
UTF-8 vs UTF-16. Несколько советов программистам / Хабр
Введение
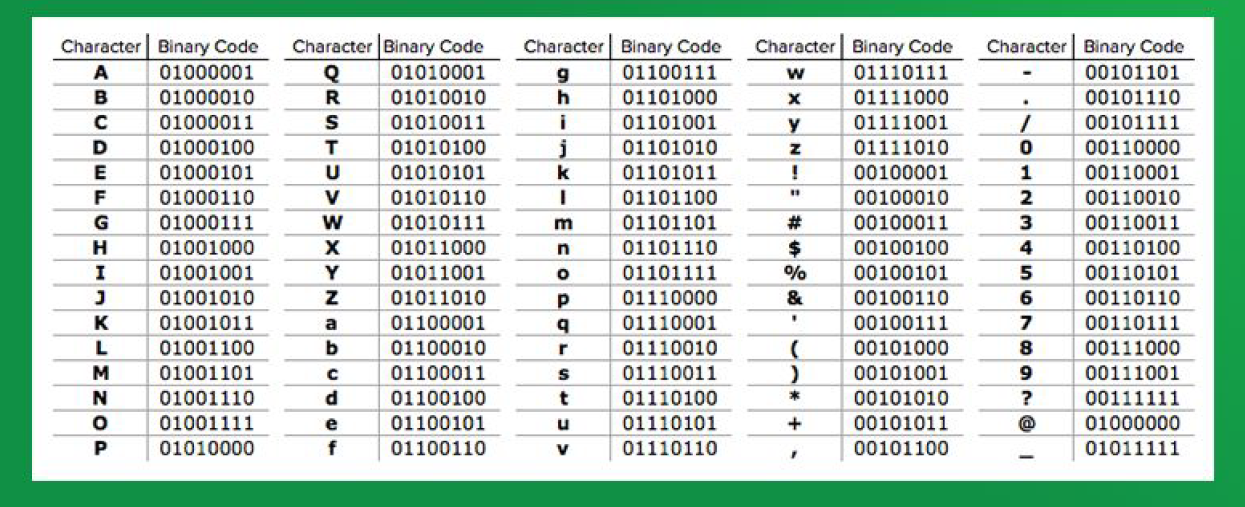
С появлением первых устройств цифровой передачи информации и электронно-вычислительных машин возникла задача кодирования текстовых символов с помощью последовательностей единиц и нулей. Минимальная единица представления информации – байт. Исходя их этого в 1963 году в США разработана, стандартизована, а впоследствии расширена кодовая таблица ASCII (American standard code for information interchange), использовавшая 8 битную кодировку. В первую очередь с помощью этой таблицы предполагалось кодирование цифр и букв английского языка. Первые 128 символов таблицы представлены на рис.1:
Рис.1. Первые 128 символов таблицы ASCII.Номер ячейки в таблице (рис.1) является кодом символа. В качестве примера рассмотрим кодирование слова Hello. Номера ячеек таблицы ASCII, в которых размещены буквы: 72 (H), 101 (e), 108 (l), 111 (o). Код слова в бинарном представлении выглядит следующим образом:
00010010 (H) 10100110 (e) 00110110 (l) 00110110 (l) 11110110 (o) (старший бит справа).
Выделенные подчеркиванием и жирным коды в двоичном представлении соответствуют номерам ячеек в таблице (рис.1). Алгоритм формирования кода следующий:
1. Выделены жирным – биты управления кодированием (префикс). 010 – кодируется заглавная буква алфавита, 011 – строчная.
2. Выделены подчеркиванием – порядковые номера букв в английском алфавите.
Таким образом, с помощью первых 128 ячеек таблицы ASCII могли быть закодированы основные символы, цифры и буквы английского языка. Остальные 128 ячеек (8 битная кодировка позволяет закодировать 256 символов) могли использоваться для кодирования других языков. Однако, учитывая разнообразие символов и языков, 8 бит недостаточно.
Стандарт Юникод
Консорциум Unicode (Юникод) – некоммерческая организация, главной задачей которой являлась разработка стандарта кодирования (стандарт Юникод) с поддержкой наибольшего числа языков и символов служебного характера. Принцип кодирования на основе таблицы сохранился, а таблица (таблица Юникод) была значительно расширена.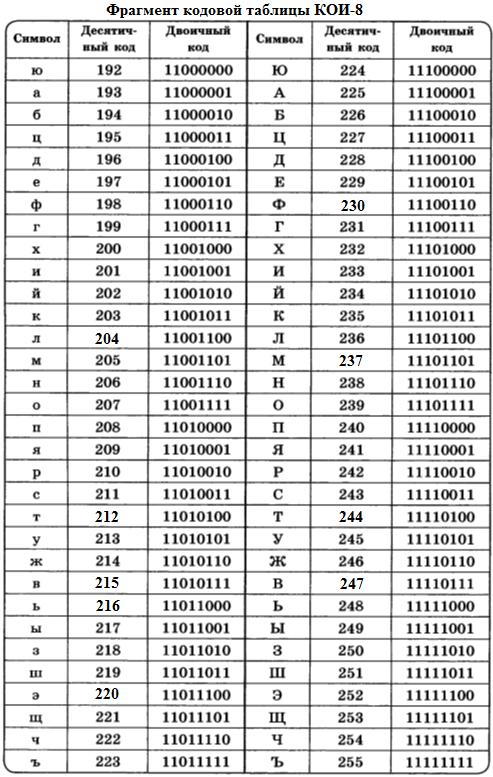
Стандарт Юникод предоставляет пользователям таблицу Юникод и способы кодирования символов.
Символы таблицы Юникод являются элементами «универсального набора символов» UCS (Universal Coded Character Set), определенного международным стандартом ISO/IEC 10646. Таблица Юникод каждому символу UCS сопоставляет кодовую точку, которая является номером ячейки таблицы, содержащей символ.
Способы кодирования символов таблицы Юникод, т.е. преобразования номеров ячеек таблицы Юникод в бинарные коды, составляют кодовое пространство, состоящее из трех кодов семейства UTF (Unicode Transformation Format): UTF-8, UTF-16 и UTF-32
UTF-8 – стандарт кодирования, преобразующий номера ячеек таблицы Юникод в бинарные коды с использованием переменного количества бит: 8, 16, 24 или 32.
UTF-16 – стандарт кодирования, преобразующий номера ячеек таблицы Юникод в бинарные коды с использованием переменного количества бит:16 или 32.
Коды UTF-8 и UTF-16 используют разные алгоритмы кодирования набора символов UCS.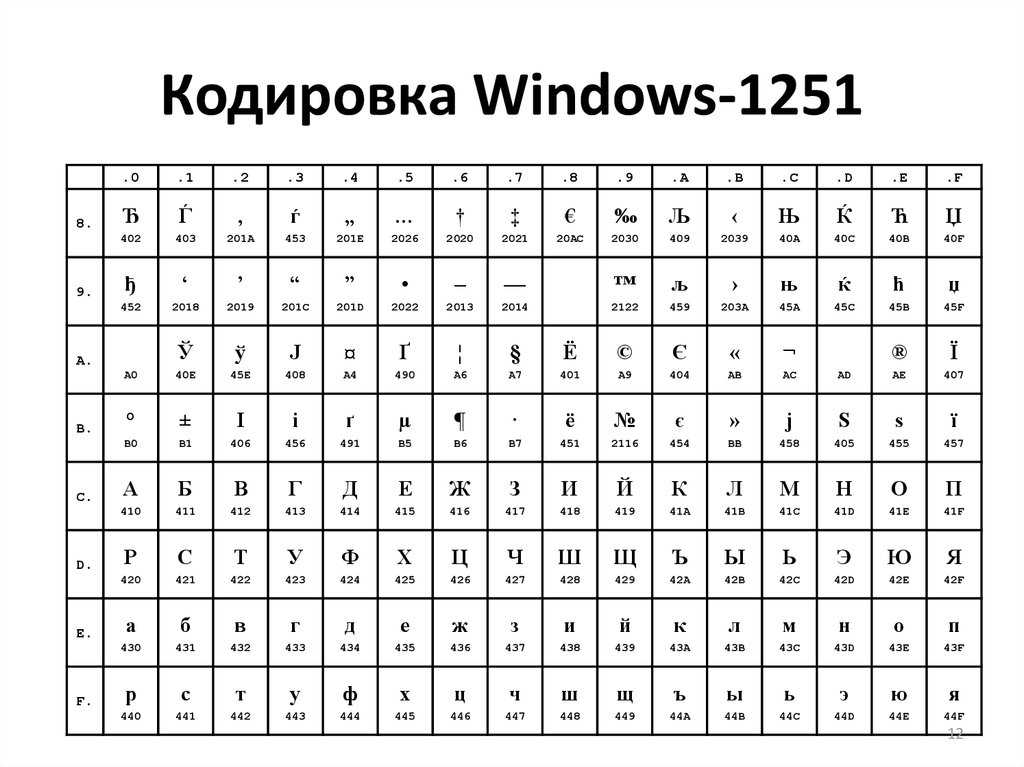
Стандарт кодирования UTF-8
Стандарт закреплен в RFC (Request For Comments) 3629. Алгоритм кодирования согласно RFC:
0xxxxxxx
110xxxxx 10xxxxxx
1110xxxx 10xxxxxx 10xxxxxx
11110xx 10xxxxxx 10xxxxxx 10xxxxxx
Старший бит слева. Началом кода является управляющий символ (выделен жирным):
0 – используется 8-битная кодировка,
110 – используется 16-битная кодировка,
1110 – используется 24-битная кодировка,
11110 – используется 32 битная кодировка.
В начале каждого последующего байта – биты 10 – управляющий символ (выделен подчеркиванием), означающий продолжение кодирования.
Первые 128 ячеек таблицы Юникод повторяют таблицу ASCII. Для кодирования заглавных и строчных букв русского алфавита используются ячейки с номерами 1040-1103.
Рассмотрим пример кодирования фразы «Папа Hello».
Код в бинарном виде (старший бит справа):
00001011 11111001 (П) 00001011 00001101 (а) 00001011 11111101 (п) 00001011 00001101 (а) 00000100 (пробел) 00010010 (H) 10100110 (e) 00110110 (l) 00110110 (l) 11110110 (o).
Букве П русского алфавита согласно таблицы Юникод соответствует номер 1055, в бинарном представлении 10000011111 – 11 бит. Соответственно данный символ может быть закодирован двумя байтами с использованием префикса 110 – для первого байта и 10 – для второго байта. Английские буквы слова Hello кодируются 1 байтом, а коды совпадают с кодами в таблице ASCII.
Основными преимуществами способа кодирования UTF-8 являются многообразие символов, которые могут быть закодированы, а также возможность кодирования переменным количеством бит, что позволяет сэкономить количество информации, передаваемое в канале связи.
Стандарт кодирования UTF-16
В феврале 2000 года опубликован документ RFC 2781, в котором закреплен стандарт UTF-16, позволяющий кодировать символы таблицы Юникод с помощью 16 или 32 битных значений. Символы с номерами 0-55295 и 57344-65535 кодируются с помощью 16 бит без изменений (без использования префиксов), а остальные символы, номера которых в двоичном представлении формируются количеством бит больше 16, кодируются 32 битами с использованием специального алгоритма. Рассмотрим пример кодирования фразы «Папа Hello».
Код в бинарном виде (старший бит справа):
11111000 00100000 (П) 00001100 001000000 (а) 11111100 00100000 (п) 00001100 001000000 (а) 00000100 00000000 (пробел) 00010010 00000000 (H) 10100110 00000000 (e) 00110110 00000000 (l) 00110110 00000000 (l) 111110110 00000000 (o).
Номера букв русского и английского алфавитов таблицы Юникод передаются без изменений при помощи 16 бит, старшие незначащие биты принимают нулевое значение.
Рассмотрим подробнее алгоритм кодирования символов, номера которых превышают значение 65535.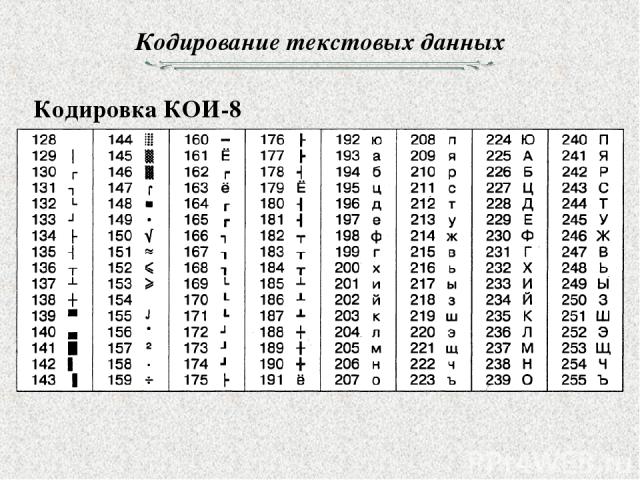 Для примера в качестве символа используем букву древнетюркского алфавита, представленную на рис.2:
Для примера в качестве символа используем букву древнетюркского алфавита, представленную на рис.2:
Номер предложенного символа в таблице Юникод – 68620 (0х10COC).
Алгоритм преобразования номера символа в код UTF-16 состоит из нескольких шагов:
Из значения номера символа вычесть число 0х10000. Данная операция позволяет привести размерность бинарного представления номера символа к 20 битам. Для предложенного символа получим: 0х10COC – 0x10000 = 0xC0C.
Для полученного значения выделить старшие 10 бит и младшие 10 бит. В примере число 0хС0С в бинарном виде представляется, как 00000000110000001100, где жирным выделены 10 старших бит, а подчеркиванием – 10 младших.
К шестнадцатеричному значению 0xD800 (11011000 00000000) прибавить значение 0х03 (00000000 00000011), сформированное 10 старшими битами, полученными на предыдущем шаге. 0xD800 + 0х03 = 0хD803 (11011000 00000011) – 16 старших бит кодового слова UTF-16.

К шестнадцатеричному значению 0xDC00 (11011000 00000000) прибавить значение 0х0C (00000000 00001100), сформированное 10 младшими битами, полученными на шаге №2. 0xDС00 + 0х0С = DС0С (11011100 00001100) – 16 младших бит кодового слова UTF-16.
Кодовое слово UTF-16, соответствующее символу в примере, формируется из бит, полученных на шагах 3 и 4: 0хD803DC0C (11011000 00000011 11011100 00001100).
Сравнение стандартов UTF-8 и UTF-16 с точки зрения объема машинной памяти, используемой кодом для представления символов
Результаты сравнения стандартов представлены в таблице 1.
Таблица 1. Результаты сравнения стандартов.
Диапазон номеров | 0-127 | 128 — 2047 | 2048-32767 | 32768-65535 | 65535- 1048575 | 1048575-… |
UTF-8 | 8 | 16 | 24 | 32 | 32 | _ |
UTF-16 | 16 | 16 | 16 | 16 | 32 | 32 |
В ячейках таблицы 1 содержится количество бит, требуемое для кодирования одного символа из таблицы Юникод. Видно, что для диапазонов номеров ячеек 128-2047, 65535-1048575 стандарты UTF-8 и UTF-16 используют одинаковое количество бит. Для диапазона 0-127 выгодно использование стандарта UTF-8, например, в случае, если программисту поручили реализовать кодер букв английского алфавита. Для диапазонов 2048-32767 и 32768-65535 выгодно использование стандарта UTF-16, например, в случае, если программисту поручили реализовать кодер иероглифов Бопомофо (занимают в таблице Юникод диапазон ячеек 12549-12589). Кодирование символов таблицы Юникод, расположенных в ячейках, номера которых начинаются от 1048575 возможно только с использованием кодировки UTF-16.
Видно, что для диапазонов номеров ячеек 128-2047, 65535-1048575 стандарты UTF-8 и UTF-16 используют одинаковое количество бит. Для диапазона 0-127 выгодно использование стандарта UTF-8, например, в случае, если программисту поручили реализовать кодер букв английского алфавита. Для диапазонов 2048-32767 и 32768-65535 выгодно использование стандарта UTF-16, например, в случае, если программисту поручили реализовать кодер иероглифов Бопомофо (занимают в таблице Юникод диапазон ячеек 12549-12589). Кодирование символов таблицы Юникод, расположенных в ячейках, номера которых начинаются от 1048575 возможно только с использованием кодировки UTF-16.
В предыдущих главах приведены примеры кодирования фразы «Папа Hello» стандартами UTF-8 и UTF-16. Кодировкой UTF-8 используются 14 байт, кодировкой UTF-16 20 байт, что связано с избыточностью кодирования англоязычных символов во втором случае из-за использования дополнительного байта 0х00. Можно сделать вывод, что для кодирования текста содержащего набор букв русского и английского алфавитов, предпочтительно использование кодировки UTF-8.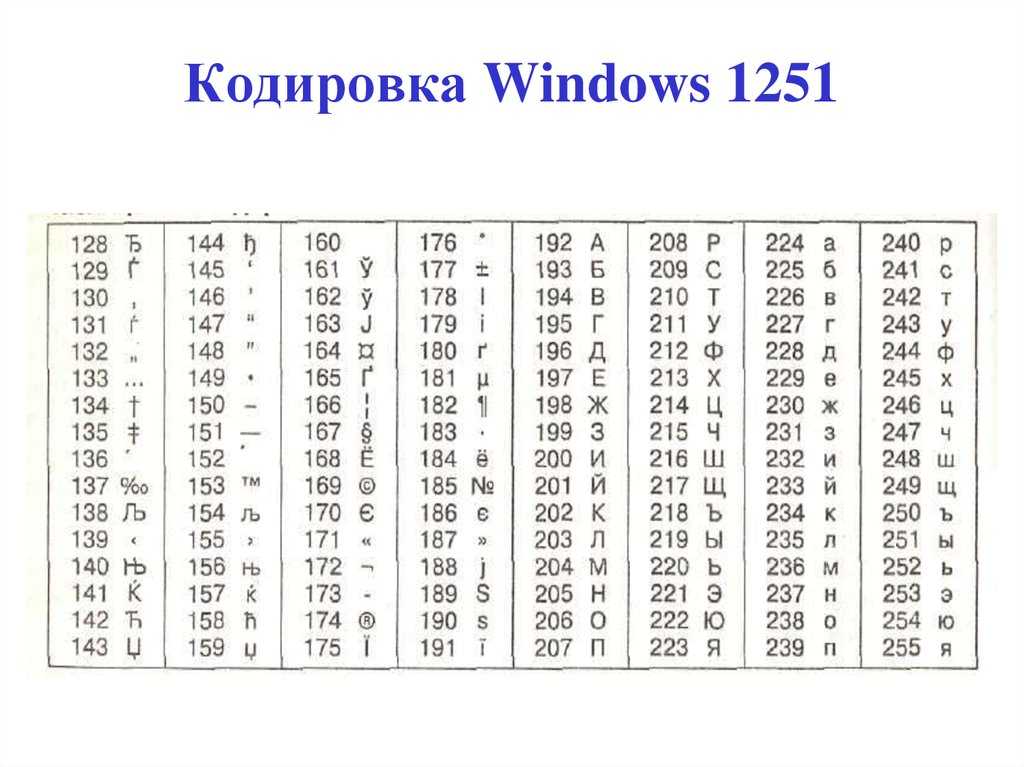
Вывод: в зависимости от языка алфавита может быть выбрана как кодировка UTF-8, так и кодировка UTF-16. Для английского алфавита однозначно более выгодно использование кодировки UTF-8, для русского алфавита буквы представляются одинаковым количеством бит при использовании как одной, так и другой кодировки.
Несколько советов программистам
Допустим, программист решил реализовать текстовый редактор, поддерживающий алфавит языка Бопомофо. Символы данного языка располагаются в таблице Юникод в диапазоне 12549-12589 и, следовательно, программисту необходимо выбрать стандарт UTF-16 для кодирования. Предположим, что для ввода символов решено использовать программную клавиатуру, состоящую из кнопок, каждая из которых соответствует букве алфавита языка. Кнопки – объекты класса button. Нажатие пользователем на какую-либо из кнопок порождает событие, в результате которого приложению становится известен номер ячейки таблицы Юникод. Программисту рекомендуется:
1.Хранить в памяти приложения символы таблицы Юникод и номера ячеек, соответствующие только языкам, поддержка которых планируется в текстовом редакторе. Это уменьшит объем памяти, занимаемой приложением, а также повысит скорость его работы, сузив область поиска номера ячейки.
Это уменьшит объем памяти, занимаемой приложением, а также повысит скорость его работы, сузив область поиска номера ячейки.
2. При реализации приложения заранее выполнить преобразование всех номеров ячеек в их бинарные коды. Результат преобразования сохранить в файле, в формализованном виде. При загрузке приложения выполнить считывание в память номеров ячеек и их бинарных кодов UTF-16. Это позволит снизить вычислительную нагрузку приложения в ходе его работы.
3. Для хранения номеров ячеек и их бинарных кодов использовать объект класса, позволяющего осуществить это в виде ключ-значение, где ключ – номер ячейки, а значение – бинарный код. Классы, реализующие в языках программирования данный функционал, организуют работу таким образом, чтобы минимизировать время поиска ключа, используя сортировку ключей или хеширование.
Отметим проблему кодирования составных символов, которая является важным техническим аспектом. Например, символ ü может быть интерпретирован, как самостоятельный символ, которому соответствует номер ячейки 252 или может быть скомпонован из двух символов: u, которому соответствует номер ячейки 117 и символа ¨, которому соответствует номер ячейки 776. Программист должен строго придерживаться одного из вариантов представления таких символов иначе побайтовое сравнение строк будет невозможно. Рекомендуется использование второго варианта, который может облегчить поиск составных символов в тексте. Например, если пользователь осуществляет поиск символа u, то ему может быть выведен в качестве результата, как составной символ ü, так и самостоятельный u.
Программист должен строго придерживаться одного из вариантов представления таких символов иначе побайтовое сравнение строк будет невозможно. Рекомендуется использование второго варианта, который может облегчить поиск составных символов в тексте. Например, если пользователь осуществляет поиск символа u, то ему может быть выведен в качестве результата, как составной символ ü, так и самостоятельный u.
Подготовка к ЕГЭ по информатике. Разбор задач раздела А
[назад]
1. Автоматическое устройство осуществило перекодировку информационного сообщения на русском языке первоначально записанного в 16-битном коде Unicode,в 8-битную кодировку КОИ-8. При этом информационное сообщение уменьшилось на 480 бит. Какова длина сообщения в символах?
1)30 2)60 3)120 4)480
Для начала вспомним, чем отличается кодировка КОИ-8 от
кодировки Unicode. Как явствует из
условия, кодировка КОИ-8 является 8-битной, т.е. позволяет
закодировать 2 в восьмой степени символов, т.е. 256. Кодировка
Unicod 16-битная, т.е. позволяет
закодировать 2 в 16 степени символов, т.е. 65536.
Как явствует из
условия, кодировка КОИ-8 является 8-битной, т.е. позволяет
закодировать 2 в восьмой степени символов, т.е. 256. Кодировка
Unicod 16-битная, т.е. позволяет
закодировать 2 в 16 степени символов, т.е. 65536.
Поскольку информационный объем символа в кодировке Unicod в два раза больше чем в кодировке КОИ-8, то получается, что изначально информационный объем сообщения был 960 бит (в кодировке Unicod), а стал 480 бит (в кодировке КОИ-8). Осталось объем всего сообщения разделить на информационный объем символа в кодировке КОИ-8, 480/8=60.
Ответ: 60 символов.
2. В велокроссе участвуют 119 спортсменов.
Специальное устройство регистрирует прохождение каждым из
участников промежуточного финиша, записывая его номер с
использованием минимально возможного количества бит, одинакового
для каждого спортсмена.
1)70 бит 2)70 байт 3)490 бит 4)119 байт
В условии задачи подразумевается, что «специальное устройство» записывает информацию в двоичной системе счисления. Используя формула N=2i (обратная формула Хартли), найдем i (кол-во необходимых бит) при которой N будет равна или больше 119. Получается, необходимо 7 бит, что дает 128 вариантов (6 бит будет мало, т.к. это даст только 64 варианта). Соответственно, для записи номера одного спортсмена потребуется 7 бит. Поскольку промежуточный финиш прошли 70 велосипедистов, то информационный объем сообщения составит 70*7 бит=490 бит.
Ответ: 490 бит.
3. Дано а=D716, b=3318. Какое из чисел c, записанных в двоичной системе, отвечает
условию a<c<b?
Какое из чисел c, записанных в двоичной системе, отвечает
условию a<c<b?
1)11011001 2)11011100 3)11010111 4)11011000
Поскольку задачи на системы счисления будут встречаться несколько раз, имеет смысл держать перед собой знакомую таблицу.
Таблица 1.
| Десятичная | Двоичная | Восьмеричная | Шестнадцатеричная |
| 0 | 0 | 0 | 0 |
| 1 | 1 | 1 | 1 |
| 2 | 10 | 2 | 2 |
| 3 | 11 | 3 | 3 |
| 4 | 100 | 4 | 4 |
| 5 | 101 | 5 | 5 |
| 6 | 110 | 6 | 6 |
| 7 | 111 | 7 | 7 |
| 8 | 1000 | 10 | 8 |
| 9 | 1001 | 11 | 9 |
| 10 | 1010 | 12 | A |
| 11 | 1011 | 13 | B |
| 12 | 1100 | 14 | С |
| 13 | 1101 | 15 | D |
| 14 | 1110 | 16 | E |
| 15 | 1111 | 17 | F |
| 16 | 10000 | 20 | 10 |
Как известно из школьного курса информатики, перевод между
системами счисления, основания которых являются степенями числа
2 (двоичная, восьмеричная, шестнадцатеричная), может
производиться по более простым алгоритмам нежели перевод между
десятичной системой счисления и другими.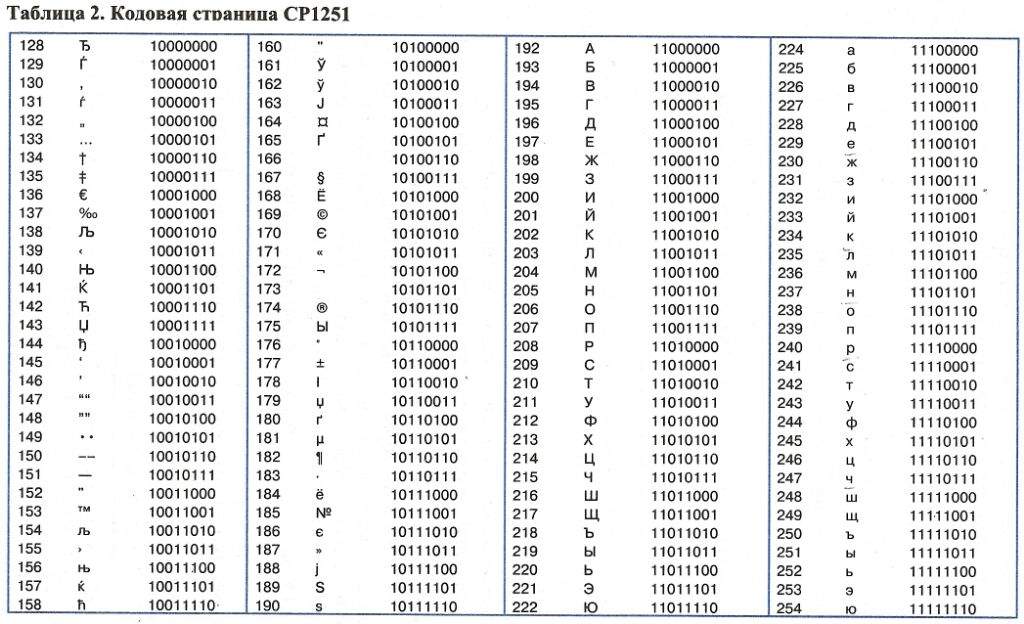
Переведем шестнадцатеричное число D7 в двоичную систему счисления. Первоначально находим по таблице какое двоичное число соответствует шестнадцатеричной цифре D — это 1101, теперь находим по таблице, что соответствует шестнадцатеричной цифре 7 — это 111. Поскольку двоичные цифры при переводе из шестнадцатеричной системы надо записывать в виде тетрад (четверок), подставляем слева вместо недостающих цифр нули, т.е. в место 111 получаем 0111. Итак, результат D7
Теперь аналогичным образом переводим в двоичную систему счисления восьмеричное число 331, только в этом случае надо записывать двоичные цифры в виде триад (троек), также дописывая слева при необходимости нули. Получаем 3=011, 3=011, 1=001, 3318=110110012.

Ответ:11011000.
4. Для кодирования букв А, Б, В, Г решили использовать двухразрядные последовательные двоичные числа (от 00 до 11, соответственно). Если таким способом закодировать последовательность символов БАВГ и записать результат шестнадцатеричным кодом, то получится
1)4B 2)411 3)BACD 4)1023
Из условия задачи следует, что буквы кодируются следующим образом: А-00, Б-01, В-10, Г-11. Теперь записываем последовательность БАВГ заменяем буквы двоичными числами: 01001011. Разбиваем последовательность чисел на тетрады 0100 и 1011. Согласно таблицы 1, определяем, что двоичное число 0100 соответствует шестнадцатеричной цифре 4, а 1011 соответствует B.
Ответ: 4B.
[назад]
unicode.
 Если UTF-8 является 8-битной кодировкой, зачем ей 1-4 байта?
Если UTF-8 является 8-битной кодировкой, зачем ей 1-4 байта?Просто дополняю другой ответ о кодировании UTF-8 , в котором используется от 1 до 4 байтов
Как уже говорилось выше, код с 4 байтами составляет 32 бита, но из этих 32 бит 11 бит используются как префикс в управляющих байтах, т. е. для определения размера кода символа Unicode между 1 и 4 байтами, а также позволяет легко восстановить текст даже в середине текста.
Золотой вопрос: зачем нам столько битов ( 11 ) для управления в 32-битном коде? Разве не было бы полезно иметь более 21 бит для кодирования?
Дело в том, что запланированная схема должна быть такой, чтобы было легко известно, что она вернется к 1-му. кусок кода.
Таким образом, байты, кроме первого байта, не могут иметь все свои биты, освобожденные для кодирования символа Unicode, поскольку в противном случае их можно было бы легко спутать с первым байтом действительного кода UTF-8 .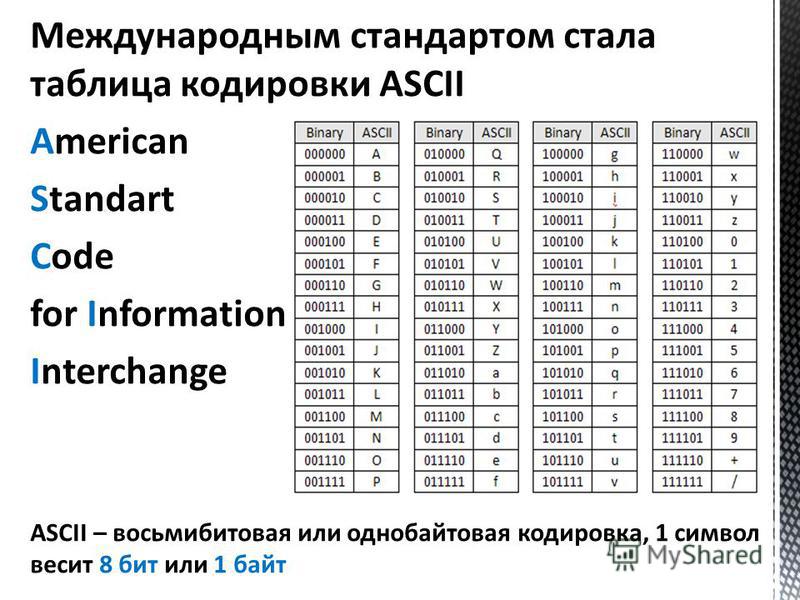
Значит модель 921 = 2 097 152 — 65 536 = 2 031 616 возможностей,
, где U — бит 0 или 1, используемый для кодирования символа Unicode UTF-8 .
Всего возможно 127 + 1 921 + 63 488 + 2 031 616 = 2 097 152 символов Unicode.
В доступных таблицах Unicode (например, в приложении Unicode Pad для Android или здесь) отображается код Unicode в форме ( U+H ), где H — шестнадцатеричное число от 1 до 6 цифр. Например U+1F680 представляет собой значок ракеты: 🚀.
Этот код преобразует биты
U кода символа справа налево (21 в 4 байта, 16 в 3 байта, 11 в 2 байта и 7 в 1 байт), сгруппированные в байтах, и с неполным байтом на осталось завершенным с 0s. Ниже мы попытаемся объяснить, зачем нужно иметь 11 бит управления. Часть сделанного выбора была просто случайным выбором между 0 и 1 , которому не хватает рационального объяснения.
Так как 0 используется для обозначения однобайтового кода, то 0 .... всегда эквивалентны коду ASCII из 128 символов (обратная совместимость)
Для символов, использующих более 1 байта, 10 в начале 2-го, 3-го. и 4-й. байт всегда служит для того, чтобы знать, что мы находимся в середине кода.
Чтобы устранить путаницу, если первый байт начинается с 11 , это означает, что 1-й. byte представляет собой символ Unicode с кодом из 2, 3 или 4 байтов. С другой стороны, 10 представляет собой средний байт, то есть он никогда не инициирует кодификацию символа Unicode. (Очевидно, что префикс для байтов продолжения не может быть 1 , потому что 0... и 1... исчерпывают все возможные байты)
Если бы не было правил для неначального байта, было бы очень неоднозначно.
При таком выборе мы знаем, что первый бит начального байта начинается с 0 или 11 , который никогда не путается со средним байтом, начинающимся с 9.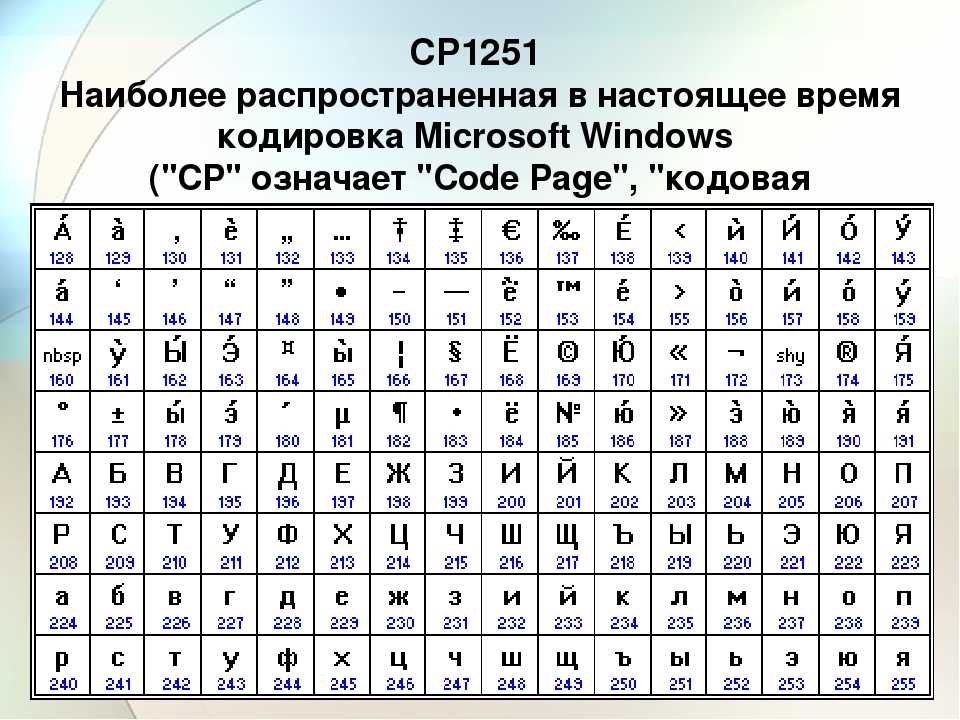 0026 10 . Просто глядя на байт, мы уже знаем, является ли он символом ASCII , началом последовательности байтов (2, 3 или 4 байта) или байтом из середины последовательности байтов (2, 3 или 4 байта).
0026 10 . Просто глядя на байт, мы уже знаем, является ли он символом ASCII , началом последовательности байтов (2, 3 или 4 байта) или байтом из середины последовательности байтов (2, 3 или 4 байта).
Возможен и противоположный выбор: префикс 11 может указывать на средний байт, а префикс 10 на начальный байт в коде с 2, 3 или 4 байтами. Этот выбор является просто вопросом соглашения.
Также на выбор 3-й. бит 0 от 1-го. байт означает 2 байта кода UTF-8 и 3-й. бит 1 1-й. байт означает 3 или 4 байта кода UTF-8 (опять же, нельзя использовать префикс ’11’ для 2-байтового символа, он также исчерпал бы все возможные байты: 0... , 10... и 11. .. ).
Итак, 4-й бит требуется в 1-м. байт различать 3 или 4 байта кодировки Unicode UTF-8.
4-й бит с 0 для 3-байтового кода и 1 для 4-байтового кода, который по-прежнему использует дополнительный бит 0 поначалу в этом не было бы необходимости.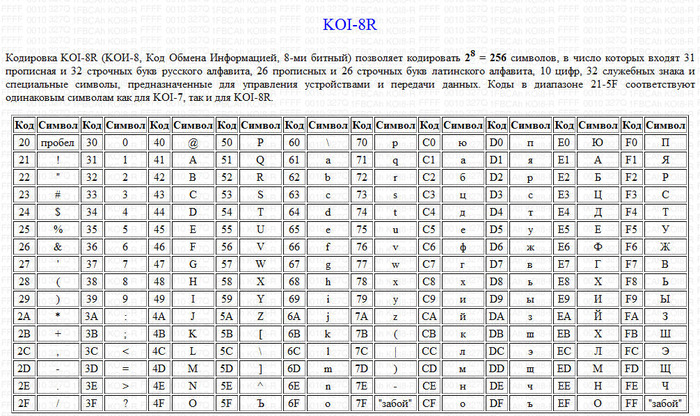
Одна из причин, помимо красивой симметрии ( 0 всегда является последним битом префикса в начальном байте), для наличия дополнительного 0 в качестве 5-го бита в первом байте для 4-байтового символа Unicode, заключается в чтобы сделать неизвестную строку почти распознаваемой как UTF-8, потому что нет ни одного байта в диапазоне от 11111000 до 11111111 ( F8 до FF или 248 до 921 = 2 097 152 возможностей, но только 1 112 064 из них являются действительными символами Unicodes ( 21 , потому что осталось 3 + 6 + 6 + 6 = 21 битов для кодирования символов UTF-8 и 5 + 2 + 2 + 2 = 11 бит в качестве префикса)
Как мы видели, не все возможности с 21 битами используются ( 2 097 152 ). Далеко не так (всего 1 112 064 ). Так что экономия на одном бите не приносит ощутимой пользы.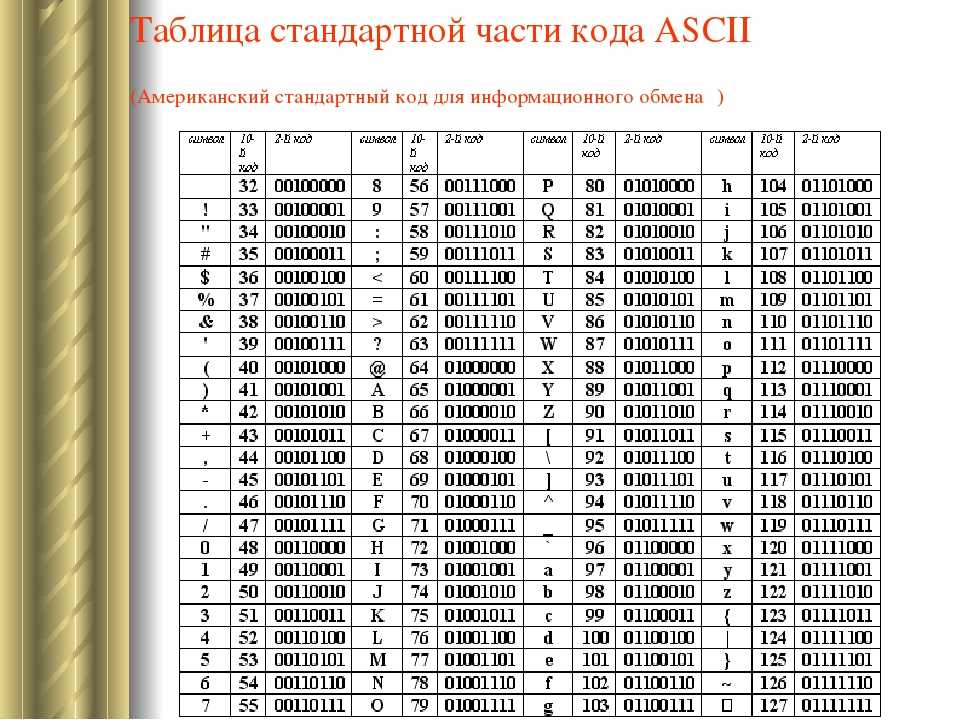
Другой причиной является возможность использования этих неиспользуемых кодов для функций управления вне мира Unicode.
электронная почта — кодирование передачи контента 7-битное или 8-битное
Это может быть немного сложно читать, но в разделе «Content-Transfer-Encoding» RFC 1341 есть все подробности:
http://www.w3 .org/Protocols/rfc1341/5_Content-Transfer-Encoding.html
Ситуация становится все хуже и хуже. Вот мое резюме:
SMTP, по определению (RFC 821), ограничивает почту строками из 1000 символов по 7 бит каждая. Это означает, что ни один из байтов, которые вы отправляете по каналу, не может иметь самый старший («самый старший») бит, установленный в «1».
Контент, который мы хотим отправить, часто не подчиняется этому ограничению по своей сути. Подумайте о файле изображения или текстовом файле, содержащем символы Unicode: байты этих файлов часто имеют 8-й бит, равный «1». SMTP не позволяет этого, поэтому вам нужно использовать «кодирование передачи», чтобы описать, как вы работали с несоответствием.
Значения заголовка Content-Transfer-Encoding описывают правило, которое вы выбрали для решения этой проблемы.
7bit просто означает «Мои данные состоят только из символов US-ASCII, которые используют только младшие 7 бит для каждого символа». Вы в основном гарантируете, что все байты в вашем контенте уже соответствуют ограничениям SMTP, и поэтому они не нуждаются в специальной обработке. Вы можете просто прочитать его как есть.
Обратите внимание: когда вы выбираете 7bit , вы соглашаетесь с тем, что все строки вашего контента имеют длину менее 1000 символов.
Пока ваш контент соответствует этим правилам, 7bit — лучшая кодировка для передачи, так как не требуется дополнительной работы; вы просто читаете/записываете байты, когда они выходят из канала. Также легко увидеть содержимое 7bit и понять его смысл. Идея здесь в том, что если вы просто пишете «простым английским текстом», все будет в порядке. Но это было не так в 2005 году и не так сегодня.
8 бит означает «Мои данные могут включать расширенные символы ASCII; они могут использовать 8-й (старший) бит для обозначения специальных символов, не входящих в стандартные 7-битные символы US-ASCII». Как с 7bit , по-прежнему существует ограничение в 1000 символов.
8bit , точно так же, как 7bit , на самом деле не выполняет никаких преобразований байтов, когда они записываются или считываются с сети. Это просто означает, что вы не гарантируете, что ни в одном из байтов старший бит не будет установлен в «1».
Кажется, это шаг вперед по сравнению с 7bit , поскольку он дает вам больше свободы в вашем контенте. Тем не менее, RFC 1341 содержит этот лакомый кусочек:
.На момент публикации этого документа не существует стандартизированных интернет-транспортов, для которых разрешено включать незакодированные 8-битные или двоичные данные в тело почты.
RFC 1341 вышел более 20 лет назад. С тех пор мы получили 8-битные расширения MIME в RFC 6152. Но даже тогда могут применяться ограничения на количество строк:
.Обратите внимание, что это расширение НЕ устраняет возможность ограничения длины строки SMTP-сервером; серверы могут свободно реализовывать это расширение, но, тем не менее, устанавливают предел длины строки не ниже 1000 октетов.
двоичный такой же, как 8-битный , за исключением того, что нет ограничений на длину строки. Вы по-прежнему можете включать любые символы, какие хотите, и нет дополнительной кодировки. Похоже на 8bit , RFC 1341 утверждает, что это не совсем законное кодирование передачи кодирования. RFC 3030 расширил это с помощью BINARYMIME .
До расширения 8BITMIME требовался способ отправки контента, который не мог бы быть 7-битным по SMTP. HTML-файлы (которые могут содержать строки длиной более 1000 символов) и файлы с международными символами являются хорошими примерами этого. Для этого предназначена кодировка с кавычками-печатью (определенная в разделе 5.1 RFC 1341). Он делает две вещи:
- Определяет, как экранировать символы, отличные от US-ASCII, чтобы они могли быть представлены только 7-битными символами. (Короткая версия: они отображаются как знак равенства плюс два 7-битных символа.)
- Определяет, что длина строк не должна превышать 76 символов, а разрывы строк будут представлены специальными символами (которые затем экранируются).
Quoted Printable из-за экранирования и коротких строк читать человеку гораздо труднее, чем 7bit или 8bit , но поддерживает гораздо более широкий спектр возможного контента.
Если ваши данные в основном нетекстовые (например, файл изображения), у вас не так много вариантов. 7bit исключен из таблицы.
Leave A Comment