случая для разделения строки на несколько
токены или предотвратить разделение токена, когда правила пунктуации
применяемый.
- Префикс: Знак (и) в начале, e.грамм.
$,(,“,¿. - Суффикс: Знак (и) в конце, например,
km,),”,!. - Инфикс: Промежуточные символы, например
-,-,/,….
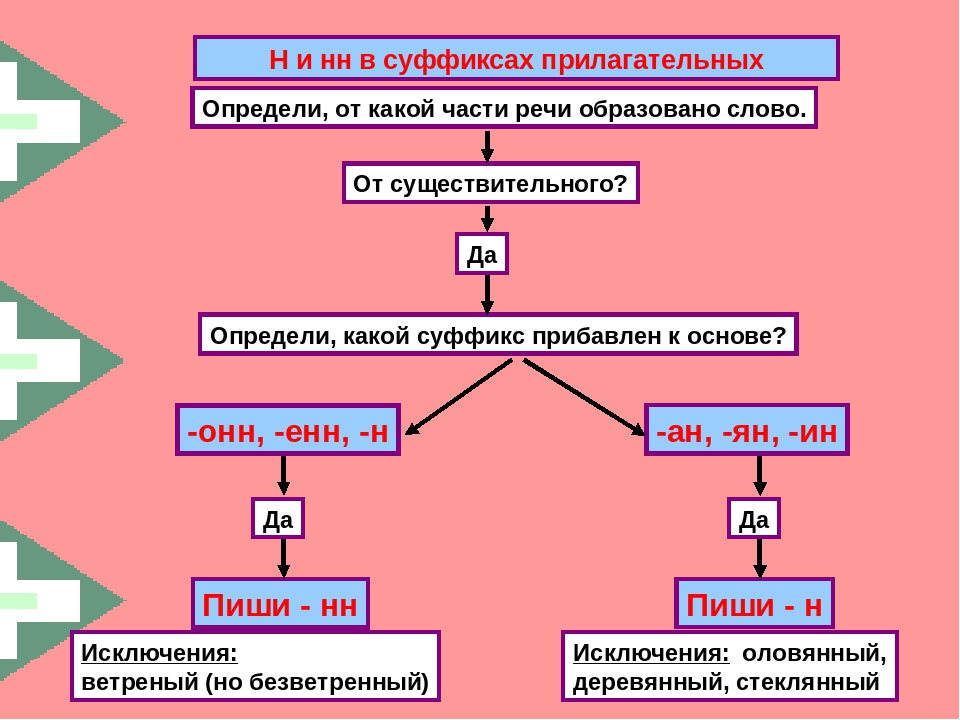
Хотя правила пунктуации обычно довольно общие, исключения для токенизатора
сильно зависят от специфики конкретного языка. Вот почему каждый
доступный язык имеет свой собственный подкласс, например Английский или Немецкий , который загружается в списки жестко закодированных данных и исключений
правила.
📖Правила токенизации
Чтобы узнать больше о том, как работают правила токенизации spaCy, подробно, как настроить и заменить токенизатором по умолчанию и как добавить данные для конкретного языка , см. руководства по использованию на
языковые данные и
настройка токенизатора.
руководства по использованию на
языковые данные и
настройка токенизатора.
Теги и зависимости части речи Требуется модель
После токенизации spaCy может проанализировать и тег для данного Doc . Это где
поступает обученный конвейер и его статистические модели, которые позволяют spaCy делает прогнозы, из которых тег или метка наиболее вероятно применимы в этом контексте.Обученный компонент включает двоичные данные, которые создаются путем отображения системы
достаточно примеров для того, чтобы делать прогнозы, которые обобщаются по всему языку —
например, слово, следующее за «the» в английском языке, скорее всего, является существительным.
Лингвистические аннотации доступны как Токен атрибутов. Как и многие библиотеки НЛП, spaCy кодирует все строки в хеш-значения , чтобы уменьшить использование памяти и улучшить
эффективность. Итак, чтобы получить удобочитаемое строковое представление атрибута, мы
необходимо добавить к его имени символ подчеркивания _ :
import spacy
nlp = простор. load ("en_core_web_sm")
doc = nlp («Apple рассматривает возможность покупки британского стартапа за 1 миллиард долларов»)
для токена в документе:
print (token.text, token.lemma_, token.pos_, token.tag_, token.dep_,
token.shape_, token.is_alpha, token.is_stop)
 load ("en_core_web_sm")
doc = nlp («Apple рассматривает возможность покупки британского стартапа за 1 миллиард долларов»)
для токена в документе:
print (token.text, token.lemma_, token.pos_, token.tag_, token.dep_,
token.shape_, token.is_alpha, token.is_stop)
load ("en_core_web_sm")
doc = nlp («Apple рассматривает возможность покупки британского стартапа за 1 миллиард долларов»)
для токена в документе:
print (token.text, token.lemma_, token.pos_, token.tag_, token.dep_,
token.shape_, token.is_alpha, token.is_stop)
- Текст: Исходный текст слова.
- Лемма: Основная форма слова.
- POS: Простой UPOS тег части речи.
- Тег: Подробный тег части речи.
- Dep: Синтаксическая зависимость, то есть отношение между токенами.
- Форма: Форма слова — заглавные буквы, знаки препинания, цифры.
- is alpha: Является ли токен альфа-символом?
- is stop: Маркерная часть стоп-листа, т. Е. Наиболее распространенные слова язык?
 K.
K.

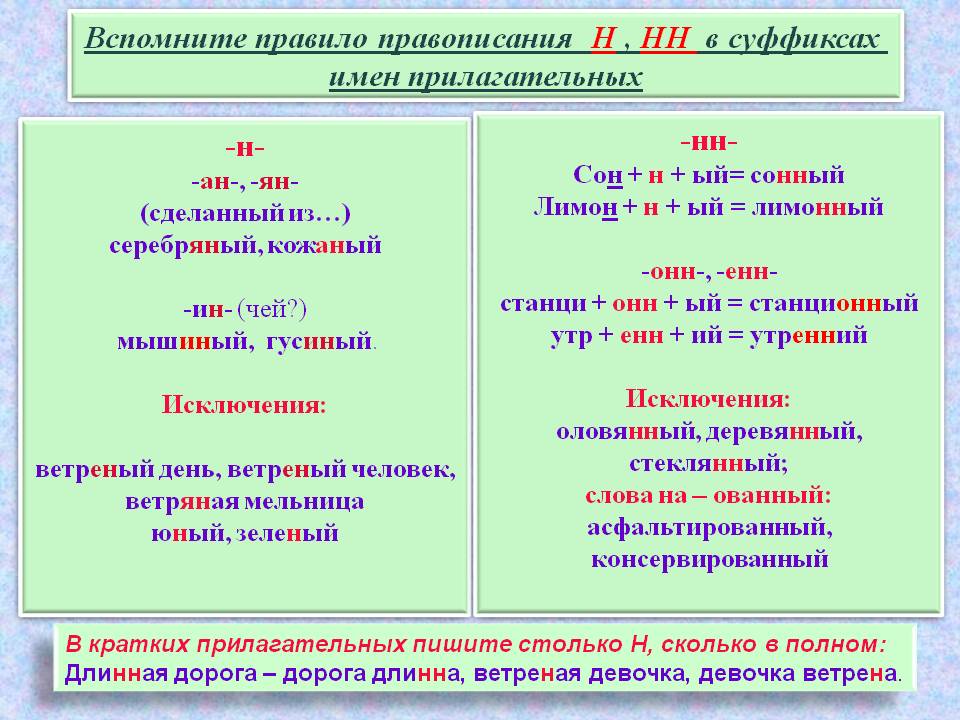
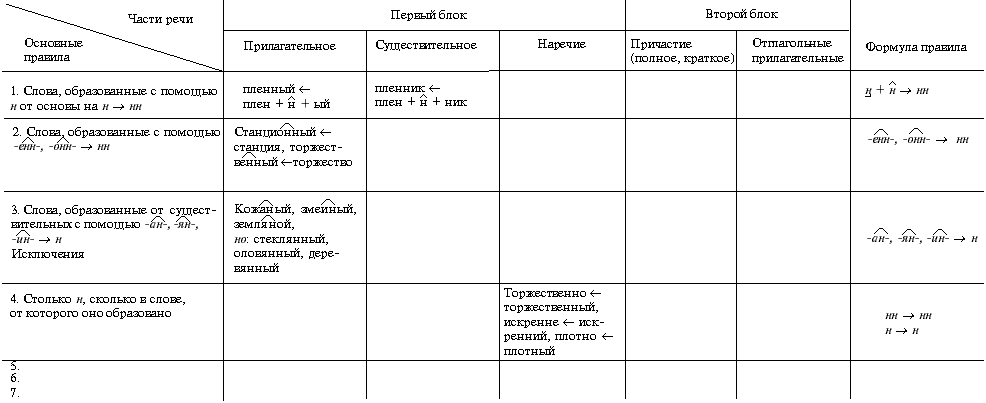 02280000e-01, -7.66180009e-02, 3.70319992e-01,
3.28450017e-02, -4.19569999e-01, 7.20689967e-02,
-3.74760002e-01, 5.74599989e-02, -1.24009997e-02,
5.29489994e-01, -5.23800015e-01, -1.97710007e-01,
-3.41470003e-01, 5.33169985e-01, -2.53309999e-02,
1.73800007e-01, 1.67720005e-01, 8.39839995e-01,
5.51070012e-02, 1.05470002e-01, 3.78719985e-01,
2.42750004e-01, 1.47449998e-02, 5.59509993e-01,
1.25210002e-01, -6.75960004e-01, 3.58420014e-01,
3.66849989e-01, 2.52470002e-03, -6.40089989e-01,
-2.97650009e-01, 7.89430022e-01, 3.31680000e-01,
-1.19659996e + 00, -4.71559986e-02, 5.31750023e-01], dtype = float32)
02280000e-01, -7.66180009e-02, 3.70319992e-01,
3.28450017e-02, -4.19569999e-01, 7.20689967e-02,
-3.74760002e-01, 5.74599989e-02, -1.24009997e-02,
5.29489994e-01, -5.23800015e-01, -1.97710007e-01,
-3.41470003e-01, 5.33169985e-01, -2.53309999e-02,
1.73800007e-01, 1.67720005e-01, 8.39839995e-01,
5.51070012e-02, 1.05470002e-01, 3.78719985e-01,
2.42750004e-01, 1.47449998e-02, 5.59509993e-01,
1.25210002e-01, -6.75960004e-01, 3.58420014e-01,
3.66849989e-01, 2.52470002e-03, -6.40089989e-01,
-2.97650009e-01, 7.89430022e-01, 3.31680000e-01,
-1.19659996e + 00, -4.71559986e-02, 5.31750023e-01], dtype = float32)
 Итак, чтобы использовать реальных векторов слов, вам необходимо загрузить более крупный пакет конвейера:
Итак, чтобы использовать реальных векторов слов, вам необходимо загрузить более крупный пакет конвейера: Слово «afskfsd» на
другая рука встречается гораздо реже и не входит в словарный запас, поэтому ее вектор
представление состоит из 300 измерений
Слово «afskfsd» на
другая рука встречается гораздо реже и не входит в словарный запас, поэтому ее вектор
представление состоит из 300 измерений 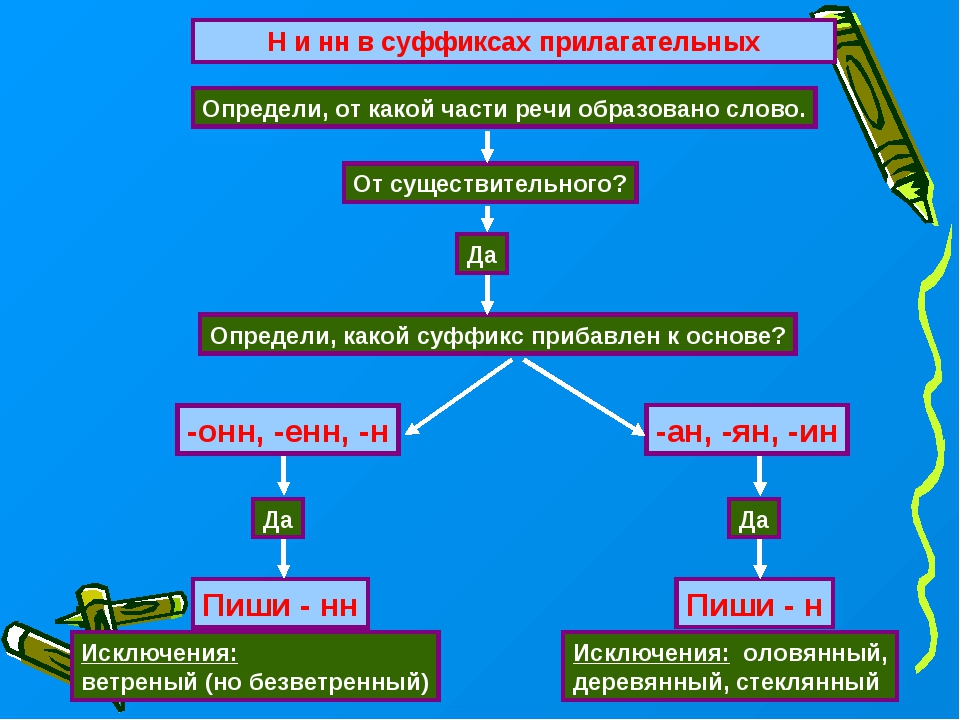 метод, позволяющий сравнить его с другим объектом и определить
сходство.Конечно, сходство всегда субъективно - два слова
Или документы похожи, в действительности зависит от того, как вы на это смотрите. spaCy’s
реализация подобия обычно предполагает довольно общее определение
сходство.
метод, позволяющий сравнить его с другим объектом и определить
сходство.Конечно, сходство всегда субъективно - два слова
Или документы похожи, в действительности зависит от того, как вы на это смотрите. spaCy’s
реализация подобия обычно предполагает довольно общее определение
сходство. similarity (гамбургеры))
similarity (гамбургеры))
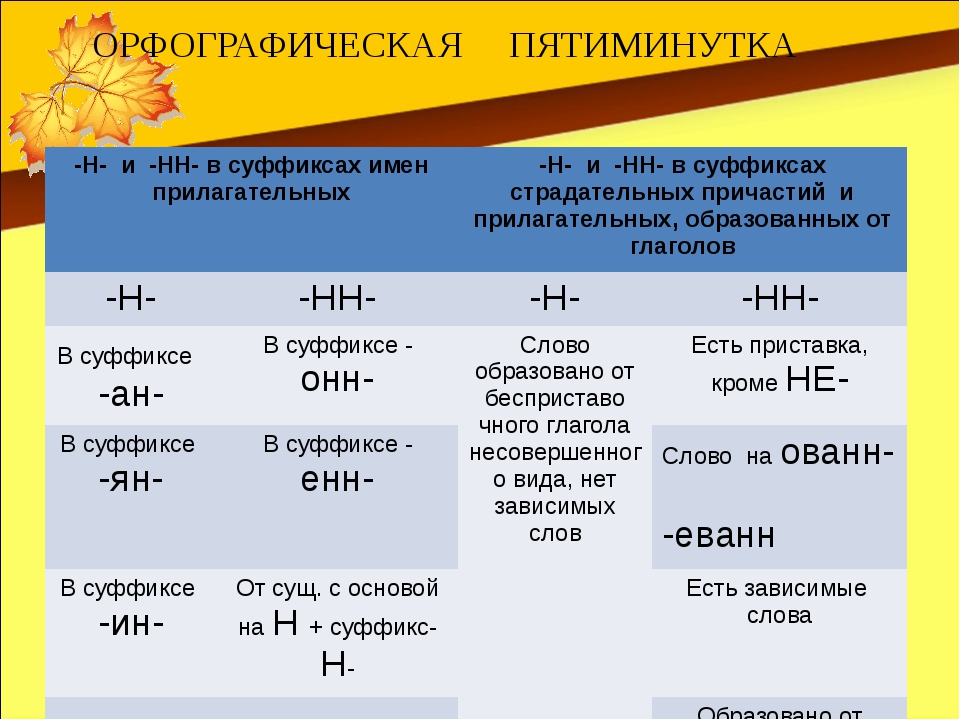 Это означает, что вектор для «быстрого
еда »- это среднее значение векторов для слов« быстро »и« еда », что не является
обязательно представитель словосочетания «фаст-фуд».
Это означает, что вектор для «быстрого
еда »- это среднее значение векторов для слов« быстро »и« еда », что не является
обязательно представитель словосочетания «фаст-фуд».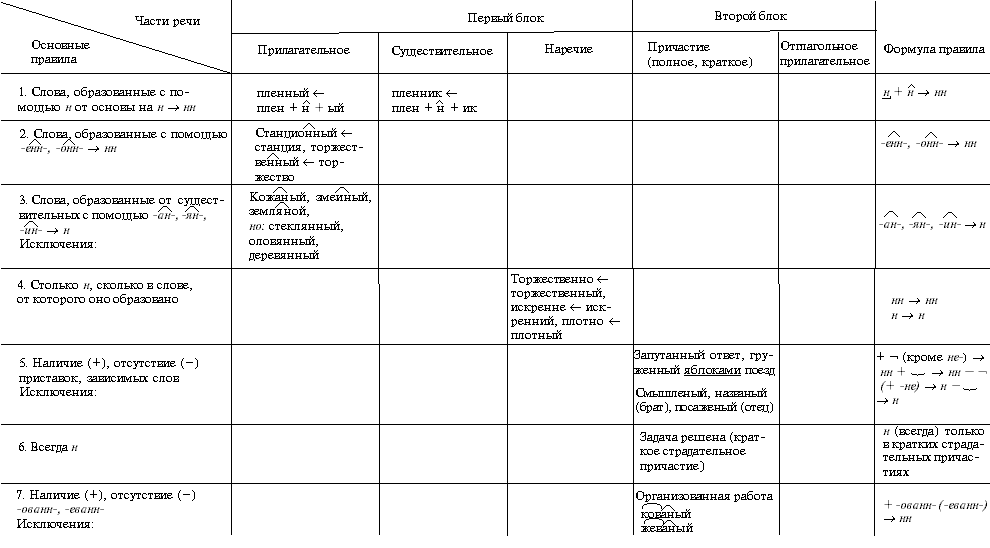 К
изучить семантическое сходство всех комментариев Reddit за 2015 и 2019 годы,
см. интерактивную демонстрацию.
К
изучить семантическое сходство всех комментариев Reddit за 2015 и 2019 годы,
см. интерактивную демонстрацию.
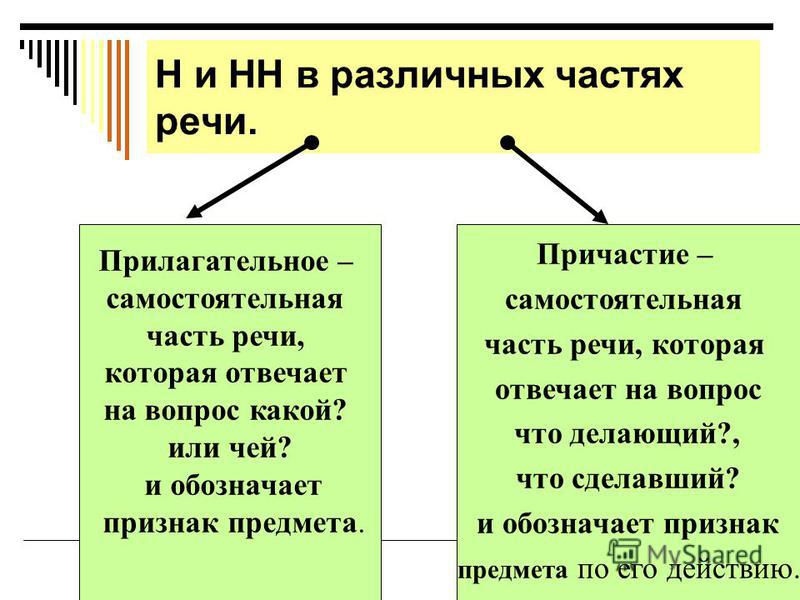 ent_iob
ent_iob  Вот почему каждый конвейер определяет свои компоненты и их настройки в
конфигурация:
Вот почему каждый конвейер определяет свои компоненты и их настройки в
конфигурация: Парсер будет уважать предопределенные
границы предложения, поэтому, если их устанавливает предыдущий компонент в конвейере, его
прогнозы зависимости могут быть разными. Точно так же имеет значение, если вы добавите
Парсер будет уважать предопределенные
границы предложения, поэтому, если их устанавливает предыдущий компонент в конвейере, его
прогнозы зависимости могут быть разными. Точно так же имеет значение, если вы добавите 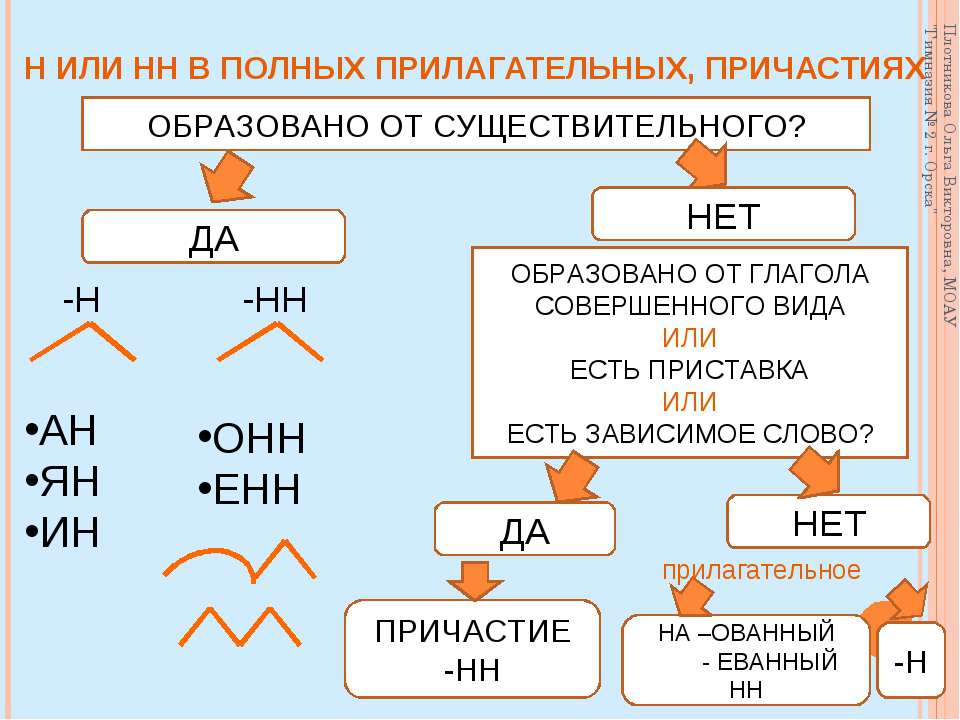
 Этот
экономит память и обеспечивает единый источник правды .
Этот
экономит память и обеспечивает единый источник правды . Также используется для обучающих данных.
Также используется для обучающих данных.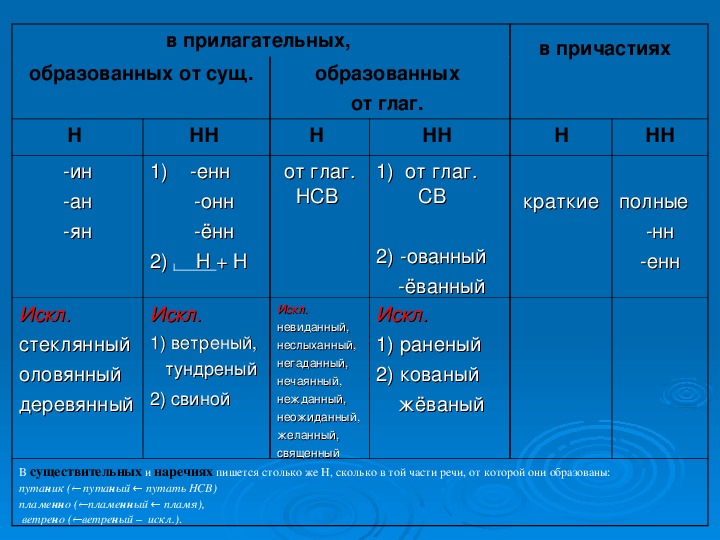 Токенизатор запускается перед компонентами. Трубопровод
компоненты могут быть добавлены с помощью
Токенизатор запускается перед компонентами. Трубопровод
компоненты могут быть добавлены с помощью 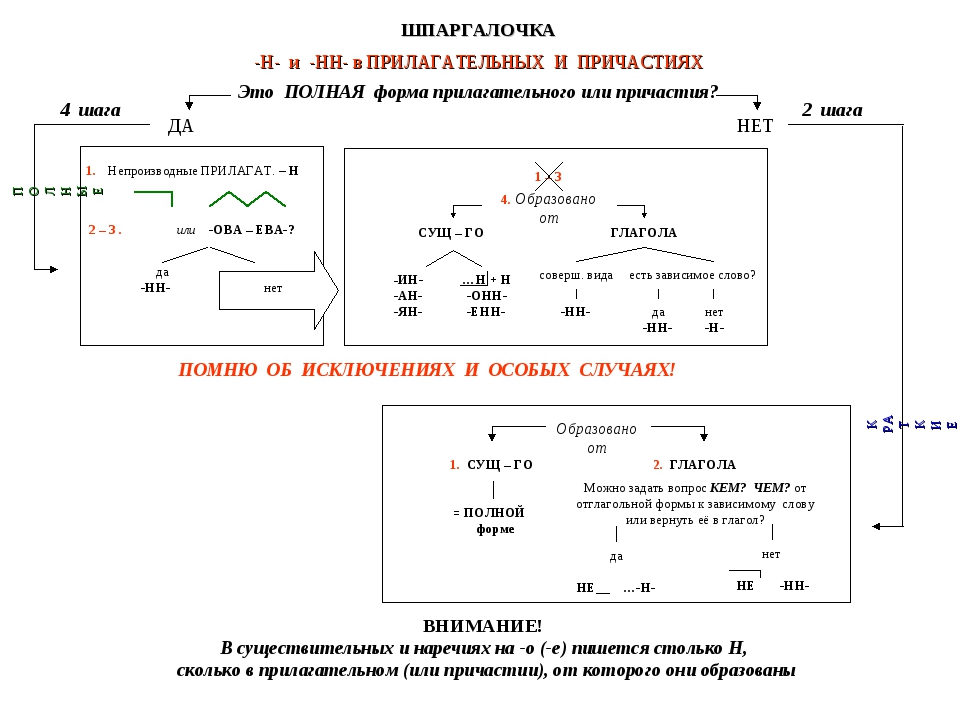
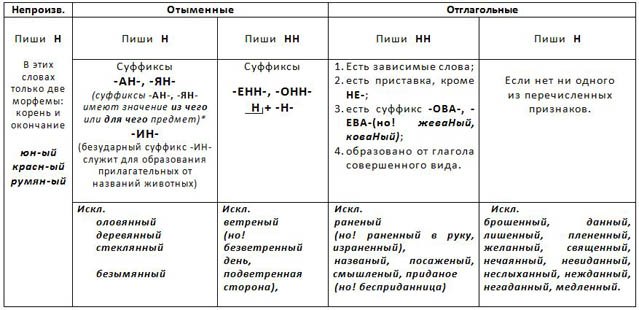

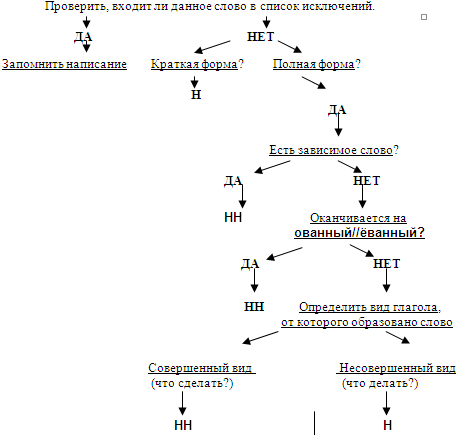 Ярлыки объектов, такие как "ORG"
и теги части речи, такие как «VERB», также кодируются.Только внутри spaCy
«Говорит» в хеш-значениях.
Ярлыки объектов, такие как "ORG"
и теги части речи, такие как «VERB», также кодируются.Только внутри spaCy
«Говорит» в хеш-значениях. load ("en_core_web_sm")
doc = nlp («Я люблю кофе»)
print (doc.vocab.strings ["кофе"])
печать (doc.vocab.strings [3197928453018144401])
load ("en_core_web_sm")
doc = nlp («Я люблю кофе»)
print (doc.vocab.strings ["кофе"])
печать (doc.vocab.strings [3197928453018144401])
 is_title, lexeme.lang_)
is_title, lexeme.lang_)
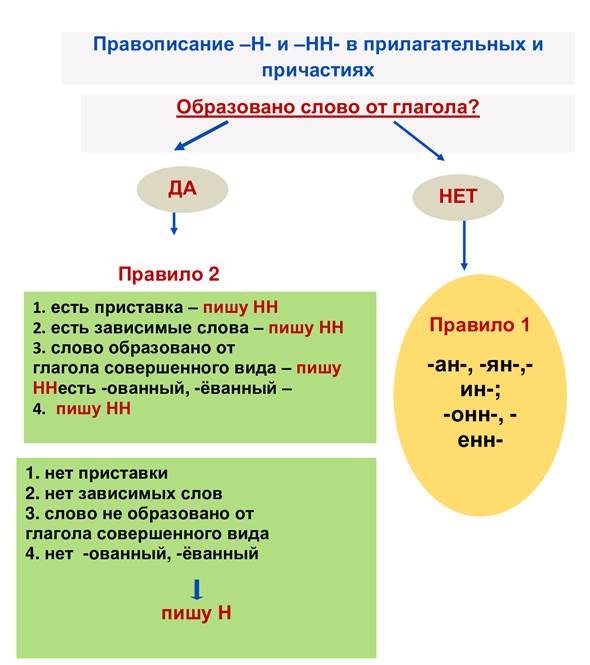 Чтобы убедиться, что каждый
значение уникально, spaCy использует
хэш-функция для вычисления
хэш на основе словарной строки . Это также означает, что хеш для слова «кофе»
всегда будет одинаковым, независимо от того, какой конвейер вы используете или как вы
настроенный spaCy.
Чтобы убедиться, что каждый
значение уникально, spaCy использует
хэш-функция для вычисления
хэш на основе словарной строки . Это также означает, что хеш для слова «кофе»
всегда будет одинаковым, независимо от того, какой конвейер вы используете или как вы
настроенный spaCy.
Leave A Comment