
ГДЗ География Алексеев 7 класс Стр. 12
Содержание
Авторы:Алексеев, Николина
Год:2022
Тип:учебник
Содержание
- Вопросы в конце параграфа
Параграф 3. Как люди заселяли Землю
Вопросы в конце параграфа
1. Покажите на карте Восточную Африку, Южную Азию, Южную Европу, Северную Америку, Южную Америку, Северный Ледовитый океан, Тихий океан, Берингов пролив, остров Огненная Земля, остров Гренландия.
2. Как человек стал расселяться по Земле?
Человек стал расселяться из-за роста численности населения и необходимости заселения новых территорий, продвигаясь на новые земли.
3. Как возникли земледелие и животноводство?
Земледелие возникло за счет того, что люди поняли, что необязательно только собирать растения для пищи, из их семян можно и выращивать плоды, причем это позволяло запасаться необходимым количеством пищи намного проще, чем при собирательстве.
4. Почему люди стали заселять земли с более суровыми природными условиями?
Люди стали заселять земли с более суровыми природными условиями, так как численность населения на территориях возрастала, ресурсов становилось меньше, и за них необходимо было бороться, тогда побеждённые люди уходили на новые менее пригодные для жизни земли.
5. Расскажите о жизни людей на берегу Северного Ледовитого океана.
На берегу Северного Ледовитого океана главным занятием населения является охота на морского зверя и рыболовство, вокруг этих ремёсел строится всё остальное. Добыча даёт и пищу и сырьё для изготовления вещей (одежды, орудий труда и так далее). Также развито оленеводство, коренные народы кочуют вместе со стадами и олень играет в их жизни также основную роль и пищи и сырья. Природные условия побережья Северного Ледовитого океана крайне суровы, здесь низкие температуры воздуха зимой, короткое и холодное лето, повышенная влажность воздуха, пронизывающие ветра.
6. Расскажите о хозяйственной деятельности людей в пустыне.
В пустыне люди занимаются орошаемым земледелием в оазисах или в долинах крупных рек, например, как в долине реки Нил, выращивая пшеницу, рис, кукурузу и другие культурные растения. Также население занимается пастбищным или кочевым животноводством (овцеводство, верблюдоводство, козоводство).
7. Найдите в тексте параграфа образные выражения, которые помогают понять, как человек приспосабливался к новым жизненным условиям.
Образные выражения из текста параграфа, помогающие понять, как человек приспосабливался к новым жизненным условиям: «Столкновения за место под солнцем»; «требовалась работа мысли».
8. Какие вы знаете способы приспособления человека к различным природным условиям: влажным или засушливым местам, высоким и низким температурам, ветрам, горному рельефу и т. д.? Иллюстрируйте рассказ фотографиями, собственными рисунками.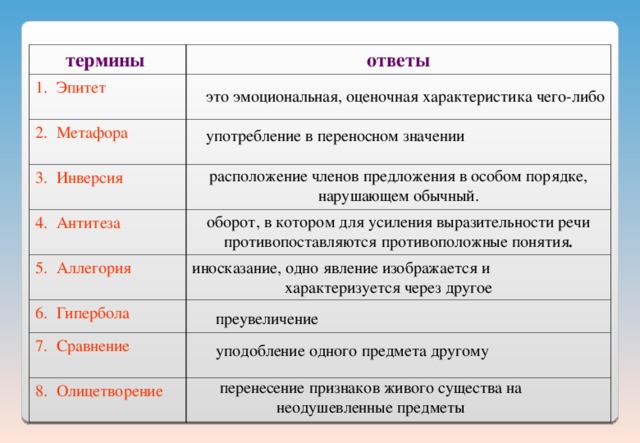
Способы приспособления человека к различным природным условиям:
Во влажных тропиках или на островах Тихого океана, где возможно подтопление жилища, их строят на сваях выше уровня земли.
В дождливых районах Земли крыши остроконечные, чтобы влага не задерживалась.
В пустынях и жарких странах крыши, как правило, плоские, чтобы при осадках «собрать» воду, также стены домов сделаны из белого камня или иного материала, чтобы он меньше нагревался.
В степях для защиты от пронизывающих зимних ветров около домов высаживают деревья.
В северных странах или в условиях климата когда зима морозная, для утепления домов и построек используют снег, который нагребают к стенам домов и построек.
Ошибка или идея? Сообщить 📤
Мне не нравится на сайте, измените:Сделайте так, чтобы можно было:Решение неправильно/опечатка
Бот с ответами МЭШ | Скайсмарт
Все номера
Стр. 8Стр. 12Стр. 15Стр. 19Стр. 23Стр. 27Стр. 28Стр. 29Стр. 30Стр. 35
28Стр. 29Стр. 30Стр. 35
14.02.2022 Городской мастер-класс «Смысловое чтение как инструмент реализации ФГОС образования»
+7 (812) 628-78-28, +7 (812) 956-67-42, +7 (921) 856-03-61, +7 (921) 856-03-62
- Подробности
- Просмотров: 8554
Для педагогов дошкольного образования, начального образования, среднего образования, коррекционного образования
Городской мастер-класс
Дата проведения: 14.02.2022
Время проведения: 16:00 — 17:00
Цель: ознакомление слушателей с технологией смыслового чтения для формирования интеллектуального потенциала детей дошкольного и школьного возраста.
Вопросы для обсуждения:
- Понятие смыслового чтения и его место в образовательном процессе.
- Навык смыслового чтения – важнейшая компетенция человека XXI века.
- Приемы формирования навыков смыслового чтения у детей дошкольного и школьного возраста.
Скачать презентацию
Список секций:
Секция 1. «Кризис читательской культуры и грамотности современного общества»
Секция 2. «Мои приемы восприятия художественных произведений для детей»
Записаться на мероприятие и оставить свои тезисы
Вам также может быть интересно:
- 10.
 05.2023 Всероссийский семинар «Формирование цветовосприятия детей школьного возраста в художественно-творческой деятельности »
Дворцова Анастасия Алексеевна
2023-05-10 19:30
05.2023 Всероссийский семинар «Формирование цветовосприятия детей школьного возраста в художественно-творческой деятельности »
Дворцова Анастасия Алексеевна
2023-05-10 19:30 - 27.04.2023 Курс повышения квалификации (КПК) «»Оказание первой доврачебной помощи» (18 часов)» Лузанова Нина Николаевна 2023-04-27 18:42
- 05.05.2023 Городской семинар «Профориентация школьников в условиях введения обновленных ФГОС. Примерка профессий» Бузулукский, Любаскина 2023-05-05 19:00
- 18.04.2023 Всероссийский семинар «Воспитание гражданской идентичности и самостоятельности детей в группах раннего и младшего возраста» Паршукова Ирина Леонардовна 2023-04-18 19:00
- 15.04.2023 Городской мастер-класс «Моделирование открытого урока на основе ТРКМ» Жебровская Ольга Олеговна 2023-04-15 12:00
 05.2023 Всероссийский семинар «Формирование цветовосприятия детей школьного возраста в художественно-творческой деятельности »
Дворцова Анастасия Алексеевна
2023-05-10 19:30
05.2023 Всероссийский семинар «Формирование цветовосприятия детей школьного возраста в художественно-творческой деятельности »
Дворцова Анастасия Алексеевна
2023-05-10 19:30Поиск документов с встраиванием фрагментов | Автор Ajit Rajasekharan
Рисунок 1. Иллюстрирует поиск фрагментов на основе встраивания, используемый для ответа на конкретные вопросы (левая панель), а также на более широкие вопросы (правая панель). Фрагменты текста, выделенные желтым цветом, представляют собой совпадения документов с входными данными поиска, полученными с использованием вложений BERT. Правая панель представляет собой образец животных с литературными свидетельствами наличия коронавируса — размер шрифта является качественной мерой количества ссылок в литературе. В качестве источников коронавируса упоминались летучие мыши (в целом и китайские подковоносы) и птицы — летучие мыши — как источник генов альфа- и бета-коронавирусов, а птицы — как источник генов гамма- и дельтакоронавирусов. Также сообщалось о зоонозной передаче коронавируса от циветт и панголинов (бетакоронавирус). Вся приведенная выше информация была получена автоматически с использованием моделей машинного обучения без участия человека . Для общего вопроса на правой панели был создан загрузочный список путем поиска термина «животные» и результатов кластеризации по соседству с вложениями Word2vec.
Иллюстрирует поиск фрагментов на основе встраивания, используемый для ответа на конкретные вопросы (левая панель), а также на более широкие вопросы (правая панель). Фрагменты текста, выделенные желтым цветом, представляют собой совпадения документов с входными данными поиска, полученными с использованием вложений BERT. Правая панель представляет собой образец животных с литературными свидетельствами наличия коронавируса — размер шрифта является качественной мерой количества ссылок в литературе. В качестве источников коронавируса упоминались летучие мыши (в целом и китайские подковоносы) и птицы — летучие мыши — как источник генов альфа- и бета-коронавирусов, а птицы — как источник генов гамма- и дельтакоронавирусов. Также сообщалось о зоонозной передаче коронавируса от циветт и панголинов (бетакоронавирус). Вся приведенная выше информация была получена автоматически с использованием моделей машинного обучения без участия человека . Для общего вопроса на правой панели был создан загрузочный список путем поиска термина «животные» и результатов кластеризации по соседству с вложениями Word2vec. Затем этот список был отфильтрован по типам биологических объектов с использованием неконтролируемого NER с BERT, который затем был использован для создания окончательного списка животных с литературными данными, захваченными во фрагментах в виде экстрактивного резюме соответствующих документов. Животный источник COVID-19на сегодняшний день не подтверждено. Иллюстрация коронавируса, созданная в CDC
Затем этот список был отфильтрован по типам биологических объектов с использованием неконтролируемого NER с BERT, который затем был использован для создания окончательного списка животных с литературными данными, захваченными во фрагментах в виде экстрактивного резюме соответствующих документов. Животный источник COVID-19на сегодняшний день не подтверждено. Иллюстрация коронавируса, созданная в CDC. Вложения для фрагментов предложений, собранных из документа, могут служить в качестве экстрактивных сводных аспектов этого документа и потенциально ускорять его обнаружение, особенно когда пользовательский ввод является фрагментом предложения. Эти встраивания фрагментов не только дают более качественные результаты, чем традиционные системы сопоставления текстов, но также позволяют обойти проблему, присущую современным подходам к поиску, основанному на распределенном представлении, — задачу создания эффективных вложений документов, то есть одного встраивания на уровне документа, которое захватывает все аспектов документа и позволяет обнаруживать его с помощью поиска.
Примеры фрагментов предложений: «летучие мыши как источник коронавируса», «коронавирус в панголины» — короткие последовательности с одним или несколькими именными словосочетаниями, соединенными предлогами, прилагательными и т. д. , Эти выделенные связующие термины, которые в значительной степени игнорируются традиционными поисковыми системами, могут играть ключевую роль не только в определении намерений пользователя (например, «коронавирус в летучие мыши» имеет цель поиска, отличную от «летучие мыши как источник коронавируса» или «коронавирус отсутствует в летучие мыши») , но фрагменты предложения, которые их сохраняют, также могут быть ценные кандидаты-индексы, служащие в качестве экстрактивных аспектов сводки (суб-резюме) документа. Встраивая эти фрагменты предложений в соответствующее пространство для встраивания (например, BERT ) мы можем использовать входной фрагмент поиска в качестве зонда в этом пространстве встраивания для обнаружения соответствующих документов.
Поиск исчерпывающего ответа, подтвержденного литературными данными, на вопросы «Каковы животные источники COVID-19 ?» или «рецепторы, с которыми связывается коронавирус» сложно даже на крошечном наборе данных, таком как недавно выпущенный набор данных COVID-19 (размер корпуса ~ 500 МБ, ~ 13 тысяч документов, более 85 миллионов слов, около миллиона уникальных слов в нормализованный текст).
Традиционные методы поиска документов достаточно эффективны для типичного случая использования, когда ответ можно получить из нескольких документов, используя в поиске одно или несколько именных словосочетаний. Традиционные методы поиска документов также удовлетворяют следующему ограничению взаимодействия с пользователем для слов и фраз:
«то, что мы видим (результаты) — это то, что мы набрали (искали)»
Например, когда мы ищем слова и фразы ( последовательных последовательностей слов, таких как Нью-Йорк, Рио-де-Жанейро) — результаты обычно содержат введенные нами термины или их синонимы (например, поиск COVID-19 дает результаты с Sars-COV-2 или новым коронавирусом и т. д.).
д.).
Однако качество результатов имеет тенденцию к ухудшению по мере увеличения количества слов в поисковом запросе, особенно при использовании соединительных терминов между именными словосочетаниями. Это ухудшение качества результатов заметно даже по выделенным терминам в результатах этих поисковых систем.
Например, на рисунке ниже в основном существительные в «летучие мыши как источник коронавируса» выборочно выделяются текущими поисковыми системами распределенным образом внутри и между предложениями/абзацами в отображаемом экстрактивном резюме для документа, иногда даже не соблюдая порядок этих слов во входной последовательности. . Несмотря на то, что упорядочивание релевантности документа часто в значительной степени смягчает это, нам все еще остается задача изучения извлечения резюме каждого документа, часто приходится переходить в документ только для того, чтобы снова вернуться к основному набору результатов, потому что документ не t удовлетворить наше намерение поиска.
Подход к поиску документов, описанный в этой статье, может уменьшить эту когнитивную перегрузку, присутствующую в поисковых системах, в дополнение к получению более релевантных результатов, особенно при поиске фрагментов предложений. В качестве иллюстрации тот же запрос, который мы использовали в существующих поисковых системах выше, может давать результаты в форме, показанной ниже 9.0009 (интерфейс представляет собой схему, предназначенную исключительно для демонстрации подхода к поиску). Ключевым моментом, который следует отметить на приведенной ниже схеме, является то, что фасеты извлечения сводки являются фактическими совпадениями в документах (числа в скобках — это количество документов, содержащих фрагмент, и косинусное расстояние фрагмента с входным фрагментом поиска) , в отличие от предлагаемых запросов или связанных поисковых запросов, отображаемых в традиционных поисковых системах. Эти сводные фасеты дают панорамный обзор области результатов, сокращая бесполезную навигацию по документу и ускоряя сходимость к интересующим документам.
Эти сводные фасеты дают панорамный обзор области результатов, сокращая бесполезную навигацию по документу и ускоряя сходимость к интересующим документам.
Фрагменты ввода могут быть полными или частичными предложениями без ограничений по составу или стилю. Например, они могут быть вопросительными, в отличие от утвердительного запроса выше — мы можем найти белковые рецепторы, с которыми связывается коронавирус, выполнив поиск « рецепторов, с которыми коронавирус связывается »
Рисунок 4. Другой пример схема поиска фрагментов. Входными данными может быть любая последовательность слов, которая представляет собой полное или частичное предложение и может иметь любую природу (утвердительные, вопросительные и т. д.) Сравнение между поисковыми системами, приведенное выше, предназначено только для иллюстрации различий в подходах, лежащих в основе обнаружения документов. В противном случае это было бы несправедливым сравнением, учитывая разницу в размерах корпусов на порядки — мы обязательно получим более релевантные результаты в крошечном корпусе.
В противном случае это было бы несправедливым сравнением, учитывая разницу в размерах корпусов на порядки — мы обязательно получим более релевантные результаты в крошечном корпусе.
Распределенные представления стали неотъемлемой частью любой формы поиска благодаря их преимуществам по сравнению с традиционными чисто символическими подходами к поиску. Современные поисковые системы все чаще используют свои свойства для дополнения методов символьного поиска. Если мы рассматриваем поиск документов в широком смысле как комбинацию обхода пространства документа в ширину и в глубину, эти две формы обхода требуют вложений, которые имеют характеристики, характерные для этих обходов. Например, мы можем начать с поиска животных, вызывающих коронавирус, затем перейти к летучим мышам, а затем снова перейти к рептилиям и т. д.
Распределенные представления аспектов документа — будь то слова, фразы или фрагменты предложений, извлеченные из пространства вложений Word2vec и BERT, имеют уникальные и дополнительные атрибуты, которые полезны для выполнения широкого и глубокого поиска. В частности,
В частности,
- вложения Word2vec для терминов ( терминов относятся к словам и фразам — например, летучие мыши, циветты) эффективны для поиска в ширину с применением кластеризации на основе объектов к результатам. Результаты поиска по одному слову « летучих мышей» или фраза « циветт» даст других животных, таких как панголины, верблюды и т. д.
- Вложения BERT для фрагментов предложений (« коронавирус у панголинов» , « летучие мыши как источник коронавируса» и т. д. ) полезны для поиска вариантов фрагментов, которые в значительной степени сохраняют исходные существительные в зависимости от их присутствия в корпусе. Например, «летучие мыши как источник коронавируса» дадут варианты фрагментов, такие как «летучие мыши являются переносчиком коронавируса» 9.0010 , «коронавирусы, возникающие у летучих мышей» и т. д.
- Хотя эти вложения в значительной степени дополняют друг друга, они также имеют перекрывающиеся свойства — вложения word2vec могут давать первые результаты в глубину, а вложения BERT дают первые результаты в ширину в хвосте распределения статистически значимых результатов. Например, поиск летучих мышей с использованием встраивания word2vec также даст вид летучих мышей (например, летучие мыши, красавки, летучие лисицы, крыланы) в дополнение к другим животным, таким как верблюды, панголины и т. д. Фрагментный поиск «коронавирус у павлина» с использованием BERT дает «коронавирусная болезнь кошек», «коронавирус у гепардов» , несмотря на то, что результаты показывают преимущественно коронавирус у птиц.
- Модель BERT позволяет ввести поисковый запрос (термины или фрагменты) вне словарного запаса, что позволяет любому пользователю, вводящему кандидата, найти соответствующие документы.
 Например, поиск летучих мышей с использованием встраивания word2vec также даст вид летучих мышей (например, летучие мыши, красавки, летучие лисицы, крыланы) в дополнение к другим животным, таким как верблюды, панголины и т. д. Фрагментный поиск «коронавирус у павлина» с использованием BERT дает «коронавирусная болезнь кошек», «коронавирус у гепардов» , несмотря на то, что результаты показывают преимущественно коронавирус у птиц.
Например, поиск летучих мышей с использованием встраивания word2vec также даст вид летучих мышей (например, летучие мыши, красавки, летучие лисицы, крыланы) в дополнение к другим животным, таким как верблюды, панголины и т. д. Фрагментный поиск «коронавирус у павлина» с использованием BERT дает «коронавирусная болезнь кошек», «коронавирус у гепардов» , несмотря на то, что результаты показывают преимущественно коронавирус у птиц. Расширенные термины/фрагменты, полученные из вложений word2vec/BERT для пользовательского ввода, используются для точного сопоставления документов, которые уже были проиндексированы в автономном режиме с использованием этих терминов/фрагментов. В автономном режиме фрагменты извлекаются из корпуса с помощью комбинации тегировщика частей речи и чанкера, и для них создаются вложения с использованием обеих моделей, word2vec и BERT.
В автономном режиме фрагменты извлекаются из корпуса с помощью комбинации тегировщика частей речи и чанкера, и для них создаются вложения с использованием обеих моделей, word2vec и BERT.
- Промежуточный этап сопоставления введенных пользователем данных с вложениями терминов и фрагментов, которые затем служат для поиска документов, не только имеет то преимущество, что увеличивает широту и глубину поиска, но также позволяет обойти проблему создания качественных вложений документов, соответствующих пользователю. вход. В частности, фрагменты играют двойную роль указателей для документа, а также позволяют одному документу иметь несколько доступных для поиска «извлекаемых подрезюме», характеризующихся встроенными в него фрагментами. Фрагменты также увеличивают шансы найти документ «иголка в стоге сена» (отдельный документ в корпусе, содержащий ответ на вопрос) по сравнению с поиском такого документа исключительно с использованием терминов или фраз. Поиск потенциальных животных-источников коронавируса является очевидным вариантом использования для поиска документа «иголка в стоге сена» — мы можем видеть на рисунках 3 и 4 выше совпадения фрагментов с отдельными документами (это подробно рассматривается в разделе примечаний ниже) .
- Использование вложений исключительно на промежуточном этапе поиска кандидатов терминов/фрагментов и использование традиционных методов индексации поиска для поиска документов, соответствующих этим терминам/фрагментам, позволяет нам выполнять поиск документов в масштабе.
- Наконец, при поиске ответов на общие вопросы, такие как « Какие животные источники COVID-19 ? » выполняется автоматически и в автономном режиме, учитывая большой объем и время обработки для такой задачи, описанный здесь подход к поиску на основе встраивания фрагментов применим для «не столь широких» случаев использования живого поиска, таких как вопрос « рецепторов, с которыми коронавирус связывается». ” при наличии достаточных вычислительных ресурсов и эффективных подходов к хэшированию для выполнения поиска в пространстве в масштабе.

Как упоминалось ранее, вложения word2vec расширяют возможности поиска слов и фраз. Они не расширяют широту поиска фрагментов — у гистограммы окрестности довольно часто отсутствует отчетливый хвост (рисунок 8 ниже) . Это связано с тем, что фрагменты из-за их длины не имеют достаточного соседнего контекста для изучения качественных вложений. Этот недостаток может быть частично устранен путем увеличения размера окна обучения и увеличения окружающего контекста за счет игнорирования границ предложений, но на практике этого все еще недостаточно, учитывая низкое количество встречаемости фрагментов 9.0009 (рисунок 8) .
Они не расширяют широту поиска фрагментов — у гистограммы окрестности довольно часто отсутствует отчетливый хвост (рисунок 8 ниже) . Это связано с тем, что фрагменты из-за их длины не имеют достаточного соседнего контекста для изучения качественных вложений. Этот недостаток может быть частично устранен путем увеличения размера окна обучения и увеличения окружающего контекста за счет игнорирования границ предложений, но на практике этого все еще недостаточно, учитывая низкое количество встречаемости фрагментов 9.0009 (рисунок 8) .
Вложения BERT в основном только увеличивают глубину поиска, особенно для фрагментов и фраз (расширение глубины поиска для слов с использованием вложений BERT на практике бесполезно) . Хотя они в некоторой степени увеличивают широту охвата, например, запрос «коронавирус у макак» расширяется, чтобы включить «коронавирус у пальмовых циветт» в хвост распределения важных результатов, широта не так велика, как то, что предлагает word2vec по глубине для слов. и фраза. Подпись к Рисунку 6 ниже показывает, где он несовершенен. В примечаниях к реализации есть дополнительные примеры недостаточной широты поиска фрагментов и способы обойти это ограничение.
и фраза. Подпись к Рисунку 6 ниже показывает, где он несовершенен. В примечаниях к реализации есть дополнительные примеры недостаточной широты поиска фрагментов и способы обойти это ограничение.
 Однако поиск «коронавируса у павлинов» в целом начнется с коронавируса у птиц и будет иметь расширенные результаты, такие как «коронавирус у гепарда». На практике это может восприниматься как преимущество, а не как недостаток, особенно когда пользователь вводит фрагмент, чтобы найти конкретные ответы. Однако этого недостаточно, когда пользователь вводит фрагмент для широкого поиска, такого как «животные с коронавирусом». Однако такой вопрос нельзя решить с помощью одного поиска — это по своей сути многоэтапный процесс, как показано на рис. 1.9.0006 Word2vec был, возможно, первой моделью, которая ясно показала возможности распределенных представлений около семи лет назад. Вложения, выдаваемые этой простой моделью с двумя массивами векторов для ее «архитектуры», по-прежнему имеют огромное значение для последующих приложений, таких как метод поиска документов, описанный выше.
Однако поиск «коронавируса у павлинов» в целом начнется с коронавируса у птиц и будет иметь расширенные результаты, такие как «коронавирус у гепарда». На практике это может восприниматься как преимущество, а не как недостаток, особенно когда пользователь вводит фрагмент, чтобы найти конкретные ответы. Однако этого недостаточно, когда пользователь вводит фрагмент для широкого поиска, такого как «животные с коронавирусом». Однако такой вопрос нельзя решить с помощью одного поиска — это по своей сути многоэтапный процесс, как показано на рис. 1.9.0006 Word2vec был, возможно, первой моделью, которая ясно показала возможности распределенных представлений около семи лет назад. Вложения, выдаваемые этой простой моделью с двумя массивами векторов для ее «архитектуры», по-прежнему имеют огромное значение для последующих приложений, таких как метод поиска документов, описанный выше. Word2vec в сочетании с встраиваниями BERT предлагает решение для поиска документов, которое потенциально улучшает традиционные подходы с точки зрения качества результатов и времени их сходимости (это требование должно быть определено количественно) .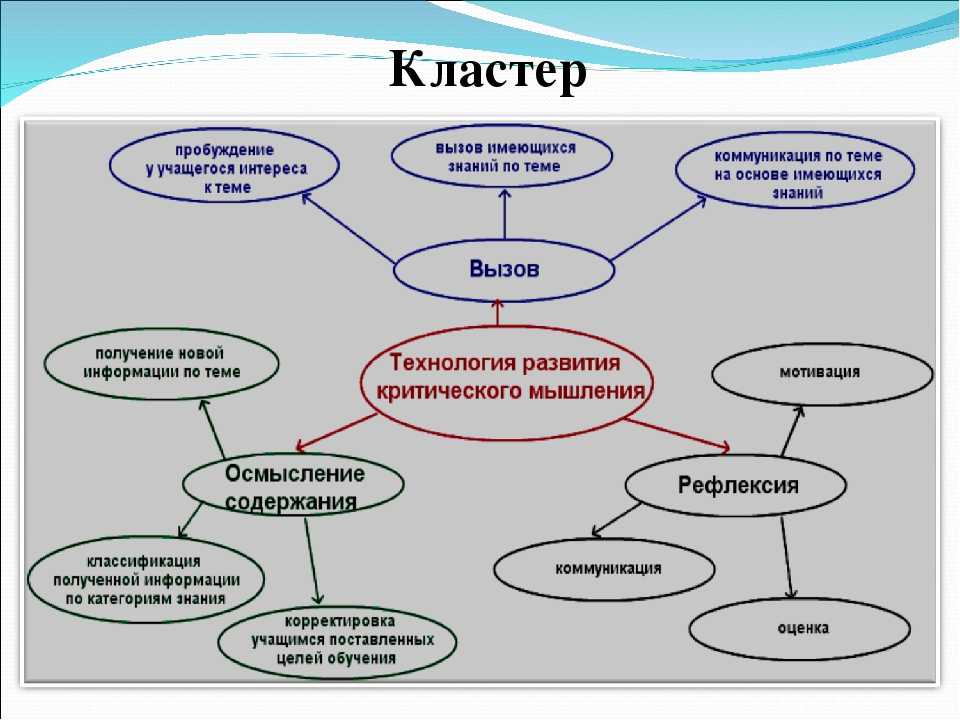 Решение позволяет обойти проблему изучения всех важных аспектов документа в едином векторном представлении, которое затем может использоваться поисковой системой не только для выбора конкретного документа, но и для поиска документов, похожих на выбранный.
Решение позволяет обойти проблему изучения всех важных аспектов документа в едином векторном представлении, которое затем может использоваться поисковой системой не только для выбора конкретного документа, но и для поиска документов, похожих на выбранный.
Обход возможен за счет использования вложений, будь то слово, фраза или фрагмент предложения, для расширения/углубления поиска до выбора документа. Вложения Word2vec для слов и фраз значительно увеличивают широту поиска документов. Вложения BERT для фрагментов предложений значительно увеличивают глубину поиска. Встраивания BERT также устраняют сценарий отсутствия словарного запаса, а также облегчают извлекаемое обобщение различных существенных аспектов документа с возможностью поиска, что ускоряет сходимость к соответствующим документам.
- Животный источник COVID-19 на сегодняшний день не подтвержден.
- Предложение BERT
- NER без учителя с использованием BERT
- Ответ, объясняющий, как работает word2vec
1. Какие методы/модели НЛП используются в этом подходе?
Какие методы/модели НЛП используются в этом подходе?
Теггер части речи для маркировки предложения (масштабируемый на основе CRF, который как минимум на порядок быстрее по сравнению с более поздними моделями с современными оценками F1. Однако отзыв этой модели адекватен для этой задачи тегирования),
чанкер для создания фраз,
Word2vec для встраивания слов и фраз,
BERT для 900 10 встраивания фрагментов (преобразователи предложений) и
BERT для неконтролируемые тегирование сущностей
2. Как вычисляется релевантность результатов документа?
Порядок фрагментов основан на косинусном расстоянии от входного фрагмента. Первый документ из набора документов, соответствующих каждому фрагменту фасета, выбирается и перечисляется в том же порядке, что и порядок входных фрагментов. Порядок документов может быть основан на некотором другом порядке релевантности документов. Выбор документа из каждого набора совпадений фрагментов также может быть основан на каком-либо другом порядке релевантности.
Выбор документа из каждого набора совпадений фрагментов также может быть основан на каком-либо другом порядке релевантности.
3. Будет ли этот поиск масштабироваться для поиска в реальном времени?
Шагом, требующим больших вычислительных ресурсов, в поиске в реальном времени является поиск сходства в пространстве вложений (Word2vec или BERT). Существуют существующие решения с открытым исходным кодом для выполнения этой операции в масштабе. Есть оптимизации, которые мы можем сделать, чтобы сократить время/вычислительные циклы, такие как поиск только в одном из двух пространств вложений на основе входной длины поиска, учитывая, что сильные/слабые стороны этих моделей зависят от этого.
4. Разве фрагмент не есть не что иное, как длинная фраза? Если да, то почему называть его по-другому?
Фрагмент представляет собой длинную фразу. Различие с фразами полезно по двум причинам:
а) фрагментами могут быть полные предложения, а не только части предложений
б) сильные стороны этих моделей зависят от длины входных данных, как мы видели ранее (см. рис. 6). ).Word2vec хорошо работает в области терминов/коротких фраз. BERT лучше всего работает в области фрагментов (≥ 5 слов)
рис. 6). ).Word2vec хорошо работает в области терминов/коротких фраз. BERT лучше всего работает в области фрагментов (≥ 5 слов)
5. Как выглядят гистограммы распределения окрестностей для терминов и фрагментов?
Окрестности BERT и Word2vec ниже для слова, фразы (3 слова) и фрагментов (8 слов) иллюстрируют взаимодополняющий характер этих двух моделей. Хвост распределения увеличивается по мере увеличения длины слова для BERT — фрагменты имеют отчетливый хвост по сравнению с фразами или словами. Когда количество терминов мало, иногда у распределения могут быть очень толстые хвосты — это свидетельствует о плохих результатах. Вложения, созданные преобразователи предложений , как правило, имеют отчетливый хвост, в отличие от вложений bert-as-service , несмотря на то, что оба используют суммирование подслов в качестве объединения (оба также имеют другие подходы к объединению) из-за контролируемого этапа обучения в предложении -трансформеры, использующие пары предложений с ярлыками следствия, нейтральности и противоречия.
Окрестности Word2vec имеют хвост для слов и фраз. Распределение почти переходит в «патологическую форму» для длинных фраз даже с большим количеством вхождений, со скученностью в верхнем конце, а затем остальная масса концентрируется в нижнем конце. Форма распределения различается и для длинных фраз. Однако, независимо от формы, результаты соседства ясно показывают это ухудшение качества.
Рисунок 7. Окрестность BERT показывает отчетливый хвост по мере увеличения количества слов во входных данных. Когда количество терминов мало, иногда у распределения могут быть очень толстые хвосты — это указывает на плохие результаты. Рисунок 8. Окрестности Word2vec демонстрируют поведение, противоположное BERT. На самом деле распределение принимает «патологический поворот» с концентрацией терминов в верхней части (некоторые со значением 1), а затем остальная масса концентрируется в нижней части. Эта разбивка происходит независимо от количества вхождений фрагмента в корпус, хотя форма может немного различаться. Постоянное наблюдение за фрагментами заключается в том, что качество соседей падает — соседи кажутся почти шумом. Возможно, это связано с тем, что длинные фразы не имеют достаточного контекста для обучения.
Постоянное наблюдение за фрагментами заключается в том, что качество соседей падает — соседи кажутся почти шумом. Возможно, это связано с тем, что длинные фразы не имеют достаточного контекста для обучения.6. Чувствительность результатов к изменениям входного фрагмента. Вот насколько вероятно, что мы сойдемся на одном и том же результате, используя варианты входных данных.
Хотя набор фрагментов, извлеченных для разных вариантов одного и того же вопроса, различен, в полученном наборе фрагментов, по-видимому, много пересечений. Однако некоторые вопросы могут не дать ни одного фрагмента, включающего все искомые существительные, из-за ограниченности охвата фрагментов, обсуждавшегося ранее. Например, «птеропус как источник коронавируса» или «коронавирус в птеропусах» могут не содержать фрагментов, содержащих птеропусов или летучих мышей (птеропус принадлежит к семейству летучих мышей). Когда фрагменты не содержат все существительные, можно рассмотреть один из подходов — найти соседей Word2vec для этого термина и реконструировать запрос, используя эти термины.
7. Как можно сравнить модели поиска иголки в стоге сена с использованием терминов, фраз и фрагментов?
Вложения Word2vec напрямую не полезны для этого случая просто потому, что вектор для единичного термина/фразы не имеет достаточного контекста для изучения расширенного представления. Вложения BERT не страдают от этого недостатка по самой природе построения даже слова из подслов — подслова имеют достаточный контекст для изучения хороших представлений. Тем не менее, Word2vec может по-прежнему играть роль, чтобы найти эквивалентное имя для существительного в поиске, который затем дает документ «иголка в стоге сена». Например, если в пространстве документа есть единственная ссылка на коронавирус у фруктовых летучих мышей, поиск коронавируса у крылатых может не дать этот документ. Однако поиск фрагмента коронавируса во фруктовых летучих мышах (созданном с помощью Word2vec) позволит найти этот единственный документ в пространстве для встраивания BERT. В дополнение к наличию фрагмента, находящегося в хвосте распределения (если он действительно есть), квалифицирующего его как кандидата, интерпретируемость, присущая большинству фрагментов, дает преимущество, которое не обязательно может иметь слово или фраза.
В дополнение к наличию фрагмента, находящегося в хвосте распределения (если он действительно есть), квалифицирующего его как кандидата, интерпретируемость, присущая большинству фрагментов, дает преимущество, которое не обязательно может иметь слово или фраза.
8. Дополнительные сведения об извлечении информации о коронавирусе у животных
Около 1000 (998) упоминаний биологических объектов были собраны с использованием Word2vec и тегов объектов. С их помощью было собрано 195 фрагментов с упоминанием вируса. Показана выборка из 30 фрагментов
Образец фрагментов с признаками животных-потенциальных источников коронавируса
9. Нужны ли обе формы вложений для поиска фрагментов?
Нам достаточно одного — вложений BERT. Однако нам нужно минимально связать его с традиционной системой лексического поиска, чтобы дополнить ее в области, где она слаба — поиск по одному термину и короткой фразе.
В приведенном ниже блок-схеме показан вариант использования обеих таких систем, используемых вместе для обнаружения документов.
На рисунках ниже показаны примеры обнаружения документов с использованием обоих показанных выше потоков.
Схема примера потока поиска документа с длинным фрагментом в поисковой системе с BERT и традиционным лексическим поиском — два шага до обнаружения Схема примера потока поиска документа с использованием одного слова с BERT и традиционным лексическим поиском. (1) Косинусные соседи в пространстве BERT бесполезны для отдельных слов. (2) Однако сопоставление пользовательского ввода с фрагментами помогает обнаружить соответствующие фрагменты. Выбор косинусных соседних ссылок соответствующего фрагмента помогает обнаружить больше интересующих фрагментов, один из которых (3) может дать искомый документ.
(1) Косинусные соседи в пространстве BERT бесполезны для отдельных слов. (2) Однако сопоставление пользовательского ввода с фрагментами помогает обнаружить соответствующие фрагменты. Выбор косинусных соседних ссылок соответствующего фрагмента помогает обнаружить больше интересующих фрагментов, один из которых (3) может дать искомый документ.Эта статья была импортирована вручную из Quora
Вариации — создание содержимого фрагментов
Вариации — важная особенность фрагментов содержимого AEM, поскольку они позволяют создавать и редактировать копии основного содержимого для использования на определенных каналах, и/или сценарии, что делает создание страниц и автономную доставку контента еще более гибкими.
На вкладке Варианты вы можете:
- Ввести содержимое вашего фрагмента,
- Создание и управление вариантами контента Master ,
Выполнение ряда других действий в зависимости от редактируемого типа данных; например:
Вставьте визуальные активы в ваш фрагмент (изображения)
Выбор между Rich Text, Plain Text и Markdown для редактирования
Загрузить контент
Просмотр ключевой статистики (о многострочном тексте)
Обобщить текст
Синхронизировать варианты с основным содержимым
ОСТОРОЖНО
После публикации фрагмента и/или ссылки на него AEM будет отображать предупреждение, когда автор снова открывает фрагмент для редактирования. Это сделано для того, чтобы предупредить, что изменения во фрагменте также повлияют на страницы, на которые ссылаются.
Это сделано для того, чтобы предупредить, что изменения во фрагменте также повлияют на страницы, на которые ссылаются.
Создание контента
Когда вы открываете фрагмент контента для редактирования, вкладка Варианты будет открыта по умолчанию. Здесь вы можете создать контент для Мастера или любых других вариантов, которые у вас есть. Структурированный фрагмент содержит различные поля с различными типами данных, которые были определены в модели контента.
Например:
Вы можете:
вносить изменения непосредственно на вкладке Variations
- каждый тип данных предоставляет различные возможности редактирования
для Многострочный текст поля вы также можете открыть полноэкранный редактор для:
- выберите Формат
- просмотреть дополнительные параметры редактирования (для формата Rich Text)
- доступ к ряду действий
Для полей Ссылка на фрагмент параметр Редактировать фрагмент содержимого может быть доступен в зависимости от определения модели.

Полноэкранный редактор
При редактировании многострочного текстового поля вы можете открыть полноэкранный редактор; коснитесь или щелкните внутри фактического текста, затем выберите следующий значок действия:
Откроется полноэкранный текстовый редактор:
Полноэкранный текстовый редактор предоставляет:
- Доступ к различным действиям
- В зависимости от формата дополнительные параметры форматирования (Rich Text)
Действия
Следующие действия также доступны (для всех форматов), когда открыт полноэкранный редактор (т.е. многострочный текст):
Выберите формат (Rich Text, Plain Text, Markdown)
Загрузить контент
Показать текстовую статистику
Синхронизировать с Мастером (при редактировании варианта)
Обобщить текст
Форматы
Варианты редактирования многострочного текста зависят от выбранного формата:
- Rich Text
- Обычный текст
- Уценка
Формат можно выбрать при полноэкранном редакторе.
Форматированный текст
Редактирование форматированного текста позволяет форматировать:
- Жирный
- Курсив
- Подчеркнуть
- Выравнивание: слева, по центру, справа
- Маркированный список
- Нумерованный список
- Отступ: увеличение, уменьшение
- Создание/разрыв гиперссылок
- Вставить текст/из Word
- Вставить стол
- Стиль абзаца: Абзац, заголовок 1/2/3
- Вставить актив
- Откройте полноэкранный редактор, в котором доступны следующие параметры форматирования:
- Поиск
- Найти/Заменить
- Проверка орфографии
- Аннотации
- Вставить фрагмент содержимого; доступно, если в поле Многострочный текст настроен параметр Разрешить ссылку на фрагмент .
Действия также доступны из полноэкранного редактора.
Обычный текст
Обычный текст позволяет быстро вводить содержимое без информации о форматировании или уценке. Вы также можете открыть полноэкранный редактор для дальнейших действий.
Вы также можете открыть полноэкранный редактор для дальнейших действий.
ВНИМАНИЕ
Если вы выберете Обычный текст , вы можете потерять все форматирование, уценку и/или активы, которые вы вставили в Форматированный текст или Уценка .
Уценка
ПРИМЕЧАНИЕ
Полную информацию см. в документации по уценке.
Позволяет форматировать текст с помощью уценки. Вы можете определить:
- Заголовки
- Абзацы и разрывы строк
- Ссылки
- Изображения
- Блочные котировки
- Списки
- Акцент
- Кодовые блоки
- Экранирование обратной косой черты
Вы также можете открыть полноэкранный редактор для дальнейших действий.
ПРЕДОСТЕРЕЖЕНИЕ
При переключении между Rich Text и Markdown вы можете столкнуться с неожиданными эффектами при использовании блочных кавычек и блоков кода, поскольку эти два формата могут по-разному обрабатываться.
Ссылки на фрагменты
Если модель фрагмента содержимого содержит ссылки на фрагменты, у авторов фрагментов могут быть дополнительные параметры:
- Редактировать фрагмент содержимого
- Фрагмент нового контента
Редактировать фрагмент содержимого
Параметр Редактировать фрагмент содержимого откроет этот фрагмент в новой вкладке редактора (на той же вкладке браузера).
Повторный выбор исходной вкладки (например, Little Pony Inc. ) закроет эту дополнительную вкладку (в данном случае Adam Smith ).
Новый фрагмент содержимого
Опция Новый фрагмент содержимого позволит вам создать совершенно новый фрагмент. Для этого в редакторе откроется вариант мастера создания фрагмента контента.
После этого вы сможете создать новый фрагмент:
- Перейдя и выбрав нужную папку.
- Выбор Далее .
- Задание свойств; например Название .
- Выбор Создать .
- Наконец:
- Готово вернет (к исходному фрагменту) и сошлется на новый фрагмент.
- Открыть будет ссылаться на новый фрагмент, а также открывать новый фрагмент для редактирования в новой вкладке браузера.

Просмотр ключевой статистики
Когда полноэкранный редактор открыт, действие Текстовая статистика отображает ряд сведений о тексте.
Например:
Загрузка контента
Для облегчения процесса создания фрагментов контента вы можете загрузить текст, подготовленный во внешнем редакторе, и добавить его непосредственно во фрагмент.
Обобщающий текст
Обобщающий текст помогает пользователям сократить длину текста до заданного количества слов, сохраняя при этом ключевые моменты и общий смысл.
ПРИМЕЧАНИЕ
На более техническом уровне система сохраняет предложения, которые она оценивает как обеспечивающие наилучшее соотношение плотности информации и уникальности в соответствии с конкретными алгоритмами.
ПРЕДОСТЕРЕЖЕНИЕ
Фрагмент содержимого должен иметь допустимую языковую папку (код ISO) в качестве предка; это используется для определения используемой языковой модели.
Например, en/ по следующему пути:
/content/dam/my-brand/en/path-down/my-content-fragment
ПРЕДОСТЕРЕЖЕНИЕ
Английский доступен в стандартной комплектации.
Другие языки доступны в качестве пакетов языковой модели из раздела распространения программного обеспечения:
- Французский (fr)
- Немецкий (де)
- итальянский (it)
- Испанский (исп)
Выберите Master или требуемый вариант.
Открыть полноэкранный редактор.
Выберите Суммировать текст на панели инструментов.
Укажите целевое количество слов и выберите Start :
Исходный текст отображается рядом с предложенным обобщением:
- Предложения, подлежащие исключению, выделены красным цветом и перечеркнуты.
- Нажмите на любое выделенное предложение, чтобы сохранить его в итоговом содержании.
- Нажмите на любое невыделенное предложение, чтобы удалить его.
Выберите Суммировать , чтобы подтвердить изменения.
Исходный текст отображается рядом с предложенным обобщением:
- Предложения, подлежащие исключению, выделены красным цветом и перечеркнуты.
- Нажмите на любое выделенное предложение, чтобы сохранить его в итоговом содержании.
- Нажмите на любое невыделенное предложение, чтобы удалить его.
- Показана сводная статистика: Фактический и Цель —
- Вы можете Предварительно просмотреть изменения.


Аннотирование фрагмента содержимого
Чтобы аннотировать фрагмент:
Выберите Master или требуемый вариант.
Открыть полноэкранный редактор.
Значок Annotate доступен на верхней панели инструментов. При необходимости можно выделить текст.
Откроется диалоговое окно. Здесь вы можете ввести свою аннотацию.
Выберите Применить в диалоговом окне.
Если аннотация была применена к выделенному тексту, этот текст останется выделенным.
Закрыть полноэкранный редактор, аннотации по-прежнему выделены. Если выбрано, откроется диалоговое окно, в котором вы сможете продолжить редактирование аннотации.
Выбрать Сохранить .
Закрыть полноэкранный редактор, аннотации по-прежнему выделены.
Если выбрано, откроется диалоговое окно, в котором вы сможете продолжить редактирование аннотации.
 Если выбрано, откроется диалоговое окно, в котором вы сможете продолжить редактирование аннотации.
Если выбрано, откроется диалоговое окно, в котором вы сможете продолжить редактирование аннотации.Просмотр, редактирование, удаление аннотаций
Аннотации:
Обозначаются выделением текста, как в полноэкранном, так и в обычном режиме редактора. После этого можно просмотреть, отредактировать и/или удалить полные сведения об аннотации, щелкнув выделенный текст, что приведет к повторному открытию диалогового окна.
ПРИМЕЧАНИЕ
Выпадающий селектор предоставляется, если к одному фрагменту текста было применено несколько аннотаций.
При удалении всего текста, к которому была применена аннотация, аннотация также удаляется.
Можно добавить в список и удалить, выбрав вкладку Annotations в редакторе фрагментов.
Можно просматривать и удалять выбранный фрагмент на временной шкале.
Вставка ассетов во фрагмент
Чтобы упростить процесс создания фрагментов контента, вы можете добавлять ассеты (изображения) непосредственно во фрагмент.
Будут добавлены в последовательность абзацев фрагмента без форматирования; форматирование может быть выполнено, когда фрагмент используется/ссылается на страницу.
ОСТОРОЖНО
Эти активы нельзя перемещать или удалять на странице ссылки, это необходимо сделать в редакторе фрагментов.
Однако форматирование актива (например, размер) должно выполняться в редакторе страниц. Представление актива в редакторе фрагментов предназначено исключительно для создания потока содержимого.
ПРИМЕЧАНИЕ
Существуют различные способы добавления изображений к фрагменту и/или странице.
Поместите курсор в то место, где вы хотите добавить изображение.
Используйте значок Insert Asset , чтобы открыть диалоговое окно поиска.
В диалоговом окне вы можете:
- перейти к нужному активу в DAM
- поиск актива в DAM
После обнаружения выберите нужный актив, щелкнув миниатюру.
Используйте Выберите , чтобы добавить актив в систему абзацев вашего фрагмента контента в текущем местоположении.
ОСТОРОЖНО
Если после добавления актива вы измените формат на:
- Обычный текст : актив будет полностью потерян из фрагмента.
- Markdown : актив не будет виден, но все равно будет там, когда вы вернетесь в Rich Text .

Вставка фрагмента содержимого в ваш фрагмент
Чтобы упростить процесс создания фрагментов содержимого, вы также можете добавить к своему фрагменту еще один фрагмент содержимого.
Они будут добавлены в качестве ссылки в ваше текущее местоположение в вашем фрагменте.
ПРИМЕЧАНИЕ
Этот параметр доступен, если для Многострочный текст настроен параметр Разрешить ссылку на фрагмент .
ОСТОРОЖНО
Эти активы нельзя перемещать или удалять на странице ссылки, это необходимо сделать в редакторе фрагментов.
Однако форматирование актива (например, размер) должно выполняться в редакторе страниц. Представление актива в редакторе фрагментов предназначено исключительно для создания потока содержимого.
ПРИМЕЧАНИЕ
Существуют различные способы добавления изображений к фрагменту и/или странице.
Поместите курсор в то место, где вы хотите добавить фрагмент.
Используйте значок Вставить фрагмент содержимого , чтобы открыть диалоговое окно поиска.
В диалоговом окне вы можете:
- перейти к нужному фрагменту в папке Assets
- поиск фрагмента
Найдя нужный фрагмент, щелкните его миниатюру.
Используйте Выберите , чтобы добавить ссылку на выбранный фрагмент содержимого в текущий фрагмент содержимого (в текущем местоположении).
ОСТОРОЖНО
Если после добавления ссылки на другой фрагмент вы измените формат на:
- Обычный текст : ссылка будет полностью потеряна из фрагмента.
- Markdown : ссылка останется.
- Обычный текст : ссылка будет полностью потеряна из фрагмента.

Управление вариантами
Создание варианта
Варианты позволяют вам взять содержимое Master и изменить его в соответствии с назначением (при необходимости).
Чтобы создать новый вариант:
Откройте свой фрагмент и убедитесь, что боковая панель видна.
Выберите Варианты на панели значков на боковой панели.
Выберите Создать вариант .
Откроется диалоговое окно, укажите Заголовок и Описание для нового варианта.
Выбрать Добавить ; фрагмент Мастер будет скопирован в новую вариацию, которая сейчас открыта для редактирования.
ПРИМЕЧАНИЕ
При создании нового варианта всегда Мастер копируется, а не вариант, открытый в данный момент.

Редактирование варианта
Вы можете внести изменения в содержание варианта после:
- Создание варианта.
- Открытие существующего фрагмента, затем выбор нужного варианта на боковой панели.
Переименование варианта
Чтобы переименовать существующий вариант:
Откройте свой фрагмент и выберите Вариации с боковой панели.
Выберите нужный вариант.
Выберите Переименовать из раскрывающегося списка Действия .
Введите новый заголовок и/или описание в появившемся диалоговом окне.
Подтвердите действие Переименовать .
ПРИМЕЧАНИЕ
Это влияет только на вариант Заголовок .
Удаление варианта
Чтобы удалить существующий вариант:
Откройте свой фрагмент и выберите Variations на боковой панели.
Выберите нужный вариант.
Выберите Удалить из раскрывающегося списка Действия .
Подтвердите действие Удалить в диалоговом окне.

ПРИМЕЧАНИЕ
Вы не можете удалить Master .
Синхронизация с мастером
Мастер является неотъемлемой частью фрагмента контента и по определению содержит мастер-копию контента, тогда как варианты содержат отдельные обновленные и адаптированные версии этого контента. При обновлении Мастера возможно, что эти изменения также относятся к вариациям и, следовательно, должны быть распространены на них…
При редактировании вариации вам доступно действие по синхронизации текущего элемента вариации с Мастером. Это позволяет автоматически копировать изменения, внесенные в Мастер, в требуемую вариацию.
ОСТОРОЖНО
Синхронизация доступна только для копирования изменений из Master в вариант .
Leave A Comment